
在 SQL 中经常会使用JOIN操作来组合两个或多个表。有很多种不同种类的 JOINS操作,并且pandas 也提供了这些方式的实现来轻松组合 Series 或 DataFrame。
SQL语句提供了很多种JOINS 的类型:
- 内连接
- 外连接
- 全连接
- 自连接
- 交叉连接
在本文将重点介绍自连接和交叉连接以及如何在 Pandas DataFrame 中进行操作。
自连接
顾名思义,自连接是将 DataFrame 连接到自己的连接。也就是说连接的左边和右边都是同一个DataFrame 。自连接通常用于查询分层数据集或比较同一 DataFrame 中的行。
示例 1:查询分层 DataFrame
假设有以下表,它表示了一家公司的组织结构。manager_id 列引用employee_id 列,表示员工向哪个经理汇报。
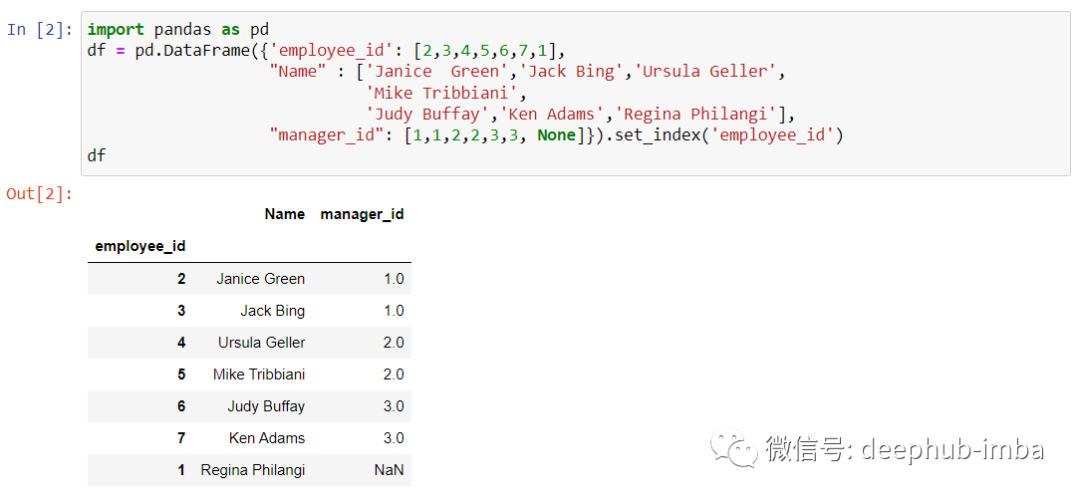
要获取员工向谁汇报的姓名,可以使用自连接查询表。

我们首先将创建一个新的名为 df_managers的 DataFrame,然后join自己。在join时需要删除了第二个df_managers的 manager_id,这样才不会报错。要获取经理的信息所以使用 how = 'left'。进行左链接,如果没有这个经理则会得到 NaN,最后就是重命名列。
最终输出如下所示。Regina Philangi 没有经理,这意味着她不向任何一位经理汇报。她是最高管理者。
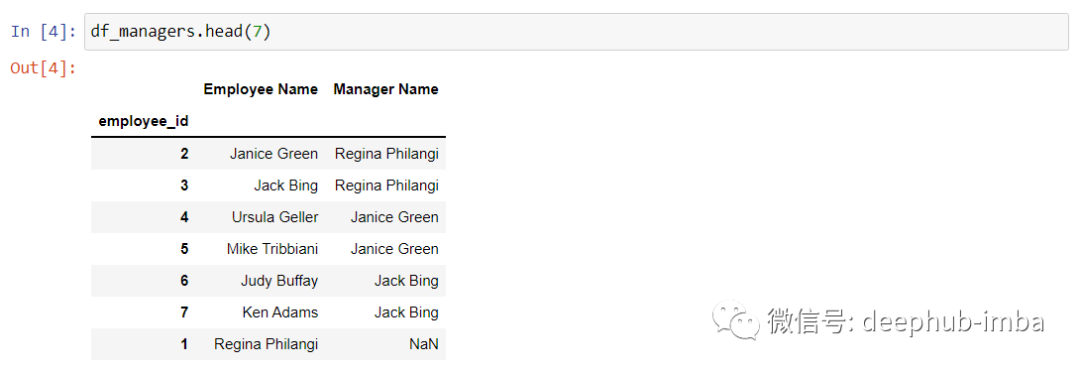
注:如果我们想排除Regina Philangi ,可以使用内连接"how = 'inner'"
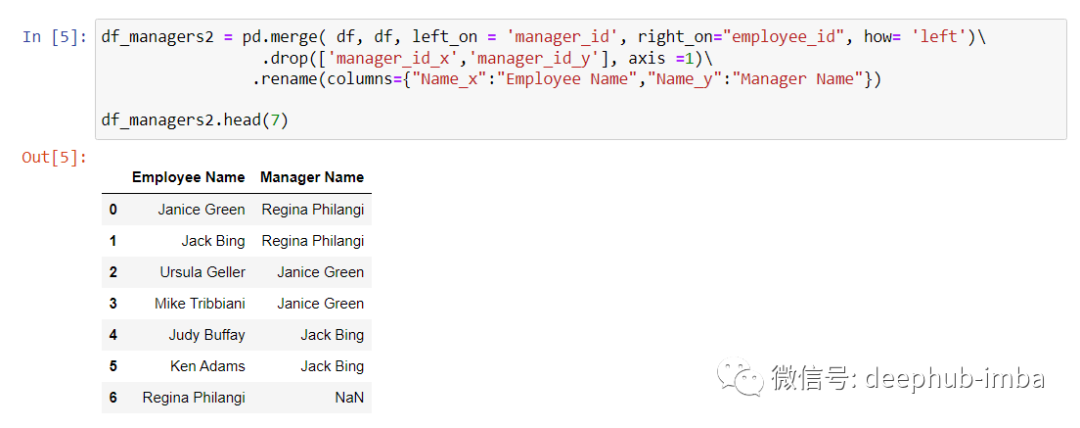
我们也可以使用 pandas.merge () 函数在 Pandas 中执行自连接,如下所示。df_manager2 的输出与 df_manager 相同。
交叉连接
交叉连接也是一种连接类型,可以生成两个或多个表中行的笛卡尔积。它将第一个表中的行与第二个表中的每一行组合在一起。下表说明了将表 df1 连接到另一个表 df2 时交叉连接的结果。

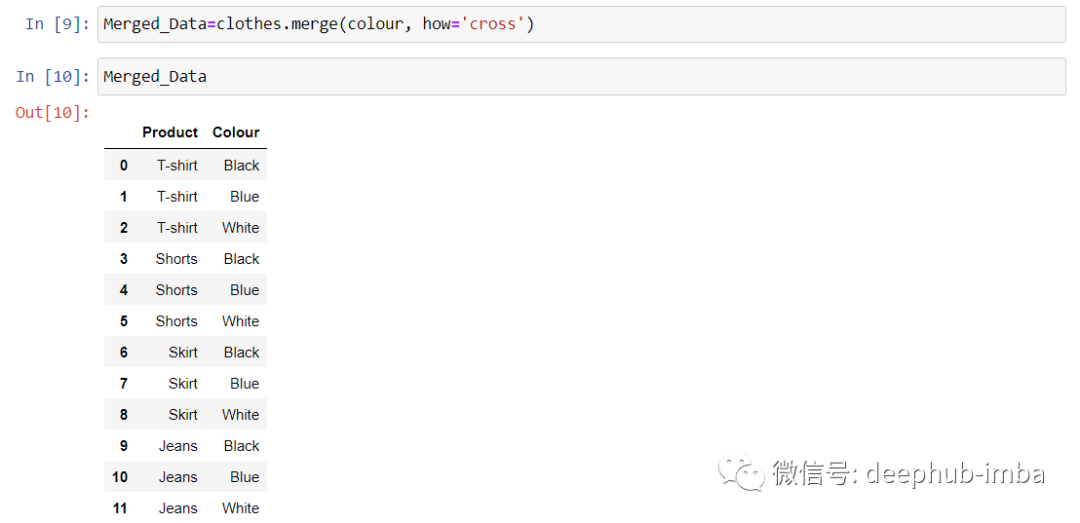
示例 2:创建产品的库存
此示例的目标是获取服装店的库存,可以通过任意的SKU(这里是颜色)获得组合。

这个示例数据种两个 DataFrame 都没有索引所以使用 pandas.merge() 函数很方便。
也可以使用 pandas.concat () 函数,与 pandas.merge () 函数相同的结果。

总结
在本文中,介绍了如何在Pandas中使用连接的操作,以及它们是如何在 Pandas DataFrame 中执行的。这是一篇非常简单的入门文章,希望在你处理数据的时候有所帮助。