
Deephub
更多文章请关注公众号:Deephub-IMBA
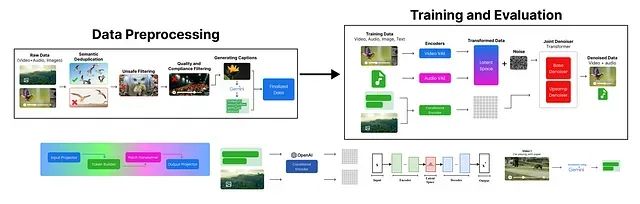
从零复现Google Veo 3:从数据预处理到视频生成的完整Python代码实现指南
本文详细介绍了一个简化版 Veo 3 文本到视频生成模型的构建过程。首先进行了数据预处理,涵盖了去重、不安全内容过滤、质量合规性检查以及数据标注等环节。
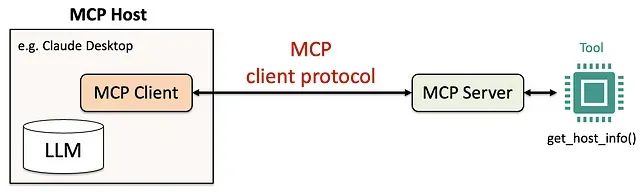
Python构建MCP服务器完整教程:5步打造专属AI工具调用系统
本文通过实际的代码示例和详细的配置步骤,展示了使用Python和Anthropic的mcp库构建MCP服务器的完整过程。我们从工具函数的设计开始,逐步介绍了MCP服务器的构建、AI代理的配置以及功能测试的验证方法。
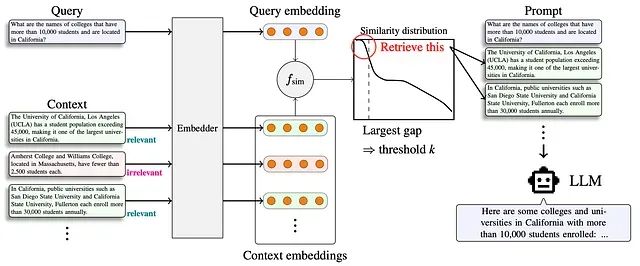
Adaptive-k 检索:RAG 系统中自适应上下文长度选择的新方法
Adaptive-k 代表了 RAG 系统从固定检索向智能化、查询感知检索的技术范式转变。该技术实现了显著的效率提升——在保持或提高准确性的同时,token 减少高达 99%。
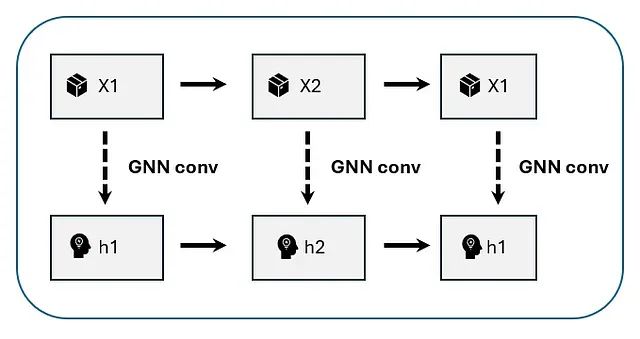
基于时间图神经网络多的产品需求预测:跨序列依赖性建模实战指南
本文展示了如何通过学习稀疏影响图、应用图卷积融合邻居节点信息,并结合时间卷积捕获演化模式的完整技术路径,深入分析每个步骤的机制原理和数学基础。
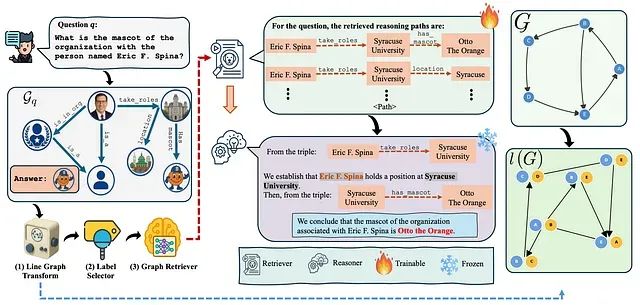
解决RAG检索瓶颈:RAPL线图转换让知识图谱检索准确率提升40%
本文深入探讨RAPL(Retrieval-Augmented Path Learning)框架,这是一个创新的人工智能架构,通过线图转换和合理化监督技术,从根本上改进了知识图谱环境下的检索增强生成系统。

ProRL:基于长期强化学习让1.5B小模型推理能力超越7B大模型
这个研究挑战了强化学习仅能放大现有模型输出能力的传统观点,通过实验证明长期强化学习训练(ProRL)能够使基础模型发现全新的推理策略。

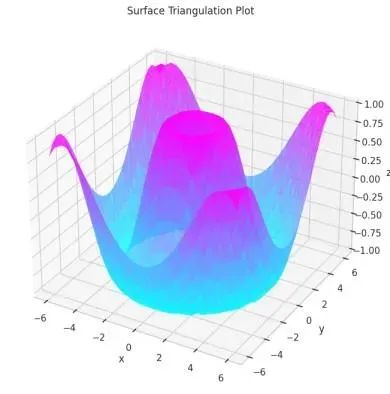
Python 3D数据可视化:7个实用案例助你快速上手
本文详细介绍了 Python 中基于 Matplotlib 库的七种核心三维数据可视化技术,从基础的线性绘图和散点图到高级的曲面建模和三角剖分方法。
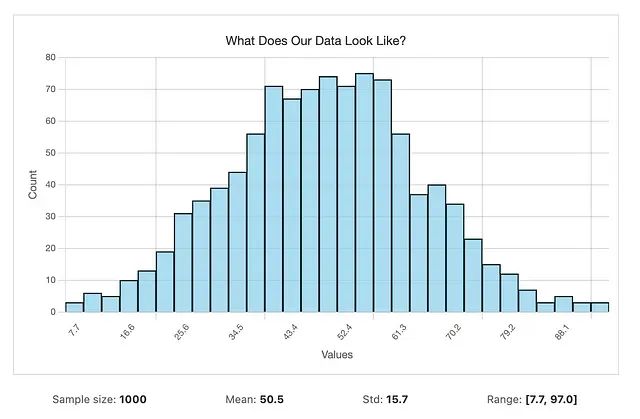
数据分布不明确?5个方法识别数据分布,快速找到数据的真实规律
本文介绍的方法和工具涵盖了大多数实际应用场景的需求。从基础的直方图分析开始,逐步深入到参数化和非参数化的分布拟合,再到结果验证和实际应用,形成了完整的技术体系。
SnapViewer:解决PyTorch官方内存工具卡死问题,实现高效可视化
SnapViewer项目通过重新设计数据处理流水线和渲染架构,成功解决了PyTorch官方内存可视化工具的性能瓶颈问题。
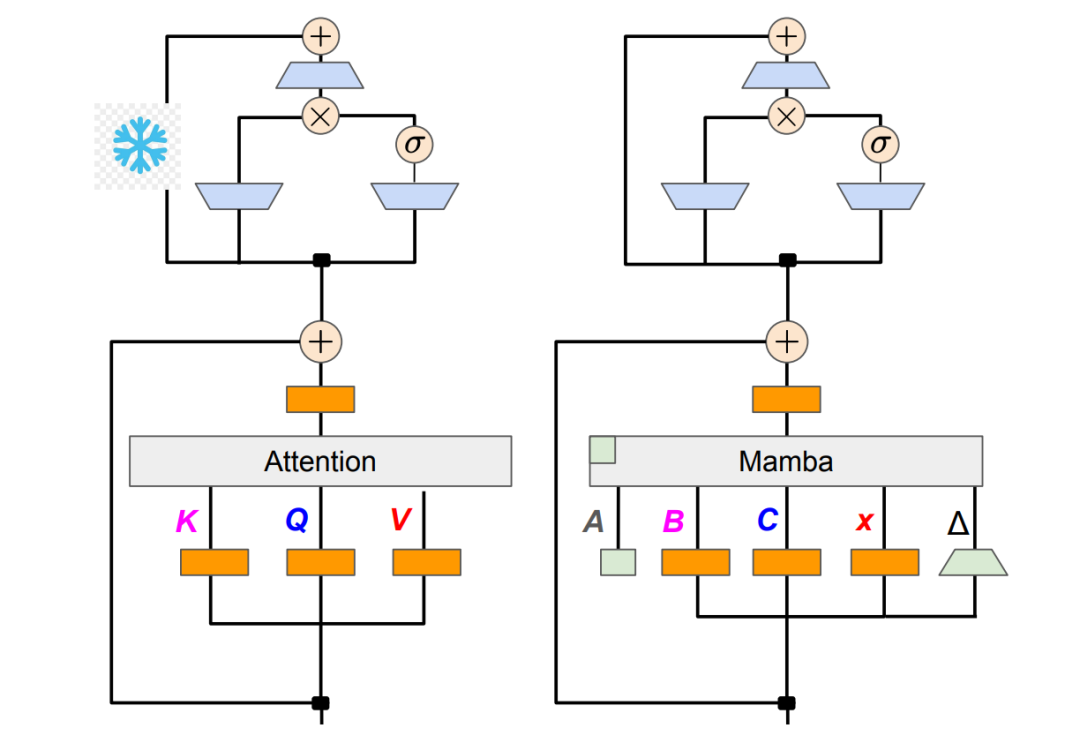
提升长序列建模效率:Mamba+交叉注意力架构完整指南
本文将深入分析Mamba架构中交叉注意力机制的集成方法与技术实现。
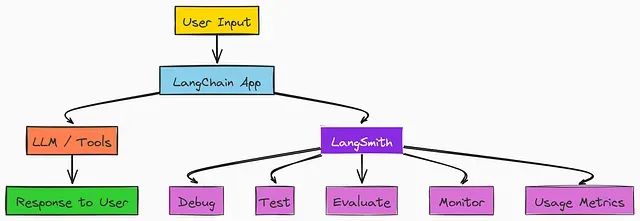
LangGraph实战教程:构建会思考、能记忆、可人工干预的多智能体AI系统
在本文中,我们将使用监督者方法构建一个多智能体系统。在此过程中,我们将介绍基础知识、在创建复杂的 AI 智能体架构时可能面临的挑战,以及如何评估和改进它们。
DROPP算法详解:专为时间序列和空间数据优化的PCA降维方案
*DROPP (Dimensionality Reduction for Ordered Points via PCA) 是一种专门针对有序数据的降维方法。本文将详细介绍该算法的理论基础、实现步骤以及在降维任务中的具体应用。*
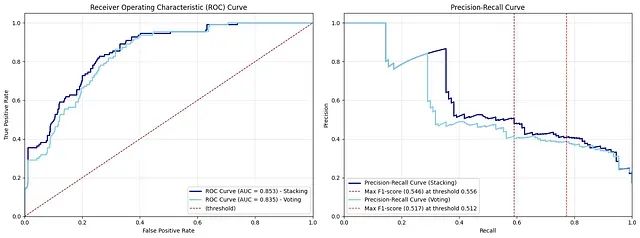
朴素贝叶斯处理混合数据类型,基于投票与堆叠集成的系统化方法理论基础与实践应用
本文深入探讨朴素贝叶斯算法的数学理论基础,并重点分析其在处理混合数据类型中的应用。

提升模型泛化能力:PyTorch的L1、L2、ElasticNet正则化技术深度解析与代码实现
本文将深入探讨L1、L2和ElasticNet正则化技术,重点关注其在PyTorch框架中的具体实现。关于这些技术的理论基础,建议读者参考相关理论文献以获得更深入的理解。
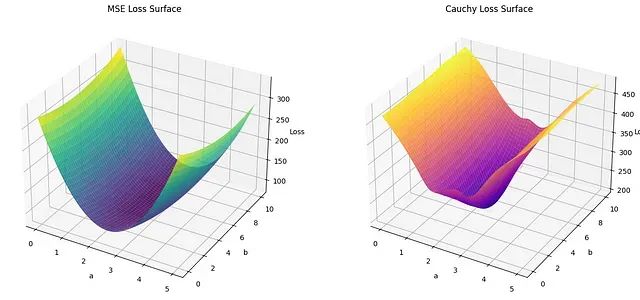
让回归模型不再被异常值"带跑偏",MSE和Cauchy损失函数在噪声数据环境下的实战对比
本文通过实证研究,系统比较了MSE损失函数和Cauchy损失函数在线性回归中的表现,重点分析了两种损失函数在噪声数据环境下的差异。
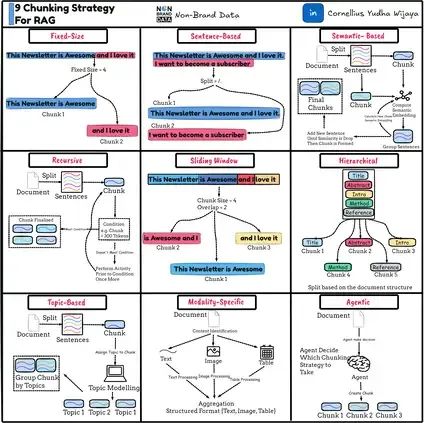
RAG系统文本分块优化指南:9种实用策略让检索精度翻倍
本文将深入分析九种主要的文本分块策略及其具体实现方法。下图概括了我们将要讨论的内容。
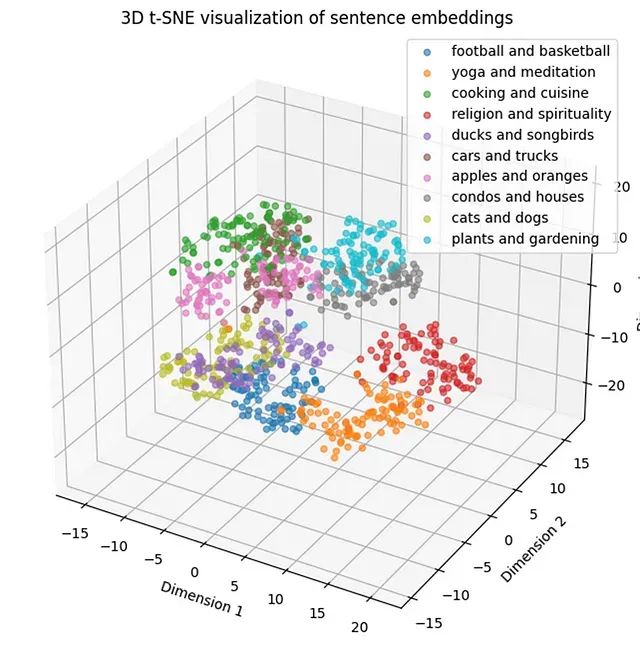
文本聚类效果差?5种主流算法性能测试帮你找到最佳方案
本文讨论的算法代表了工业界最广泛应用且具有实际应用价值的聚类方法,除了谱聚类在句子嵌入领域的应用价值有限之外。

BayesFlow:基于神经网络的摊销贝叶斯推断框架
**BayesFlow** 是一个开源 Python 库,专门设计用于通过**摊销(Amortization)神经网络**来**加速和扩展贝叶斯推断**的能力。该框架通过训练神经网络来学习逆问题(从观测数据推断模型参数)或正向模型(从参数生成观测数据)的映射关系,
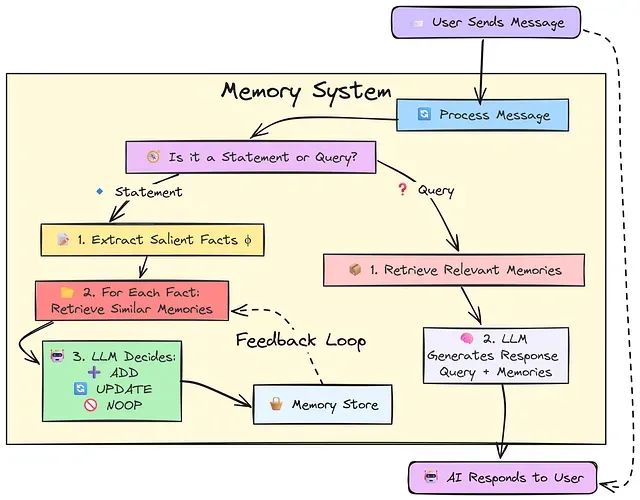
基于内存高效算法的 LLM Token 优化:一个有效降低 API 成本的技术方案
该方法的核心原理基于一个关键洞察:LLM 并非需要对每次用户输入都生成回复,而应当区分用户的信息陈述和实际查询请求,仅在后者情况下生成响应。