
视觉语言模型(Vision Language Model,VLM)正在改变计算机对视觉和文本信息的理解与交互方式。本文将介绍 VLM 的核心组件和实现细节,可以让你全面掌握这项前沿技术。我们的目标是理解并实现能够通过指令微调来执行有用任务的视觉语言模型。
总体架构
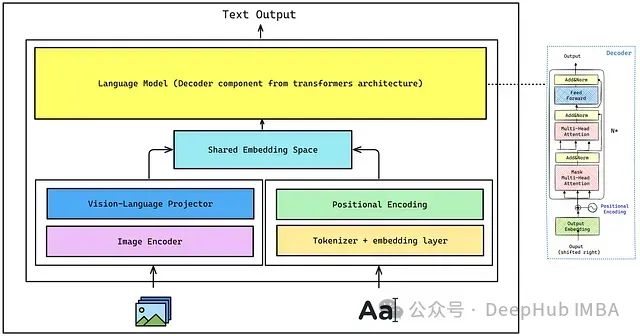
VLM 的总体架构包括:
- 图像编码器(Image Encoder):用于从图像中提取视觉特征。本文将从 CLIP 中使用的原始视觉 Transformer。
- 视觉-语言投影器(Vision-Language Projector):由于图像嵌入的形状与解码器使用的文本嵌入不同,所以需要对图像编码器提取的图像特征进行投影,匹配文本嵌入空间,使图像特征成为解码器的视觉标记(visual tokens)。这可以通过单层或多层感知机(MLP)实现,本文将使用 MLP。
- 分词器和嵌入层(Tokenizer + Embedding Layer):分词器将输入文本转换为一系列标记 ID,这些标记经过嵌入层,每个标记 ID 被映射为一个密集向量。
- 位置编码(Positional Encoding):帮助模型理解标记之间的序列关系,对于理解上下文至关重要。
- 共享嵌入空间(Shared Embedding Space):将文本嵌入与来自位置编码的嵌入进行拼接(concatenate),然后传递给解码器。
- 解码器(Decoder-only Language Model):负责最终的文本生成。
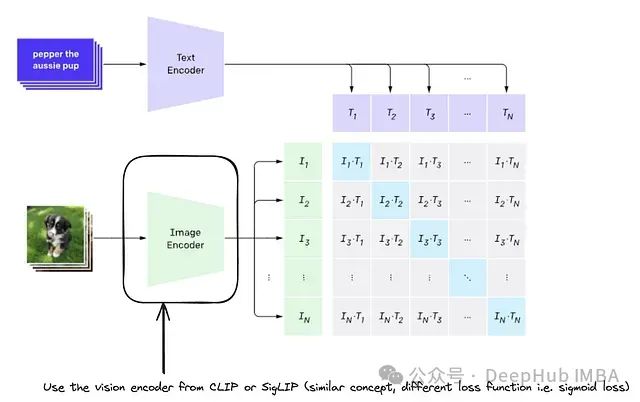
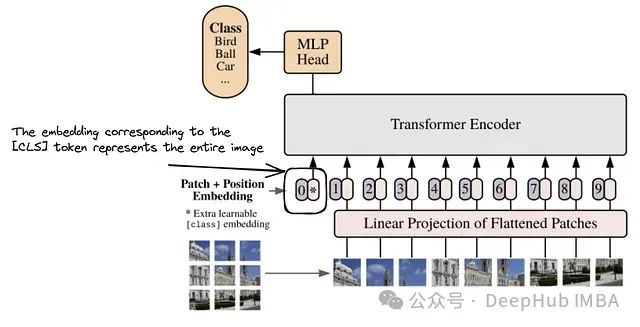
上图是来自CLIP 论文的方法示意图,主要介绍文本和图片进行投影
综上,我们使用图像编码器从图像中提取特征,获得图像嵌入,通过视觉-语言投影器将图像嵌入投影到文本嵌入空间,与文本嵌入拼接后,传递给自回归解码器生成文本。
VLM 的关键在于视觉和文本信息的融合,具体步骤如下:
- 通过编码器提取图像特征(图像嵌入)。
- 将这些嵌入投影以匹配文本的维度。
- 将投影后的特征与文本嵌入拼接。
- 将组合的表示输入解码器生成文本。
深度解析:图像编码器的实现
图像编码器:视觉 Transformer
为将图像转换为密集表示(图像嵌入),我们将图像分割为小块(patches),因为 Transformer 架构最初是为处理词序列设计的。
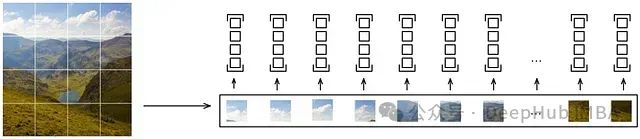
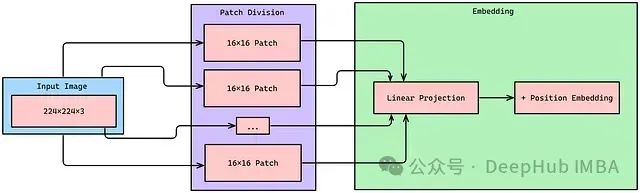
为从零开始实现视觉 Transformer,我们需要创建一个 PatchEmbeddings 类,接受图像并创建一系列小块。该过程对于使 Transformer 架构能够有效地处理视觉数据至关重要,特别是在后续的注意力机制中。实现如下:
classPatchEmbeddings(nn.Module):
def__init__(self, img_size=96, patch_size=16, hidden_dim=512):
super().__init__()
self.img_size=img_size
self.patch_size=patch_size
self.num_patches= (img_size//patch_size) **2
# 无重叠卷积用于提取小块
self.conv=nn.Conv2d(
in_channels=3,
out_channels=hidden_dim,
kernel_size=patch_size,
stride=patch_size
)
# 使用 Xavier/Glorot 初始化权重
nn.init.xavier_uniform_(self.conv.weight)
ifself.conv.biasisnotNone:
nn.init.zeros_(self.conv.bias)
defforward(self, X):
"""
参数:
X: 输入张量,形状为 [B, 3, H, W]
返回:
小块嵌入,形状为 [B, num_patches, hidden_dim]
"""
ifX.size(2) !=self.img_sizeorX.size(3) !=self.img_size:
raiseValueError(f"输入图像尺寸必须为 {self.img_size}x{self.img_size}")
X=self.conv(X) # [B, hidden_dim, H/patch_size, W/patch_size]
X=X.flatten(2) # [B, hidden_dim, num_patches]
X=X.transpose(1, 2) # [B, num_patches, hidden_dim]
returnX
在上述代码中,输入图像通过卷积层被分解为 (img_size // patch_size) ** 2 个小块,并投影为具有通道维度为 512 的向量(在 PyTorch 实现中,三维张量的形状通常为 [B, T, C])。
注意力机制
视觉编码器和语言解码器的核心都是注意力机制。关键区别在于解码器使用因果(掩码)注意力,而编码器使用双向注意力。以下是对单个注意力头的实现:
classHead(nn.Module):
def__init__(self, n_embd, head_size, dropout=0.1, is_decoder=False):
super().__init__()
self.key=nn.Linear(n_embd, head_size, bias=False)
self.query=nn.Linear(n_embd, head_size, bias=False)
self.value=nn.Linear(n_embd, head_size, bias=False)
self.dropout=nn.Dropout(dropout)
self.is_decoder=is_decoder
defforward(self, x):
B, T, C=x.shape
k=self.key(x)
q=self.query(x)
v=self.value(x)
[email protected](-2, -1) * (C**-0.5)
ifself.is_decoder:
tril=torch.tril(torch.ones(T, T, dtype=torch.bool, device=x.device))
wei=wei.masked_fill(tril==0, float('-inf'))
wei=F.softmax(wei, dim=-1)
wei=self.dropout(wei)
out=wei@v
returnout
视觉-语言投影器
投影器模块在对齐视觉和文本表示中起关键作用。我们将其实现为一个多层感知机(MLP):
classMultiModalProjector(nn.Module):
def__init__(self, n_embd, image_embed_dim, dropout=0.1):
super().__init__()
self.net=nn.Sequential(
nn.Linear(image_embed_dim, 4*image_embed_dim),
nn.GELU(),
nn.Linear(4*image_embed_dim, n_embd),
nn.Dropout(dropout)
)
defforward(self, x):
returnself.net(x)
综合实现
最终的 VLM 类将所有组件整合在一起:
classVisionLanguageModel(nn.Module):
def__init__(self, n_embd, image_embed_dim, vocab_size, n_layer,
img_size, patch_size, num_heads, num_blks,
emb_dropout, blk_dropout):
super().__init__()
num_hiddens=image_embed_dim
assertnum_hiddens%num_heads==0
self.vision_encoder=ViT(
img_size, patch_size, num_hiddens, num_heads,
num_blks, emb_dropout, blk_dropout
)
self.decoder=DecoderLanguageModel(
n_embd, image_embed_dim, vocab_size, num_heads,
n_layer, use_images=True
)
defforward(self, img_array, idx, targets=None):
image_embeds=self.vision_encoder(img_array)
ifimage_embeds.nelement() ==0orimage_embeds.shape[1] ==0:
raiseValueError("ViT 模型输出为空张量")
iftargetsisnotNone:
logits, loss=self.decoder(idx, image_embeds, targets)
returnlogits, loss
else:
logits=self.decoder(idx, image_embeds)
returnlogits
训练及注意事项
在训练 VLM 时,需要考虑以下重要因素:
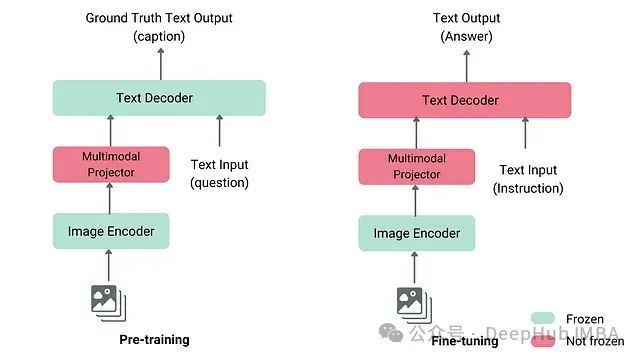
预训练策略:现代 VLM 通常使用预训练的组件:
- 视觉编码器:来自 CLIP 或 SigLIP
- 语言解码器:来自 Llama 或 GPT 等模型
- 投影器模块:初始阶段仅训练此模块
训练阶段:
- 阶段 1:在冻结的编码器和解码器下预训练,仅更新投影器
- 阶段 2:微调投影器和解码器以适应特定任务
- 可选阶段 3:通过指令微调提升任务性能
数据需求:
- 大规模的图像-文本对用于预训练
- 任务特定的数据用于微调
- 高质量的指令数据用于指令微调
总结
通过从零开始实现视觉语言模型(VLM),我们深入探讨了视觉和语言处理在现代人工智能系统中的融合方式。本文详细解析了 VLM 的核心组件,包括图像编码器、视觉-语言投影器、分词器、位置编码和解码器等模块。我们强调了多模态融合的关键步骤,以及在实现过程中需要注意的训练策略和数据需求。
构建 VLM 不仅加深了我们对视觉和语言模型内部机制的理解,还为进一步的研究和应用奠定了基础。随着该领域的迅速发展,新的架构设计、预训练策略和微调技术不断涌现。我们鼓励读者基于本文的实现,探索更先进的模型和方法,如采用替代的视觉编码器、更复杂的投影机制和高效的训练技术,以推动视觉语言模型的创新和实际应用。
作者:Achraf Abbaoui