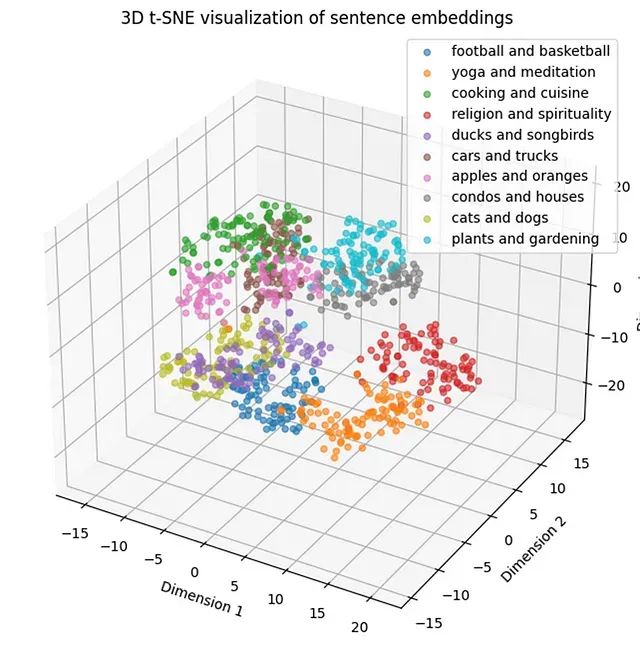
文本聚类效果差?5种主流算法性能测试帮你找到最佳方案
本文讨论的算法代表了工业界最广泛应用且具有实际应用价值的聚类方法,除了谱聚类在句子嵌入领域的应用价值有限之外。
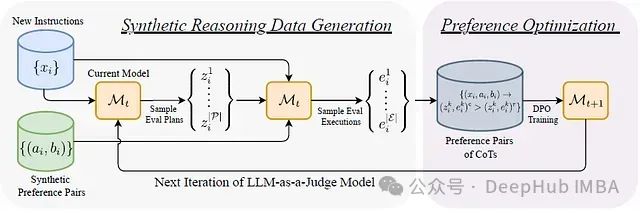
EvalPlanner:基于“计划-执行”双阶段的大语言模型评估框架
EvalPlanner[1],这是一种创新的LLM评估算法。该算法采用计划-执行的双阶段范式,首先生成无约束的评估计划,随后执行该计划并做出最终判断。这种方法显著提升了评估过程的系统性和可靠性。
【AI知识点】词袋模型(Bag-of-Words,BOW)
词袋模型(Bag-of-Words,简称BOW)是一种用于文本表示的简单且常用的方法,尤其在自然语言处理(NLP)和信息检索领域中广泛应用。词袋模型的核心思想是将文本表示为一个词频统计的集合,而不考虑词的顺序和语法结构。每个词在文本中出现的频率被用来表示文本的特征。
Chatbox AI + grok-beta大模型秒杀GPT4.0(部署属于您自己的本地AI大语言模型聊天系统)
马斯克X-AI发布Grok 2大模型,效果秒杀GPT4.0!Grok支持超长文本上下文,普通人也能轻松上手,免费使用!部署属于您自己的本地AI大语言模型聊天系统.
GPTZero:高效识别AI生成文本,保障学术诚信与内容原创性
GPTZero 是一款先进的AI文本检测工具,专为识别由大型语言模型(如ChatGPT、GPT-4、Bard等)生成的文本而设计。它通过分析文本的复杂性和一致性,判断文本是否可能由人类编写。其核心优势在于快速和高效的检测能力,能够在几秒钟内对多达50,000个字符的文本进行AI生成内容的检测,为用户
广西民族大学高级人工智能课程—头歌实践教学实践平台—机器翻译--English to Chinese
广西民族大学高级人工智能课程—头歌实践教学实践平台—机器翻译--English to Chinese
人工智能--自然语言处理简介
此外,现在有许多利用 NLP 的服务来创建应用程序,比如聊天机器人(它们属于应用,属于Agent应用开发),但这些内容不在知识的范围之内——我们将专注于 NLP 的基础知识(实现原理),以及如何进行语言建模,使您可以训练神经网络,教导电脑去理解和分类文本。在 NLP 的情况下,您的训练数据中可能包含
多轮对话中让AI保持长期记忆的8种优化方式篇
在多轮对话中,AI保持长期记忆的优化方式包括:获取全量历史对话、滑动窗口获取最近部分对话内容、获取历史对话中实体信息、利用知识图谱获取实体及其联系、对历史对话进行阶段性总结摘要、兼顾最新对话和较早历史对话、回溯最近和最关键的对话信息、基于向量检索对话信息。这些方法在不同场景中应用,如客服、商品咨询、
人工智能——大语言模型
Transformer模型是由谷歌团队在2017年发表的论文所提出。这篇论文的主体内容只有几页,主要就是对下面这个模型架构的讲解。5.3.2. 自注意力机制传输的RNN用于处理系列时,会增加一个隐藏状态用来记录上一个时刻的序列信息。在处理翻译文本时,一个字的意思可能和前面序列的内容相关,通过隐藏状态
语音合成技术:AI如何模仿人类声音
语音合成技术:AI如何模仿人类声音大家好,我是Shelly,一个专注于输出AI工具和科技前沿内容的AI应用教练,体验过300+款以上的AI应用工具。关注科技及大模型领域对社会的影响10年+。关注我一起驾驭AI工具,拥抱AI时代的到来。
复制下来就能跑:Java智能问答系统-介绍与代码实践 - 基于springboot_springai_国产大模型
智能问答系统是一种人工智能应用,它能够理解用户提出的问题,并通过自然语言处理技术来分析和理解问题的含义。随后,系统会在其知识库中搜索相关信息,以生成一个或多个可能的答案。这些答案基于系统对问题的理解和知识库中的信息生成。自然语言处理(NLP):这是系统的核心部分,负责理解用户的输入。NLP 涉及分词
Windows电脑本地部署llamafile并接入Qwen大语言模型远程AI对话实战
Windows电脑本地部署llamafile并接入Qwen大语言模型远程AI对话实战
掩码语言模型(Masked Language Model,简称MLM)
掩码语言模型(MLM)是一种自监督学习技术,它不需要显式的注释或标签,而是利用输入文本本身作为监督信号。在MLM任务中,输入文本的一部分单词会被随机掩盖(或替换为特殊的[MASK]标记),模型的目标是根据剩余的上下文信息来预测这些被掩盖的单词。这种机制迫使模型在训练过程中深入理解单词的上下文以及它们
Cofounder:全栈 AI 应用开发 Agent,基于单一提示生成完整的应用程序
Cofounder 是一个开源的全栈 AI 开发代理,帮助开发者自动生成完整的应用程序,包括后端、前端、数据库和有状态的 Web 应用。
拥抱AI未来:Hugging Face平台使用指南与实战技巧
Huggingface总部位于纽约,是一家专注于自然语言处理、人工智能和分布式系统的创业公司。他们所提供的聊天机器人技术一直颇受欢迎,但更出名的是他们在NLP开源社区上的贡献。Huggingface一直致力于自然语言处理NLP技术的平民化(democratize),希望每个人都能用上最先进(SOTA
Ollama:实现本地AI大语言模型命令行启动的专业部署方案
Ollama是一个强大的开源框架,专为在本地机器上便捷地部署和运行大型语言模型(LLM)而设计。
论文分享|ACMMM2024‘北航|利用大模型扩充正负例提升组合图像检索的对比学习性能
博主的第一篇一作论文:如何利用LLM的助力在组合图像检索任务达到sota
探索 Meta AI 的多模态语言模型 Spirit LM:融合语音与文本的创新应用
Spirit LM 是 Meta AI 开发的多模态语言模型,无缝集成语音和文本数据,具备跨模态生成、语义表达和少量样本学习能力,应用于语音助手、ASR、TTS 等场景。
【AI大模型】ELMo模型介绍:深度理解语言模型的嵌入艺术
ELMo是2018年3月由华盛顿大学提出的一种预训练模型.ELMo的全称是Embeddings from Language Models.ELMo模型的提出源于论文。
【面试】解释一下什么是人工智能中的黑箱问题
1.1 什么是黑箱?在人工智能中,黑箱指的是那些内部机制对用户或开发者而言不可见或难以理解的系统或模型。对于黑箱模型,我们可以观察其输入和输出,但模型内部如何处理这些输入并得出输出的过程是复杂且不透明的。例如,一个深度神经网络在图像分类任务中,可以高效地将一张图像分类为“猫”或“狗”,但是人们很难解



