
刚发布的最新版本怎么用?YOLOv13新手教程带你快速上手
本文将详细介绍YOLOv13的完整实现流程,涵盖数据集准备、模型训练、验证评估以及实际应用等关键环节。
【YOLOv5/v7改进系列】引入中心化特征金字塔的EVC模块
为了解决这个问题,作者提出了CFP,它首先在最深层的特征图上应用显式视觉中心方案,然后利用这些信息去调整较浅层的特征图。完成二后,在YOLOv7项目文件下的models文件夹下创建新的文件yolov7-tiny-evc.yaml,导入如下代码。完成二后,在YOLOv5项目文件下的models文件夹下
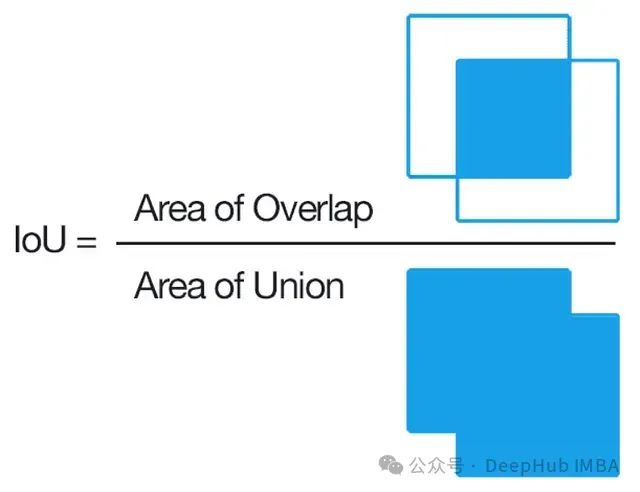
IoU已经out了,试试这几个变体:GIoU、DIoU和CIoU介绍与对比分析
GIoU、DIoU和CIoU这三个变体都有各自的独到之处,它们在一定程度上弥补了普通IoU在处理不重叠、距离较远或形状差异较大的边界框时的不足。
【猫狗数据集】宠物品种分类 计算机视觉 人工智能 机器学习 (含数据集)
宠物数据集,涵盖了各种猫和狗品种,包括阿比西尼亚猫、孟加拉猫、德国短毛指示犬、哈瓦那犬等。每张图像都经过精准标注,包含品种信息和位置数据。这个数据集不仅为研究提供了丰富的训练素材,也是深度学习模型的理想选择,旨在培养准确识别和分类各种宠物品种的算法。立即探索这个数据集,解锁宠物世界的无限可能!
Labelme AI 自动标注版使用说明【附下载链接】
Labelme 是一个开源的图像标注工具,主要用于机器学习和计算机视觉领域的数据集创建。能够帮助用户快速、方便地对图像进行标注,以便为训练模型提供高质量的数据。支持 jpg,jpeg,png,tif,tiff 图像格式,对图像进行多边形矩形、圆形、多段线、线段、点形式的标注,实现AI辅助标注,与手动
OMG-Seg:一个模型搞定所有分割任务的终极解决方案,大幅提升AI自动标注效率!
它采用了一种编码器-解码器架构,并使用任务特定的查询和输出来实现各种分割任务,显著简化了分割任务的部署。分割任务通常要求对图像或视频中的每个像素进行分类,传统上使用单独的模型来处理不同的分割任务,例如语义分割、实例分割、全景分割等。通过一个模型架构的多任务处理,OMG-Seg 展示了其在实际应用中的
【YOLOv5/v7改进系列】引入YOLOv9的RepNCSPELAN4
YOLOv9的几个主要创新点:Programmable Gradient Information (PGI):PGI是一种机制,用于应对深度网络中实现多目标所需要的多种变化。PGI提供完整的输入信息来计算目标函数,从而获得可靠的梯度信息以更新网络权重。PGI可以自由选择适合目标任务的损失函数,克服了
【YOLO5 项目实战】(3)PCB 缺陷检测
本文介绍通过 YOLOv5 对 PCB缺陷 进行实时检测。详细介绍(1)环境配置;(2)北大PCB缺陷数据集的处理;(3)使用YOLOv5 训练PCB缺陷模型;(4)使用训练的模型检测 PCB缺陷。
PP-Human行为识别(RTSP协议视频流实时检测)
用本地电脑的摄像头摄像并推流到RTSP服务器然后拉取视频流,利用PP-Human行为识别模块本地推理并将推理结果推流到RTSP服务器,最终通过 VLC 打开网络串流播放实时画面。
将 YOLOv10 部署至 LiteRT:在 Android 上使用 Google AI Edge 进行目标检测
点击下方卡片,关注“小白玩转Python”公众号介绍在大型语言模型(LLMs)兴起之前,边缘 AI 是一个热门话题,这得益于其在设备上直接运行机器学习模型的显著能力。这并不是说这个话题已经失去了相关性;事实上,许多科技巨头现在正将注意力转向在移动平台上部署 LLMs。虽然我们今天不会讨论生成性 AI
CVPR2024| 实时目标检测的变革:RT-DETR的突破性性能
实时目标检测领域一直由基于CNN的架构主导,YOLO检测器领先。然而,端到端的基于变换器的检测器(DETRs)的引入彻底改变了这一领域,尽管它们的计算成本很高。在本文中,作者介绍了实时检测变换器(RT-DETR),这是一个突破性的模型,不仅在速度和精度方面实现了最先进的(SOTA)性能,而且消除了传
RT-DETR: 实时目标检测的又一次进化
点击下方卡片,关注“小白玩转Python”公众号实时目标检测是一个具有广泛应用的关键领域,从物体跟踪到自动驾驶。想象一下,一辆能够实时检测行人和其他车辆的自动驾驶汽车,或一个可以同时跟踪多个移动物体的监控系统。这些系统的效率和准确性取决于其快速、准确地处理和分析视觉数据的能力。这就是实时目标检测的重
AI:297-深度优化YOLOv8小目标检测性能 | 基于自适应特征金字塔网络(AFPN)的创新改进策略
本文探讨了如何通过引入自适应特征金字塔网络(AFPN)来提升YOLOv8在小目标检测中的性能。AFPN通过对多尺度特征的精细化融合,增强了模型对不同尺度目标的感知能力,特别是对小目标的检测能力进行了有效提升。我们通过引入可学习权重参数和膨胀卷积等技术,进一步优化了AFPN结构,实验结果显示,结合这些
【Arxiv2023】Detect Everything with Few Examples
本文提出了小样本目标检测领域的SOTA方法DE-ViT,采用元学习训练框架。DE-ViT提出了一种新的区域传递机制用于检测框定位,并且提出了一种空间积分层来讲mask转化为检测框输出。DE-ViT相比之前的方法提升巨大,在COCO数据集上,10-shot提升15AP,30shot提升7.2AP。
AI:283-独创FRMHead| 超越YOLOv8与RT-DETR的下一代目标检测头
YOLO(You Only Look Once)系列是目标检测领域的佼佼者,其模型在精度和速度上不断取得突破。YOLOv8作为该系列的最新版本,已经在多个检测任务中展现了其强大的性能。然而,面对新兴的检测需求和挑战,我们需要进一步优化YOLOv8的检测头,以提升其检测精度和速度。本文将介绍一种全新的
AI:289-增强YOLOv8目标检测性能 | 通过EfficientNetV1改进特征提取层
EfficientNetV1的核心思想是通过均衡缩放(Compound Scaling)来优化网络结构。均衡缩放方法同时调整网络的深度、宽度和分辨率,以便在计算资源有限的情况下实现最佳性能。EfficientNetV1使用了一个高效的基本块——MBConv(Mobile Inverted Bottl
AI:295-深入改进YOLOv8小目标检测 | 基于Gold-YOLO的Neck结构优化与应用
在目标检测领域,YOLO (You Only Look Once) 系列凭借其实时性和高效性得到了广泛应用。然而,YOLO 在处理小目标检测时,往往表现出一定的局限性。为了解决这一问题,Gold-YOLO 提出了针对小目标检测的改进策略。本文将详细探讨如何利用 Gold-YOLO 的设计理念,优化
YOLOv8入门 | 从环境配置到代码拉取(下载)再到数据集划分又到实验运行
YOLOv8环境配置,数据集划分,启动命令
Segment-and-Track Anything配置以及使用说明
Segment-and-Track Anything视频分割超详教程
AI:285-YOLOv8改进深度解析 | DynamicHead检测头的原论文复现与性能评估
DynamicHead是YOLOv8中一个重要的改进组件,主要用于提高检测头的灵活性和适应性。该改进通过动态调整卷积核和特征图,从而更好地适应不同大小和形状的目标物体。DynamicHead的核心思想是根据输入图像的特征自适应地调整检测头的参数,以提高检测性能。



