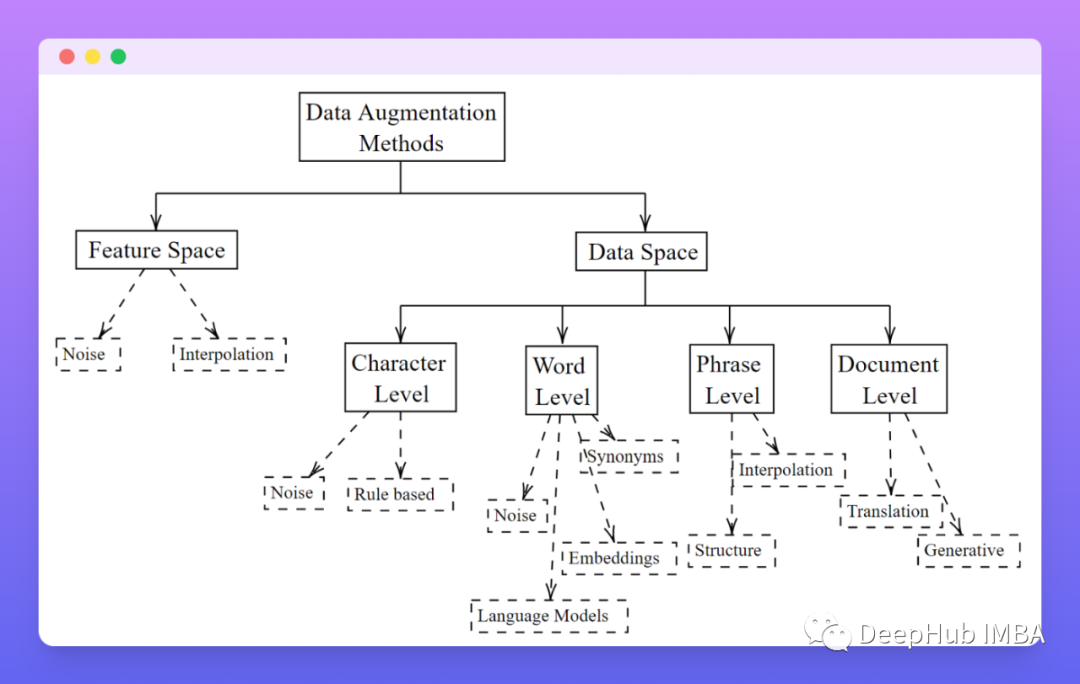
图解BERT、ELMo(NLP中的迁移学习)| The Illustrated BERT, ELMo, and co.
2018年是NLP模型发展的转折点。我们不断探索单词和句子的表示方法,以求能最好地捕捉其中潜在的语义和关系。此外,NLP领域已经提出了一些功能强大的组件,你可以免费下载,并在自己的模型和pipeline中使用它们(这被称为NLP领域的ImageNet时刻,类似的发展在几年前也是这么加速计算机视觉领域
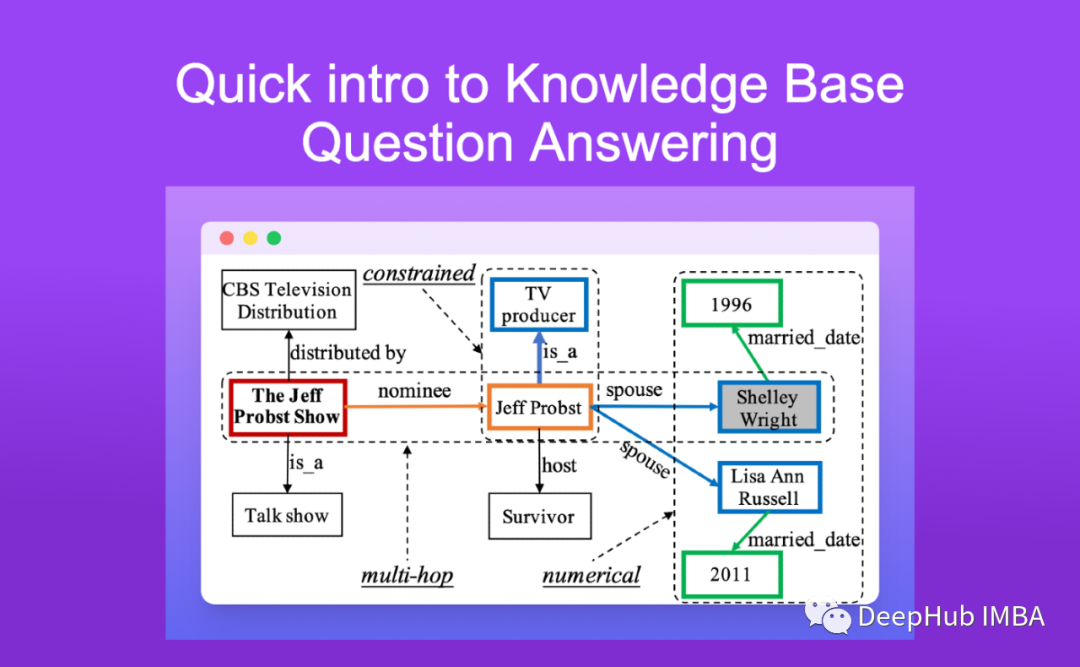
5分钟NLP-知识问答(KBQA)两种主流方法:基于语义解析和基于信息检索的方法介绍
基于知识的问答是以知识库为认知源,在知识库的基础上回答自然语言问题。在本文中讲介绍知识问答两种主要方法。
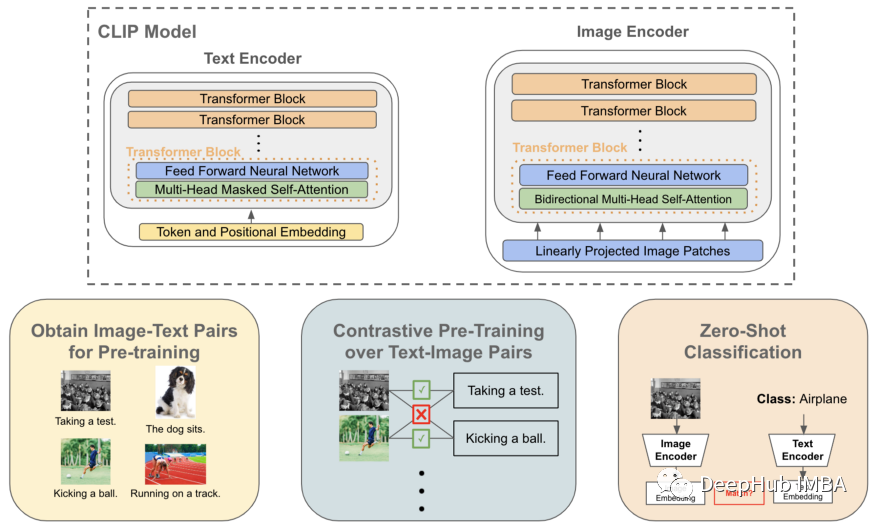
使用 CLIP 对没有标记的图像进行零样本无监督分类
OpenAI 提出的CLIP模型,不需要标签并且在 ImageNet 上实现 76.2% 的测试准确率,在这篇文章中将概述 CLIP 的信息,如何使用它来最大程度地减少对传统的监督数据的依赖,以及它对深度学习从业者的影响。
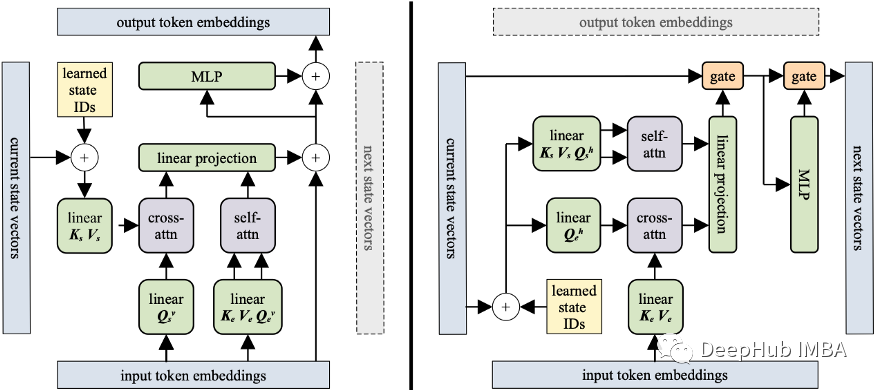
Block Recurrent Transformer:结合了LSTM和Transformer优点的强大模型
2022年3月Google研究团队和瑞士AI实验室IDSIA提出了一种新的架构,称为Block Recurrent Transformer 从名字中就能看到,这是一个新型的Transformer模型,它利用了lstm的递归机制,在长期序列的建模任务中实现了显著改进。
NLP下的bert模型的一些学习
学习NLP过程中的一些自己的笔记
详解机器翻译任务中的BLEU
BLEU的计算和Python的简单实现
分享本周所学——Transformer模型详解
大家好,欢迎来到《分享本周所学》第二期。本人是一名人工智能初学者,最近一周学了一下Transformer这个特别流行而且特别强大的模型,觉得非常有收获,就想用浅显易懂的语言让大家对这个超级神器有所了解。然后因为我也只是一名小白,所以有错误的地方还希望大佬们多多指正。 其实这周我还干了一

ArgMiner:一个用于对论点挖掘数据集进行处理、增强、训练和推理的 PyTorch 的包
对kaggle中Feedback Prize比赛该兴趣的小伙伴推荐了解下。ArgMiner可以用于对SOTA论点挖掘数据集进行标准化处理、扩充、训练和执行推断。
自然语言处理系列(二)——使用RNN搭建字符级语言模型
使用RNN搭建字符级语言模型——人名分类任务
自然语言处理系列(一)——RNN基础
注: 本文是总结性文章,叙述较为简洁,不适合初学者目录一、为什么要有RNN?二、RNN的结构三、RNN的分类四、Vanilla RNN的优缺点一、为什么要有RNN?普通的MLP无法处理序列信息(如文本、语音等),这是因为序列是不定长的,而MLP的输入层神经元个数是固定的。二、RNN的结构普通MLP的
再议LaMDA,它真的初具思想吗?
昨天,我关注的一个新闻,并仔细的阅读了原文,并对其进行了解读(因怀疑对话系统变成人而被带薪休假,我亲自看了看。)。今天看到很多讨论后,想从技术的角度谈一谈,它现在到底处于什么水平的AI。当然,很多人的结论就是,现在的LaMDA距离真正的AI还很远。而且作为工程师,应该多和人类接触,而不是和机器打交道
因怀疑对话系统变成人而被带薪休假,我亲自看了看。
今天被一个谷歌的对话系统LaMDA的新闻吸引到了,这个新闻大致是讲,谷歌研究员通过提交自己和AI的对话记录,试图让上司明白AI已经初具人格(即有人的意识)而被带薪休假。我关注的不是他为何被处理,我更希望的是去看看,这个可以令谷歌研究员走火入魔的AI到底达到了什么样的水平了,于是,我亲自去看了它的原版
机器学习和人工智能之间的区别
人工智能和机器学习都是计算机科学的术语。本文讨论了一些要点,我们可以根据这些要点区分这两个术语。概述AI(人工智能):人工智能一词由“人工”和“智能”两个词组成。人工是指由人类或非自然事物制造的东西,智能是指有理解或思考的能力。有一种误解认为人工智能是一个系统
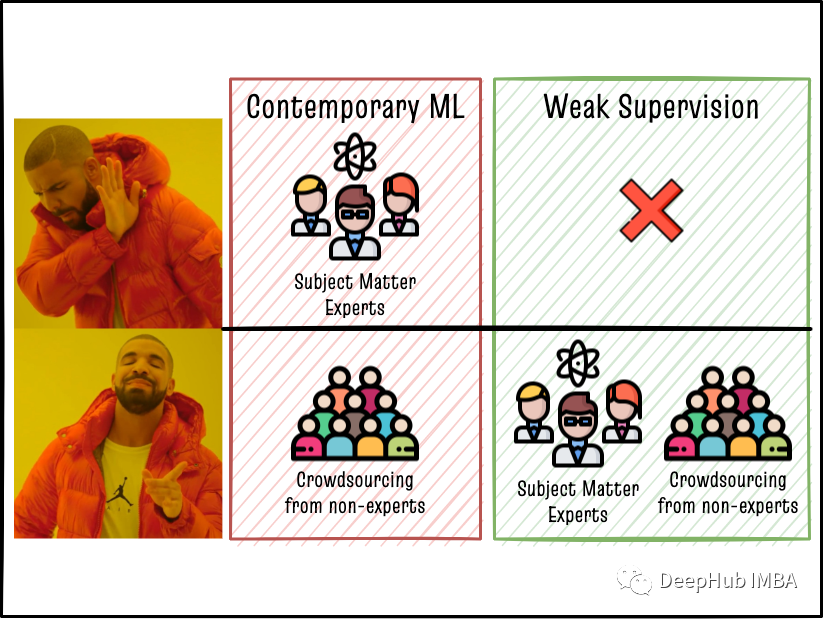
在没有训练数据的情况下通过领域知识利用弱监督方法生成NLP大型标记数据集
介绍了弱监督的概念,以及如何使用它来将专家的领域知识编码到机器学习模型中。我还讨论了一些标记模型。在两步弱监督方法中结合这些框架,可以在不收集大量手动标记训练数据集的情况下实现与全监督ML模型相媲美的准确性!
CSDN-NLP:基于技能树和弱监督学习的博文难度等级分类 (一)
目录1. 背景2. 方法2.1 规则:快速实现2.2 匹配:结构化知识体系2.3 分类:弱监督学习2.4 融合:各尽其能3. 总结与展望3.1 总结3.2 展望4. 参考团队博客: CSDN AI小组1. 背景CSDN 每天都会产生数以万计的博客数据,但是这些数据没有难度等级的体系结构,这种体系结构
NLP实战-基于弱标注数据的文本分类
本文介绍如何使用弱标注数据进行文本分类,基于CSDN文库下载标签分类场景进行介绍,使用特征选择的方法对弱标注的数据进行过滤,使弱标注的数据能用来进行模型训练。

微调大型语言模型示例:使用T5将自然语言转换成SQL语句
在本文中,我们将使用谷歌的文本到文本生成模型T5和我们的自定义数据进行迁移学习,这样它就可以将基本问题转换为SQL查询。
机器学习之自然语言处理——中文分词jieba库详解(代码+原理)
目录文本分类概述文本分类的应用文本分类的挑战文本分类的算法应用文本分类所需知识中文分词神器-jiebajieba分词的三种模式词性标注载入词典(不分词)词典中删除词语(不显示)停用词过滤调整词语的词频关键词提取基于TF-IDF算法的关键词提取基于 TextRank 算法的关键词抽取返回词语在原文的起
基于Sentence-Bert的检索式问答系统
文章目录前言一、pandas是什么?二、使用步骤1.引入库2.读入数据总结前言一、pandas是什么?示例:pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。二、使用步骤1.引入库代码如下(示例):import numpy as npimport pandas as