
文章目录
前言
常见的问答任务有四种:
- 知识图谱问答:基于给定知识图谱生成问题对应的答案
- 表格问答:基于给定表格集合生成问题对应的答案
- 文本问答:基于给定文本生成问题对应的答案
- 社区问答:基于从问答社区网站抓取的问答对进行问答任务
在
CSDN
主站,有个问答频道,为了降低用户重复提问率,我们需要根据用户正在提的问题,从问答库中,匹配出最相似的已采纳的问题的答案,推荐给用户。因此,这里我们要做的是社区问答任务。
问答对:问答社区网站上提供的
<问题, 答案>
对数据集合。
社区问答,具体来说,就是给定输入问题,社区问答从问答对中检索与输入问题语义最为匹配的已有问题,并采用该已有问题对应的答案作为当前问题的答案。由此可见,社区问答最关键的环节是计算问题和已有问题之间的语义相似度,以及计算问题和答案之间的语义相关度。
基本概念清楚后,进入正题:
环境
lightgbm==3.3.2
hnswlib==0.6.2
sentence_transformers==1.2.0
windows
上应该装不上
hnswlib
其他的缺啥装啥
构建数据集
在
CSDN
,有大量的无标注数据,但高质量的人工标注数据,少之又少。因此,我们这里也是使用无标注数据。但在构建数据的过程中,我们可以采取一些手段,将误差降到最小。
数据格式:
q_str
为
query
文本
doc_str
为
target
文本
同一行的数据,为相似数据。即我们可以将同一行的
<q_str, doc_str>
对作为正样本,不同行的
<q_str, doc_str>
对作为负样本。
接下来,我们需要对这些样本标注。这里我们使用
Sentence-Bert
的预训练模型来计算句向量,再计算皮尔逊系数,作为标签。
关于
Sentence-Bert
原理,可以直接查看原论文:Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
关于
Sentence-Bert
基本使用,可以查看官网 https://www.sbert.net/index.html
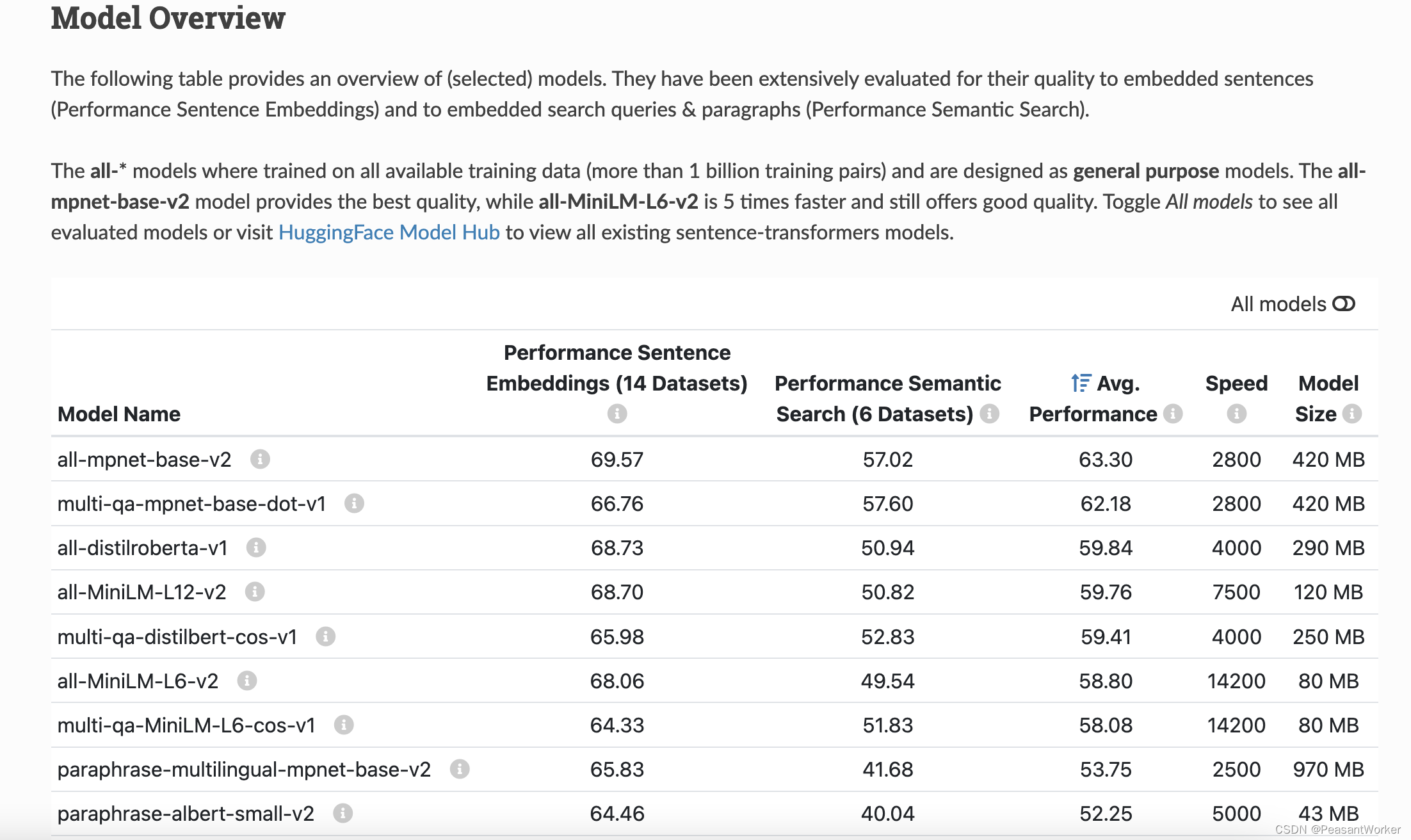
从官网可以看到,
all-mpnet-base-v2
是当前最好的模型,因此,我们在构建数据集时,可以选用效果最好的模型,
all-MiniLM-L6-v2
是当前较为均衡的模型,该模型占用内存小,推理速度快,且效果不差,因此,我们在部署到线上时,选用该模型作为基础模型来进行预训练。
构建
SentenceTransformer
训练数据:
defbuild_vector(index, data, model):
data_res =[]
count =0for idx, i inzip(
data.index,
data.loc[:,["qid","doc_id","q_str","doc_str"]].values,):
count+=1
logger.info(f"当前-----------{count}/{len(index)}-----------")
qid, doi, sa, sb = i
sav = model.encode(sa)
sbv = model.encode(sb)
sco, _ = pearsonr(sav, sbv)
l =min(max(0,(1+ sco)/2),1)
d = InputExample(texts=[sa, sb], label=l)
data_res.append(d)for n_idx in np.random.choice(index,1):if n_idx != idx andisinstance(sa,str)andisinstance(sb,str):
sb_n = data.loc[n_idx,"doc_str"]
sbnv = model.encode(sb_n)
sco, _ = pearsonr(sav, sbnv)
l =min(max(0,(0.3+ sco)/2),1)
dn = InputExample(texts=[sa, sb_n], label=l)
data_res.append(dn)return data_res
deftest_build_dataset(config, options):
dir_path ="./data/datasets/answer/sts_dset"
data_full_train, data_full_dev = load_dataset(dir_path=dir_path, dd_cache=False)
data_full_train.to_csv("./test/answer/data/train.csv", index=False)
data_full_dev.to_csv("./test/answer/data/dev.csv", index=False)
data_full_train = data_full_train.dropna()
data_full_dev = data_full_dev.dropna()
data_full_train_idx = data_full_train.index
data_full_dev_idx = data_full_dev.index
model_name="sentence-transformers/all-mpnet-base-v2"
train_data_save_dir = os.path.join(dir_path, model_name.split('/')[-1])ifnot os.path.exists(train_data_save_dir):
os.makedirs(train_data_save_dir)
word_embedding_model = models.Transformer(
model_name
)
pooling_model = models.Pooling(
word_embedding_model.get_word_embedding_dimension(),
pooling_mode_mean_tokens=True,
pooling_mode_cls_token=False,
pooling_mode_max_tokens=False,)
model = SentenceTransformer(modules=[word_embedding_model, pooling_model])
data_train = build_vector(index=data_full_train_idx, data=data_full_train, model=model)
data_dev = build_vector(index=data_full_dev_idx, data=data_full_dev, model=model)
pd.to_pickle(data_train,f"{train_data_save_dir}/data_train_sts_float.pkl")
pd.to_pickle(data_dev,f"{train_data_save_dir}/data_dev_sts_float.pkl")
皮尔逊相关系数用于度量两个变量
(X和Y)
之间的线性相关程度,其值介于
-1
与
1
之间。
在上述代码中,为了便于计算,我将皮尔逊相关系数的值从
[-1,1]
之间映射到了
[0,1]
之间,值越大,越相关,值越小,越不相关。
值得注意的是,我们这里的训练数据是
<query, answer>
对,更为正确的做法是使用
<query, query>
对作为训练数据。奈何没有高质量的人工标注数据,只能先用
<query, answer>
训练出一版模型看看效果。
训练SBERT模型
说实话,这训练代码,是真的简单,不信看代码:
import os
import pandas as pd
from sentence_transformers import SentenceTransformer, SentencesDataset, models
from sentence_transformers import InputExample, evaluation, losses
from torch.utils.data import DataLoader
from common.path.model.sentence_model import get_sentence_model_dir
classTrainSentectTransformerModel():def__init__(self, config, options):
self.model_name="sentence-transformers/multi-qa-MiniLM-L6-cos-v1"
self.build_dataset_model_name ="all-mpnet-base-v2"
self.data_dir_path ="./data/datasets/answer/sts_dset"
self.data_dir_path = os.path.join(self.data_dir_path, self.build_dataset_model_name)
self.train_path = os.path.join(self.data_dir_path,"data_train_sts_float.pkl")
self.dev_path = os.path.join(self.data_dir_path,"data_dev_sts_float.pkl")
self.model =None
self.model_save_dir = get_sentence_model_dir()
self.model_save_path = os.path.join(self.model_save_dir, self.model_name.split("/")[-1])defload(self):
word_embedding_model = models.Transformer(
self.model_name
)
pooling_model = models.Pooling(
word_embedding_model.get_word_embedding_dimension(),
pooling_mode_mean_tokens=True,
pooling_mode_cls_token=False,
pooling_mode_max_tokens=False,)
self.model = SentenceTransformer(modules=[word_embedding_model, pooling_model])defload_train_data(self):
train_data = pd.read_pickle(self.train_path)
train_data_list =[]for item in train_data:
sa, sb = item.texts
label =float(item.label)
dn = InputExample(texts=[sa, sb], label=label)
train_data_list.append(dn)
train_dataset = SentencesDataset(train_data_list, self.model)
train_dataloader = DataLoader(train_dataset, shuffle=True, batch_size=32)return train_dataloader
defload_dev_data(self):
sentences1, sentences2, scores =[],[],[]
dev_data = pd.read_pickle(self.dev_path)for item in dev_data:
sa, sb = item.texts
label = item.label
sentences1.append(sa)
sentences2.append(sb)if label >0.5:
label =1else:
label =0
scores.append(label)return sentences1, sentences2, scores
deftrain(self):
self.load()
train_dataloader = self.load_train_data()
dev_sentences1, dev_sentences2, dev_scores = self.load_dev_data()
train_loss = losses.CosineSimilarityLoss(self.model)
evaluator = evaluation.BinaryClassificationEvaluator(dev_sentences1, dev_sentences2, dev_scores)
self.model.fit(train_objectives=[(train_dataloader, train_loss)], epochs=50, warmup_steps=100,
evaluator=evaluator, evaluation_steps=300, output_path= self.model_save_path)
self.model.evaluate(evaluator)def__call__(self):
self.train()
是吧,训练很简单,只有些数据处理的操作
测试
训练完成后,我们来试试效果:
deftest_sentence_model(config, options):
model_dir ="./data/models/sentence_model/multi-qa-MiniLM-L6-cos-v1"
model = SentenceTransformer(model_dir)
query_sentence ="hp服务器序列号"
target_sentences ="xmind2021激活序列号"
query_vector = model.encode([query_sentence])
target_vectors = model.encode([target_sentences])
score = cosine_similarity(query_vector, target_vectors)print(score[0][0])
输出:
0.46232918
再使用一条典型数据来测试下:
query_sentence ="引入Echart后无法引用echart.方法 先下载了Echarts包,然后在head里引入了echarts.js,定义div并赋予了大小"
target_sentences ="echarts隐藏柱体,但要在悬浮中显示数据 echarts需要隐藏某个柱状图的柱体,但是要在悬浮中有显示这个隐藏柱体的数据"# score = 0.9297024
我们来分析下,这两条数据,有部分重叠的关键词,但整体语义,并不相关,语义相似度应该很低才对,但我们的模型,给出的分数竟然有
0.92
,出乎意料。
我们再来看下我们的训练数据:
q_str ="python 实现sql递归"
doc_str ="python实现递归的例子 用递归实现阶乘 def func (n) : if n == 1 : return 1 else : return n * func(n- 1 ) 用递归实现斐波那契数列 def fibo (n) : if n == 1 or n == 2 : return 1 else : return fibo(n- 1 ) + fibo(n- 2 ) 用递归实现二分查找 def b_sort (l, aim, start= 0 , end=None) : if end == None : end = len(l)- 1 if start <= end: mid = (end-start) // 2 + start #保证每次都是相应的数列位置 if aim < l[mid]: return b_sort(l, aim, s"
我们的训练数据,
q_str
与
doc_str
之间也是存在部分关键词重叠,但二者语义是相关的。
因此,造成上面测试用例语义得分太高的原因显而易见了。训练时我们使用
<query, answer>
对,预测时我们使用
<query, query>
对,训练与预测不一致,导致即使有部分关键词重叠,但整体语义相差较大,模型输出的得分较大。
那么,既然我们没有
<query, query>
对格式的数据,我们做到这里,只能放弃了吗?
不!CSDN AI小组没有放弃!
首先,我们需要确定的是,这个模型,对于语义相关的数据,是有效的!(已经通过实验证实,确实是有效)
既然模型有效,那么,我们只需要过滤掉只有部分关键词重合,但整体语义不相关的数据就可以了。
怎么过滤呢?
答案是:我们再训练一个
tfidf
模型,计算
query_a
与
query_b
的
tfidf
得分,只有部分关键词重合的数据,其关键词得分应该是较低的。
那么,我们计算下之前使用过的两条
query
的
tfidf
得分:
query_a ="引入Echart后无法引用echart.方法 先下载了Echarts包,然后在head里引入了echarts.js,定义div并赋予了大小"
query_b ="echarts隐藏柱体,但要在悬浮中显示数据 echarts需要隐藏某个柱状图的柱体,但是要在悬浮中有显示这个隐藏柱体的数据"
tfidf_score =0.1512441662635543
确实是较低!(当然,并不是通过这一条数据得出的结论)
加入
tfidf
限制后,
query
与
query
之间存在重叠关键词但语义不相关的问题得到了解决。
那么,语义匹配的问题,就解决了。接下来需要考虑的是,
CSDN
问答库中,有
50w
左右的已采纳数据,这么大的数据量,总不能用
query
去与所有数据一一计算相似度吧?显然,这是不现实的。
粗排
在大多数的问答系统中,一般分为三个模块:
- 意图识别
- 粗排
- 精排
在这里,我们暂时没有做意图识别模块,也许,后续数据量大了,会加入意图识别。加入意图识别,有以下好处:
- 缩小匹配范围
- 提升匹配效率
- 提升匹配准确率
如果你的数据量够大,至少每个类别下面有几十万的数据,你可以考虑加入意图识别模块来提升你问答系统整体的效果。
那么,我们要怎么构建自己的问答数据库呢?
由于我们的数据都是文本,要计算文本之间的语义相似度,首先我们需要将文本转换成向量,转成向量后,我们需要构建一个倒排索引表,将这些文本数据,存入倒排表中。类似
Elasticsearch
在建立索引的时候采用的倒排索引的机制(强烈建议去了解下)。
HNSW就是一种构建倒排索引以达到快速检索的算法,在这篇文章中,采用的便是这种算法。
有关HNSW的原理,推荐阅读:一文看懂HNSW算法理论的来龙去脉
好在
python
各种包多,不管啥算法,都有前人帮你实现了,你只要
pip
一下,就能用了。
hnsw
的实现,有两个包,一个是
Facebook
研发的
faiss
,一个是
hnswlib
,这里我使用的是
hnswlib
,据说二者都是
c++
实现,使用起来没太大差别。
hnswlib使用手册:https://github.com/nmslib/hnswlib
classHNSW(object):def__init__(self, config, options):
self.hnsw_config ={"M":64,"ef":2000}
self.hnsw_model_path = get_sentence_hnsw_model_path()
self.hnsw_vec_data_path = get_hnsw_vec_data_path()
self.answer_pg_query = AnswerPgQuery(config, options)
self.sentence_transform_model_path = get_sentence_transformers_model_path()
self.method ="sentence_transformer"
self.sentence_model =None
self.hnsw =Nonedefload(self):if os.path.exists(self.hnsw_model_path):
logger.info("加载 hnsw ...")
self.hnsw = self.load_hnsw()
logger.info("加载 sentence transformer model ...")if torch.cuda.is_available():
device = torch.device("cuda")else:
device = torch.device("cpu")
self.sentence_model = SentenceTransformer(
self.sentence_transform_model_path, device=device)defload_data(self):
data =[]
all_answer_data = self.answer_pg_query.fetch_all_answer_data()for item in tqdm(all_answer_data, desc=f"get vec {self.method}"):
title = item[0]
body = item[1]
body = get_text_from_html(body)
text_vec = self.sentence_model.encode([title + body])
sentence_vec = text_vec[0]
data.append(sentence_vec)
joblib.dump(data, self.hnsw_vec_data_path)return data
deftrain_hnsw(self):
sentences_vec = self.load_data()
cores = multiprocessing.cpu_count()
num_elements =len(sentences_vec)
logger.info("初始化 hnsw ...")# possible options are l2, cosine or ipimport hnswlib
p = hnswlib.Index(space='l2', dim=384)
p.init_index(max_elements=num_elements,
ef_construction=self.hnsw_config['ef'], M=self.hnsw_config['M'])
p.set_ef(10)
p.set_num_threads(cores)
logger.info("Adding first batch of %d elements"%(len(sentences_vec)))
p.add_items(sentences_vec)
labels, distances = p.knn_query(sentences_vec, k=1)print('labels: ', labels)print('distances: ', distances)print("Recall:{}".format(
np.mean(labels.reshape(-1)== np.arange(len(sentences_vec)))))
p.save_index(self.hnsw_model_path)del p
defload_hnsw(self):import hnswlib
hnsw = hnswlib.Index(space='l2', dim=384)
hnsw.load_index(self.hnsw_model_path)return hnsw
defadd_elements(self, data_vec):import hnswlib
hnsw = hnswlib.Index(space='l2', dim=384)
hnsw.load_index(self.hnsw_model_path)
current_elements_num = hnsw.element_count
max_elements = current_elements_num +len(data_vec)
hnsw_copy = copy.deepcopy(hnsw)del hnsw
hnsw_copy.load_index(self.hnsw_model_path, max_elements)
hnsw_copy.add_items(data_vec)
hnsw_copy.save_index(self.hnsw_model_path)defsearch(self, text, k=5):
text_vec = self.sentence_model.encode([text])
q_labels, q_distances = self.hnsw.knn_query(text_vec, k=k)return q_labels, q_distances
defget_search_result(self, text):
q_labels, q_distances = self.search(text, k=10)
indexs = q_labels[0]# 取得粗排结果
res_str =""for index in indexs:
index = index +1
ret = self.answer_pg_query.query_answer_data_by_index([index])
title = ret[0][1]
body = ret[0][2]
res_str +=f"Query : {text} , Target : {title} \n"print(res_str)return
在构建句向量时,我使用的是前面训练好的
SBERT
模型。有些人可能会说,使用
word2vec
来构建句向量不行吗?
我的回答是:不行!
因为训练好的
word2vec
太大了,就拿这个例子来说,
50w
的数据,训练出来的
word2vec
的大小已经达到了
GB
级别,服务器上内存本来就紧张,你再加个
GB
级别的模型,服务器分分钟被你干崩溃,等着写事故报告吧!
由于开发时间问题,我这里只尝试了
SBERT
去构建句向量,其实,你还可以尝试使用
AutoEncoder
的方法去构建句向量。关于
AutoEncoder
原理,可以参考:深入理解AutoEncoder
在度量相似度时,
hnswlib
支持三种方式,如下图:
这里我选择了
Squared L2
,哪一种方式更准确,我并没有去做对比实验,如果你构建句向量的模型足够准确,理论上差距不大。
我们来看看效果:
Query : Python重量计算 重量计算 月球上的物体重量是地球上的16.5%, Target : Python重量计算
Query : Python重量计算 重量计算 月球上的物体重量是地球上的16.5%, Target : 有关python制作七段数码管的问题
Query : Python重量计算 重量计算 月球上的物体重量是地球上的16.5%, Target : python数字与字母分离
Query : Python重量计算 重量计算 月球上的物体重量是地球上的16.5%, Target : python昆虫繁殖问题
Query : Python重量计算 重量计算 月球上的物体重量是地球上的16.5%, Target : 各位朋友 如何用python语言表达
Query : Python重量计算 重量计算 月球上的物体重量是地球上的16.5%, Target : python复利计算利息
Query : Python重量计算 重量计算 月球上的物体重量是地球上的16.5%, Target : python如何用时间遍历很多个月
Query : Python重量计算 重量计算 月球上的物体重量是地球上的16.5%, Target : 简单的Python题求解
Query : Python重量计算 重量计算 月球上的物体重量是地球上的16.5%, Target : Python输入上课时间的总秒数,计算今天上课时间是多少小时多少分多少秒的方式表示出来
Query : Python重量计算 重量计算 月球上的物体重量是地球上的16.5%, Target : Python上机实践,字符类型及其操作
确实可以找到目标答案,从这里也可以看出,使用
<query, answer>
对去训练
SBERT
,虽然会带来负面作用,但可以粗略表示句向量。
从上面的代码中,可以看出,
hnswlib
还支持增量数据插入,这样,就不需要每次全量更新倒排索引表了,只需要将新增的数据插入到索引表中就可以,大大减少了计算量。
注意: 我们拿到的召回结果,只是
query
文本的句向量对应的下标索引,因此,我们的原始数据,需要保存在数据库中,这样,才能通过召回结果,找到源数据。
精排
粗排的过程,一般也称之为召回,取得召回的结果后,我们需要对召回的结果,进行精排。
精排的过程,其实就是将
query
与召回的结果,一一计算相似度,取出得分最大的那一条数据,作为输出。我们这里,精排模型使用的是我们一开始训练的
SBERT
模型,将
query
和召回的结果,转换成句向量,用
query
与召回结果一一计算余弦相似度。
defget_tfidf_score(self, query_text, target_text):
str_a_list = self.segment.segment(query_text)
str_b_list = self.segment.segment(target_text)
text_a =' '.join(str_a_list)
text_b =' '.join(str_b_list)
vec_a = self.tfidf.transform([text_a])
vec_b = self.tfidf.transform([text_b])
sim = cosine_similarity(vec_a, vec_b)[0][0]return sim
defget_result(self, query):
logger.info("获取召回结果...")
q_labels, q_distances = self.hnsw.search(query)
indexs = q_labels[0]# 取得粗排结果
recall_res =[]for index in indexs:
index = index +1
ret = self.answer_pg_query.query_answer_data_by_index([index])[0]
question_id = ret[0]
title = ret[1]
body = ret[2]
answer_id = ret[3]
tag_ids = ret[4]
item =(query, question_id, title, body, answer_id, tag_ids)
recall_res.append(item)# 准备精排需要的相似度特征
lightgbm_df = pd.DataFrame(columns=['query','target_question_id','target_title','target_body','answer_id','tag_ids','bert_cos'])for idx, item inenumerate(recall_res):
query, question_id, title, body, answer_id, tag_ids = item
target = title + body
bert_cos = self.text_similarity_bert.bert_sim(query, target, sim='cos')
lightgbm_df.loc[idx]=[query, question_id, title, body, answer_id, tag_ids, bert_cos]# 精排
lightgbm_df.sort_values(by=["bert_cos"], inplace=True, ascending=False)
result =[]for idx, row in lightgbm_df.iterrows():
query_ret ={}if row['bert_cos']>0.9:
logger.info(f"语义相似度为: {row['bert_cos']}")
query_text = row['query']
target_body = row['target_body']
target_question_id = row['target_question_id']
target_title = row['target_title']
tfidf_score = self.get_tfidf_score(str(query_text),str(target_title)+str(target_body))
logger.info(f"tfidf得分为: {tfidf_score}")
logger.info(f"[query_text]: {str(query_text)}")
logger.info(f"[target_body]: {str(target_body)}")
score =int(row['bert_cos']*100)
url ="https://ask.csdn.net/questions/{}".format(target_question_id)
recommend_id = uuid.uuid4().hex
answer_id = row['answer_id']
tag_ids = row['tag_ids']
tag_ids = tag_ids.strip()
tag_id_list = tag_ids.split(',')if tag_id_list ==['']:
tag_id =Noneelse:
tag_id =int(tag_id_list[0])
method = random.choice([0,1])# method = 1 -- 加入tfidf限制# method = 0 -- 不加入tfidf限制
query_ret['method']=0if tfidf_score>=0.2and method ==1:
query_ret['method']=1
logger.info("加入tfidf限制...")elif method ==0:
query_ret['method']=0
logger.info("未加入tfidf限制...")
query_ret['question_id']= target_question_id
query_ret['answer_id']= answer_id
query_ret['title']= target_title
query_ret['tag_id']= tag_id
query_ret['score']= score
query_ret['url']= url
query_ret['recommend_id']= recommend_id
result.append(query_ret)breakreturn result
在取得精排的结果后,取分值最大的那条数据,且相似度分数要超过
0.9
,这个
0.9
并不是头脑发热设置的,而是通过数据分析得出的结论,限制分数阈值后,还需要计算
query
与相似度得分最高的那条结果的
tfidf
相似度,同理,这里也设置了
tfidf score
阈值,这个阈值,也是通过数据分析得出来的结论,两项限制都满足后,才会给用户推荐,这样做,大大降低了误推率。
其实,如果你的训练数据是
<query, query>
对的话,在精排时,除了语义相似度外,你可以再构造一些其他的人工处理好的特征,如编辑距离、皮尔逊相关系数、KL散度等。
classTextSimilarityML(object):def__init__(self)->None:# self.train_w2v = TrainWord2Vec()
self.tfidf = joblib.load(get_sentence_tfidf_model_path())# self.w2v_model = KeyedVectors.load(get_sentence_word2vec_model_path())
self.sentence_transformer_model = SentenceTransformer(get_sentence_transformers_model_path())@classmethoddeftokenize(self , str_a):
wordsa = pseg.cut(str_a)
cuta =""
seta =set()for key in wordsa:
cuta += key.word +" "
seta.add(key.word)return[cuta , seta]defJaccardSim(self , str_a , str_b):
seta = self.tokenize(str_a)[1]
setb = self.tokenize(str_b)[1]
sa_sb =1.0*len(seta & setb)/len(seta | setb)return sa_sb
@staticmethoddefcos_sim(a ,b):
a = np.array(a)
b = np.array(b)return np.sum(a * b)/(np.sqrt(np.sum(a**2))* np.sqrt(np.sum(b**2)))@staticmethoddefkl_divergence(p,q):return scipy.stats.entropy(p, q)@staticmethoddefjs_divergence(P,Q):
M=(P+Q)/2return0.5*scipy.stats.entropy(P, M)+0.5*scipy.stats.entropy(Q, M)@staticmethoddefeucl_sim(a ,b):
a = np.array(a)
b = np.array(b)return1/(1+ np.sqrt((np.sum(a - b)**2)))@staticmethoddefpearson_sim(a , b):
a = np.array(a)
b = np.array(b)
a = a - np.average(a)
b = b - np.average(b)return np.sum(a * b)/(np.sqrt(np.sum(a**2))* np.sqrt(np.sum(b**2)))defeditDistance(self , str1 , str2):
m =len(str1)
n =len(str2)
lensum =float(m + n)
d =[[0]*(n+1)for _ inrange(m+1)]for i inrange(m+1):
d[i][0]= i
for j inrange(n+1):
d[0][j]= j
for j inrange(1, n+1):for i inrange(1, m+1):if str1[i -1]== str2[j -1]:
d[i][j]= d[i-1][j-1]else:
d[i][j]=min(d[i-1][j], d[i][j-1], d[i-1][j-1])+1
dist = d[-1][-1]
ratio =(lensum -dist)/ lensum
return ratio
deflcs(self, str_a , str_b):
lengths =[[0for j inrange(len(str_b)+1)]for i inrange(len(str_a)+1)]for i,x inenumerate(str_a):for j,y inenumerate(str_b):if x==y:
lengths[i+1][j+1]= lengths[i][j]+1else:
lengths[i+1][j+1]=max(lengths[i+1][j], lengths[i][j+1])
result =""
x,y =len(str_a),len(str_b)while x !=0and y !=0:if lengths[x][y]== lengths[x -1][y]:
x -=1elif lengths[x][y]== lengths[x][y-1]:
y -=1else:assert str_a[x-1]== str_b[y-1]
result = str_a[x-1]+ result
x -=1
y -=1
longestdist = lengths[len(str_a)][len(str_b)]
ratio = longestdist /min(len(str_a),len(str_b))return ratio
deftokenSimilarity(self , str_a , str_b , method='tfidf', sim='cos'):
vec_a , vec_b , model =None,None,Noneif method =='tfidf':
str_a = self.tokenize(str_a)[0]
str_b = self.tokenize(str_b)[0]
vec_a = self.tfidf.transform([str_a]).toarray()
vec_b = self.tfidf.transform([str_b]).toarray()elif method =="bert":
vec_a = self.sentence_transformer_model.encode([str_a])
vec_b = self.sentence_transformer_model.encode([str_b])else:
NotImplementedError
result =Noneif(vec_a isnotNone)and(vec_b isnotNone):if sim =='cos':
result = self.cos_sim(vec_a[0], vec_b[0])elif sim =='eucl':
result = self.eucl_sim(vec_a[0], vec_b[0])elif sim =='pearson':
result = self.pearson_sim(vec_a[0], vec_b[0])elif sim =='wmd'and model:
result = model.wmdistance(str_a, str_b)elif sim =='js':
result = self.js_divergence(vec_a[0], vec_b[0])elif sim =='kl':
result = self.kl_divergence(vec_a[0], vec_b[0])return result
defgen_simility(self, str1, str2):return{"lcs": self.lcs(str1, str2),"edit_dist": self.editDistance(str1, str2),"jaccard": self.JaccardSim(str1, str2),"tfidf_cos": self.tokenSimilarity(str1, str2, method='tfidf', sim='cos'),"tfidf_eucl": self.tokenSimilarity(str1, str2, method='tfidf', sim='eucl'),"tfidf_pearson": self.tokenSimilarity(str1, str2, method='tfidf', sim='pearson'),"tfidf_kl": self.tokenSimilarity(str1, str2, method='tfidf', sim='kl'),"tfidf_js": self.tokenSimilarity(str1, str2, method='tfidf', sim='js'),"bert_cos": self.tokenSimilarity(str1, str2, method='bert', sim='cos'),"bert_eucl": self.tokenSimilarity(str1, str2, method='bert', sim='eucl'),"bert_pearson": self.tokenSimilarity(str1, str2, method='bert', sim='pearson'),}
构造好这些人工特征后,可以利用决策树的思想,训练各个特征的权重,所幸,在
lightgbm
中,就有这么一个方法,可以拿来即用:
import os
import logging
import joblib
import lightgbm as lgb
import numpy as np
from common.path.dataset.answer import get_lightgbm_train_data_path
from common.path.dataset.answer import get_lightgbm_dev_data_path
from common.path.model.sentence_model import get_sentence_lightgbm_ranker_model_path
logger = logging.getLogger(__name__)classLihtgbmRankerTrain(object):def__init__(self)->None:
self.train_path = get_lightgbm_train_data_path()
self.dev_path = get_lightgbm_dev_data_path()
self.model_path = get_sentence_lightgbm_ranker_model_path()
self.params ={'boosting_type':'gbdt','max_depth':5,'objective':'binary',# 'nthread': 3, 'num_leaves':64,'learning_rate':0.05,'max_bin':512,'subsample_for_bin':200,'subsample':0.5,'subsample_freq':5,'colsample_bytree':0.8,'reg_alpha':5,'reg_lambda':10,'min_split_gain':0.5,'min_child_weight':1,'min_child_samples':5,'scale_pos_weight':1,# 'max_position': 20,'group':'name:groupId','metric':'auc'}ifnot os.path.exists(self.model_path):
self.model =None
logger.warning("模型不存在,请先训练...")else:
logger.info(f"加载模型: {self.model_path}")
self.model = joblib.load(self.model_path)defload_data(self):
train_data = joblib.load(self.train_path)
dev_data = joblib.load(self.dev_path)
train_x =[]
train_y =[]for item in train_data:
item =list(item)
x = item[:-1]
y = item[-1]
train_x.append(x)
train_y.append(y)
dev_x =[]
dev_y =[]for item in dev_data:
item =list(item)
x = item[:-1]
y = item[-1]
dev_x.append(x)
dev_y.append(y)return train_x, train_y, dev_x, dev_y
deftrain(self):
train_x, train_y, dev_x, dev_y = self.load_data()
train_x = np.array(train_x)
train_y = np.array(train_y)
dev_x = np.array(dev_x)
dev_y = np.array(dev_y)
query_train =[train_x.shape[0]]
query_val =[dev_x.shape[0]]
self.gbm = lgb.LGBMRanker(**self.params)
self.gbm.fit(train_x , train_y , group=query_train , eval_set=[(dev_x , dev_y)], eval_group=[query_val], eval_at=[5,10,20], early_stopping_rounds=50)
joblib.dump(self.gbm, self.model_path)defpredict(self, recall_data):
result = self.model.predict(recall_data)return result
注意: 如果你是
<query, query>
对的数据,你可以这样来精排,如果你和我一样,是
<query, answer>
对的数据,你这样精排的意义就不大。因为最后训练出来的权重,除了语义相似度特征的权重较大,其他特征的权重都接近
0
。(建议亲自动手试试,实践出真知!)
优化策略
在做完精排后,你以为事情就结束了?
其实远没有,用
<query, answer>
对的数据集,只能解决一部分问题,要想带来质的提升,一方面是你的问答库要非常全,这个需要长时间积累,另一方面,你需要标注
<query, query>
对的数据,但这种数据非常难标注,往往需要专业的
IT
从业人员标注,才能获取到一个较为准确的结果。
但是,我们
CSDN
上的用户,都是专业的
IT
从业人员,在问答的前端页面上,我们可以增加几个按钮,让用户帮我们来标注,这样不但成本低,且标注效果好,所以,我在精排后返回的数据中,增加了一个
recommend_id
字段,用来标记推荐的结果,用户点击按钮后,会更新这条推荐结果的状态,如下图:
结果

目标是
5%
,虽然达到了目标,但离真正地提升用户体验,还有很长一段路要走。
继续加油!
总结
1、作为一名合格的
NLPer
,不仅要考虑模型本身的效果,更要考虑如何构建高质量的数据集。模型与模型之间的差距并不会特别大,与其花大量时间在模型上,不如花一部分时间在数据上,也许,带来的收益会更大。
2、一个好的NLP项目,往往需要形成一个闭环,模型运行起来后,并不是再也不更新,我们需要持续收集用户反馈,持续跟进,持续分析
badcase
,持续迭代优化
最后,有对代码感兴趣的同学,可以看我之前写的一篇文章:FAQ式问答系统
版权归原作者 PeasantWorker 所有, 如有侵权,请联系我们删除。