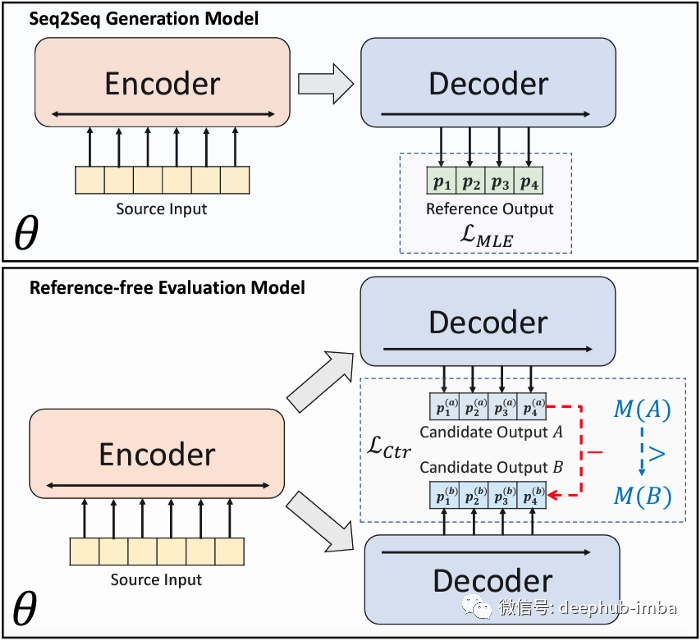
BRIO:抽象文本摘要任务新的SOTA模型
在 SimCLS [2]论文发布后不久,作者又发布了抽象文本摘要任务的SOTA结果 [1]。BRIO在上述论文的基础上结合了对比学习范式。

5分钟NLP:Text-To-Text Transfer Transformer (T5)统一的文本到文本任务模型
本文将解释如下术语:T5,C4,Unified Text-to-Text Tasks
NLP 进行文本摘要的三种策略代码实现和对比:TextRank vs Seq2Seq vs BART
本文将使用 Python 实现和对比解释 NLP中的3 种不同文本摘要策略:老式的 TextRank(使用 gensim)、著名的 Seq2Seq(使基于 tensorflow)和最前沿的 BART(使用Transformers )
自然语言处理--------jieba分词(文章中含有源码)
#TODO jieba 一个自然语言处理工具包 ,除了jieba还有 HanLP 和 LTKimport jieba#TODO 词、句 匹配#全模式seg_list=jieba.cut("我喜欢吃酸菜鱼",cut_all=True)print("全模式: "+"/".
自然语言处理 之 文本热词提取--------文章中含有《源码》和《数据》,可以拿来玩玩
🎂主要就是通过jieba的posseg模块将一段文字分段并赋予不同字段不同意思。然后通过频率计算出热频词数据放在文章里面了,就不用花积分下载了**🐱🐉💋代码**# TODO 鸟欲高飞,必先展翅# TODO 向前的人 :Jhoni

5分钟NLP:HuggingFace 内置数据集的使用教程
对于NLP 爱好者来说HuggingFace肯定不会陌生,HuggingFace为NLP任务提供了维护了一系列开源库的应用和实现,今天我们来看一下用于NLP任务的数据集总结。
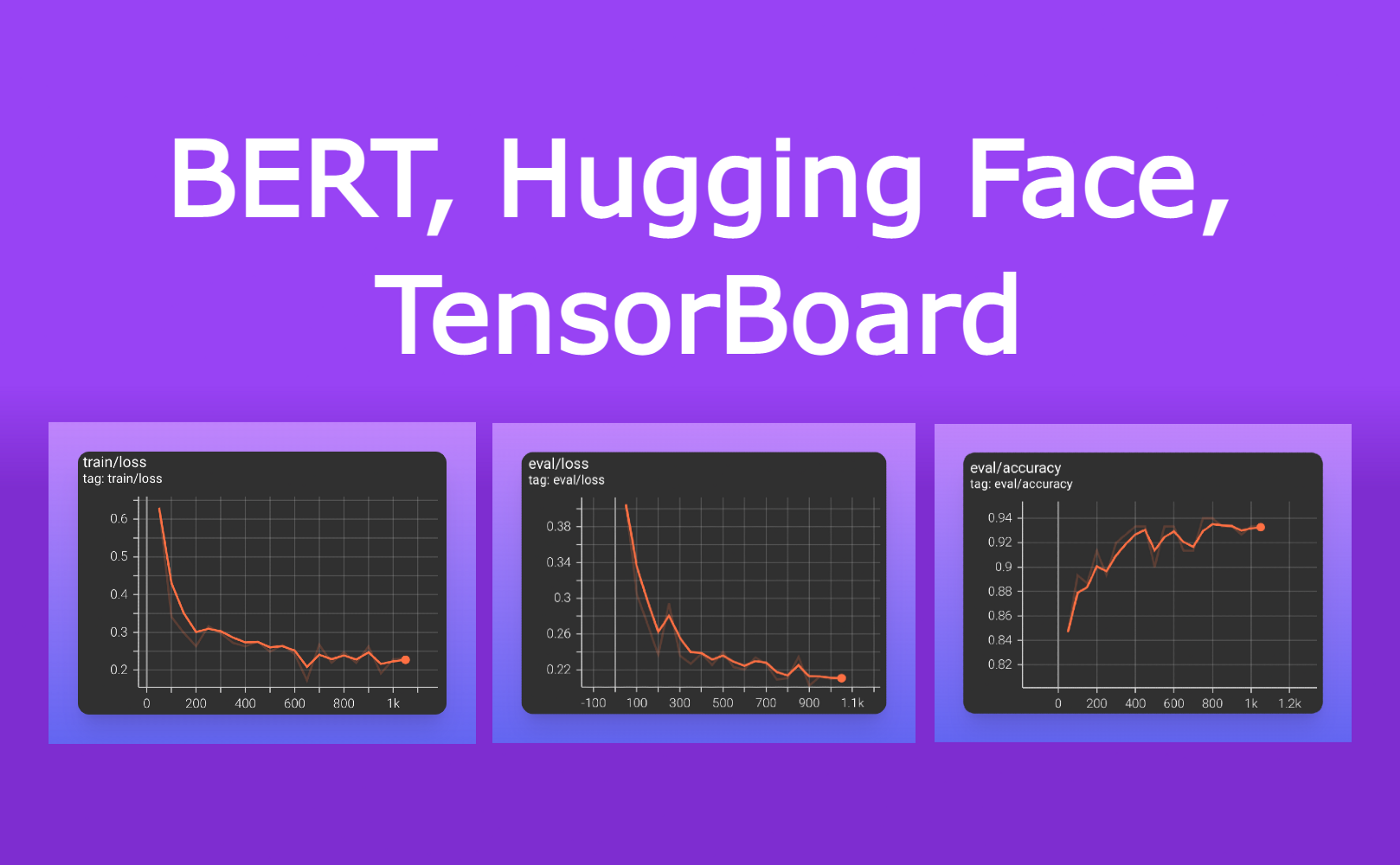
5分钟NLP:使用 HuggingFace 微调BERT 并使用 TensorBoard 可视化
上篇文章我们已经介绍了Hugging Face的主要类,在本文中将介绍如何使用Hugging Face进行BERT的微调进行评论的分类。

条件随机场(CRF)的详细解释
条件随机场(CRF)结合了最大熵模型和隐马尔可夫模型的特点,是一种无向图模型,其中相邻的上下文信息或状态会影响当前预测,常用于标注或分析序列资料,如自然语言文字或是生物序列
自然语言处理必读论文推荐3篇
1.NLP Service APIs and Models for Efficient Registration of New Clients题目:用于高效注册新客户的NLP服务API和模型链接:学术范摘要:最先进的NLP推理使用了大量的神经架构和经过gpu数月训练的模型,远远超出了大多数NLP用户

5分钟 NLP :Hugging Face 主要类和函数介绍 🤗
主要包括Pipeline, Datasets, Metrics, and AutoClasses
人工智能之自然语言处理技术总结与展望
1. 背景2. 预训练语言模型3. Prompt Learning4. 数据增强5. 总结
word2vec-python对词进行相似度计算1
初学NLP,尝试word2vec模型第一次学这种,查阅了很多的博客,克服了些些问题,记录一下第一次探索的历程和相关代码,文中借鉴多篇优秀的文章,连接会在文章中给出。1.实验样本在我最开始寻找实验头绪的时候,了解做这个需要实验样本,但是大部分博主没有提供他的实验样本,所以我在网络上下载了《倚天屠龙记》
NLP:Transformer的简介(优缺点)、架构详解之详细攻略
NLP:Transformer的简介(优缺点)、架构详解之详细攻略目录Transformer的简介(优缺点)、架构详解之详细攻略1、Transformer的简介(1)、Transforme的四4个优点和2个缺点2、Transformer 结构—纯用attention搭建的模型→计算速度更快Trans
深度盘点:30个用于深度学习、自然语言处理和计算机视觉的顶级 Python 库
今天我们来盘点一下有哪些用于深度学习、自然语言处理和计算机视觉的顶级Python库。我尽力将每个库按预期的使用情况进行归类,所有包含的库都有对应的Github代码仓库,我还列出每个库的在Github上的收藏(Stars) ,提交(Commits ),贡献者(Contributors)的数据,这在一定
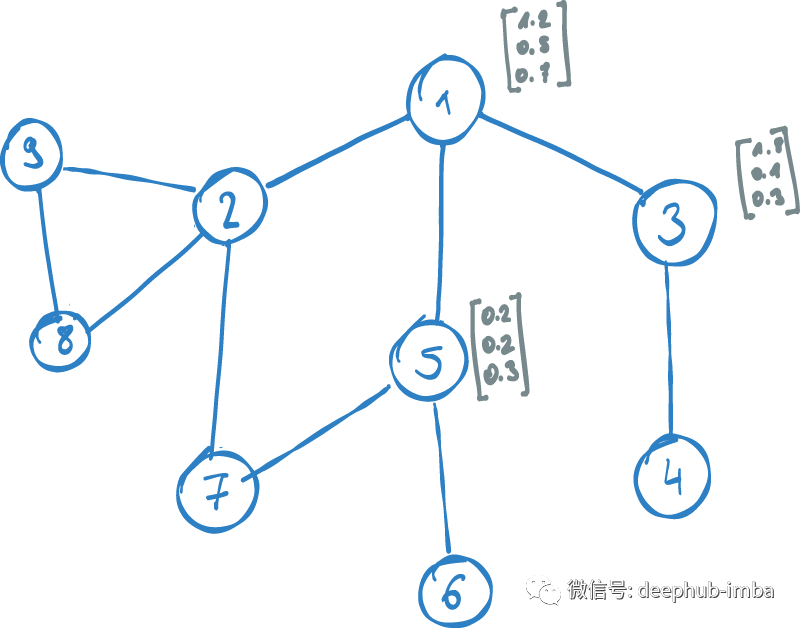
图嵌入中节点如何映射到向量
所有的机器学习算法都需要输入数值型的向量数据,图嵌入通过学习从图的结构化数据到矢量表示的映射来获得节点的嵌入向量。它的最基本优化方法是将具有相似上下文的映射节点靠近嵌入空间。

5分钟NLP:快速实现NER的3个预训练库总结
在本文中,将介绍对文本数据执行 NER 的 3 种技术。这些技术将涉及预训练和定制训练的命名实体识别模型。

5分钟NLP:从 Bag of Words 到 Transformer 的时间年表总结
本文对影响NLP研究的一些重要的模型进行总结,并尽量让它简约而不是简单,如果你刚刚进入NLP领域,本文可以作为深入研究该领域的起点。

使用DistilBERT 蒸馏类 BERT 模型的代码实现
在本篇文章中我们将使用DistilBERT 蒸馏类 BERT 模型,并给出完整的代码实现。

5分钟NLP - SpaCy速查表
SpaCy 是一个免费的开源库,用于 Python 中的高级自然语言处理包括但不限于词性标注、dependency parsing、NER和相似度计算。它可帮助构建处理和理解大量文本的应用程序可用于多种方向,例如信息提取、自然语言理解或为深度学习提供文本预处理。



