
深度图像分类模型通常以监督方式在大型带注释数据集上进行训练。随着更多带注释的数据加入到训练中,模型的性能会提高,但用于监督学习的大规模数据集的标注成本时非常高的,需要专家注释者花费大量时间。为了解决这个问题,人们开始寻找更便宜的标注的标签来源,是否有可能从已经公开的数据中学习高质量的图像分类模型?
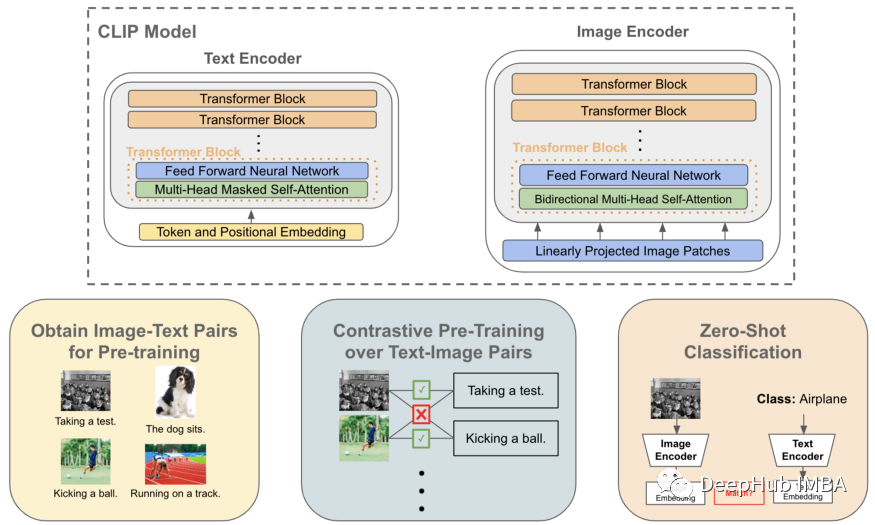
OpenAI 提出的CLIP模型 [1] 的提议——最近由于在 DALLE-2 模型中的使用而重新流行——它以积极的方式回答了这个问题。特别是CLIP 提出了一个简单的预训练任务——选择哪个标题与哪个图像搭配——它允许深度神经网络仅从自然语言(即图像标题)中学习高质量的图像表示。由于图像-文本对在网上很容易获得并且数据量非常的巨大,因此可以轻松地为 CLIP 管理一个大型预训练数据集,从而最大限度地减少标注成本和训练深度网络所需的工作量。
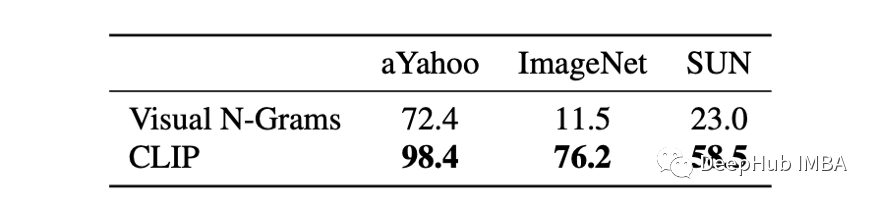
除了学习丰富的图像表示之外,CLIP 不需要标签并且在 ImageNet 上实现 76.2% 的测试准确率,这个结果彻底改变了零样本图像分类 - 与之前状态的 11.5% 的测试准确率的状态[2]。通过将自然语言建立为图像感知任务的可行训练信号,CLIP 改变了监督学习范式,使神经网络能够显着减少对注释数据的依赖。在这篇文章中,将概述 CLIP 的信息,如何使用它来最大程度地减少对传统的监督数据的依赖,以及它对深度学习从业者的影响。
CLIP之前的工作
在了解 CLIP 的细节之前,了解模型发展的历史会很有帮助。在本节中将概述相关的先前工作,并提供有关 CLIP 的灵感和发展的直觉。初步工作通过表明自然语言是图像感知监督的有用来源来作为概念证明。然而,由于这些方法相对于替代方法表现不佳(例如,监督训练、弱监督等),因此在 CLIP 提出之前,通过自然语言进行的训练仍然不常见。
使用 CNN 预测图像标题。之前的工作都是通过CNN 获得有用的图像表示来预测图像说明的 [3]。这种分类是通过将每个图像的标题、描述和主题标签元数据转换为词袋向量来执行的,然后可以将其用作多标签分类任务的目标。有趣的是,以这种方式学习的特征被证明与通过 ImageNet 上的预训练获得的特征相匹配,从而证明图像说明提供了关于每个图像的足够信息来学习判别表示。
后来的工作扩展了这种方法来预测与每个图像相关的短语 [2],从而实现零样本转移到其他分类数据集。尽管这种方法获得了较差的零样本学习性能(即在 ImageNet 上的测试准确率仅为 11.5%),但它表明仅使用自然语言就可以产生远远超过随机性能的零样本图像分类结果,因此可以说它提出了弱监督零样本分类的概念。
来自带有transformers的文本的图像表示。同时,包括 VirTex [4]、ICLMM [5] 和 ConVIRT [6] 在内的几项工作探索了使用transformers架构从文本数据中学习视觉特征。在高层次上,此类方法使用常见的transformers训练任务来从相关的图像的说明中学习有用的图像表示。由于这些工作,掩蔽语言建模 (MLM)、语言建模和对比学习目标——通常用于在自然语言处理领域训练转换器——被发现是学习高质量图像表示的有用代理任务。
上面的研究为未来的发现铺平了道路,尽管之前没有任何方法能够在大规模数据集上实现令人印象深刻的零样本性能,但这些基础性工作提供了非常有用的经验教训。也就是说,之前的工作表明:
i)自然语言是计算机视觉监督的有效来源
ii)通过自然语言监督进行零样本分类是可能的
由于这些发现,进一步的研究工作投入到执行零样本分类。这些努力带来了突破性的方法,比如CLIP,它将自然语言监督从一种罕见的方法转变为一种出色的零样本图像分类方法。
深入研究CLIP
简单地说CLIP模型旨在从相关的图像说明中学习图像中的视觉概念。在本节中将概述CLIP架构、训练,以及如何将结果模型应用于零样本分类。
模型架构
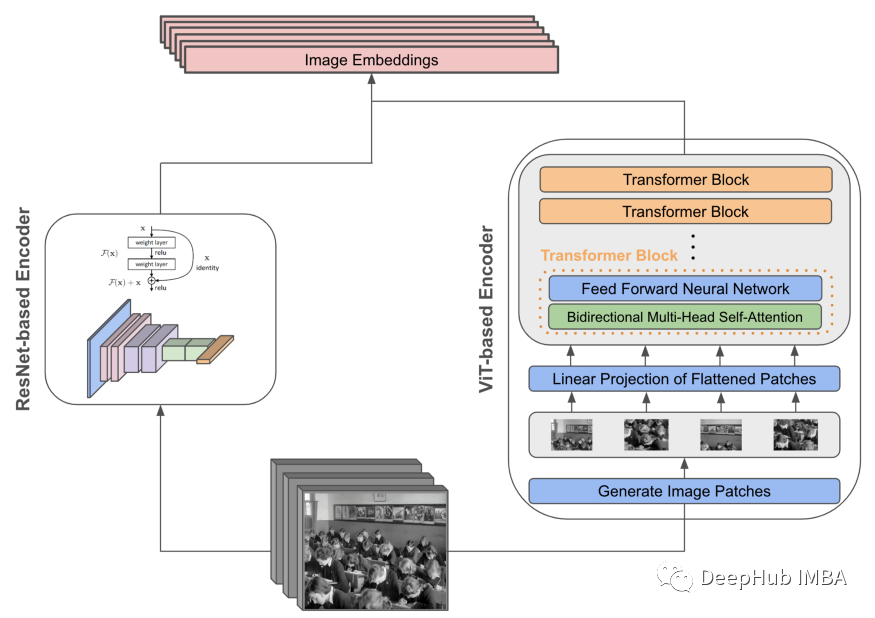
CLIP由两个编码模块组成,分别用于对文本数据和图像数据进行编码。对于图像编码器,探索了多种不同的模型架构,包括5种不同尺寸的ResNets[7],effecentnet风格[8]和3种ViT架构[9]。传统的CNN架构的两个选项如下所示,但是CLIP的ViT变体的训练计算效率要高出3倍,这使得它成为首选的图像编码器架构。
CLIP 中的文本编码器只是一个仅解码器的transformers,这意味着在每一层中都使用了掩码自注意力(与双向自注意力相反)。Masked self-attention 确保转换器对序列中每个标记的表示仅依赖于它之前的标记,从而防止任何标记“展望未来”以这样可以获得更好的表示。下面提供了文本编码器架构的基本描述。这种架构与大多数先前提出的语言建模架构(例如 GPT-2 或 OPT)非常相似。
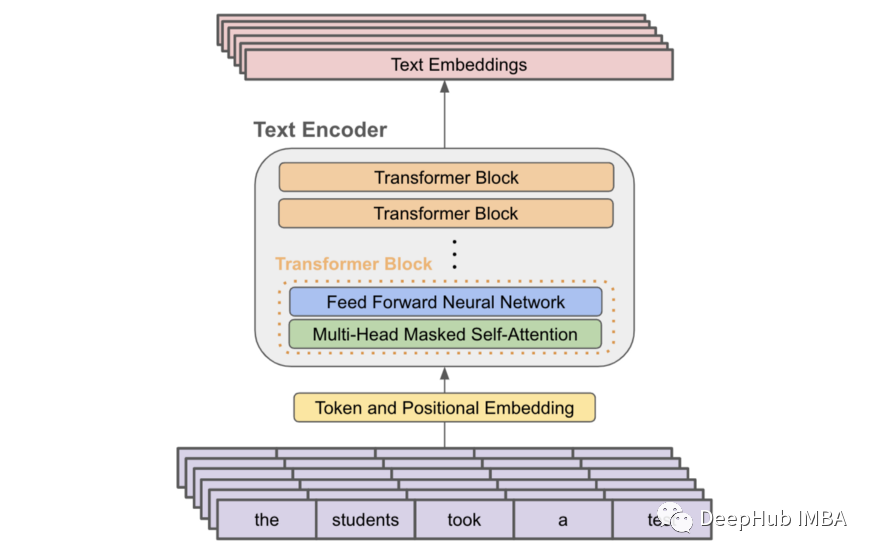
尽管在原始论文中没有将CLIP应用于任何语言建模应用程序,但作者利用了掩码自注意力,使CLIP在将来更容易扩展到这类应用程序。
通过自然语言进行监督训练
尽管以前的工作表明自然语言是计算机视觉的可行训练信号,但用于在图像和文本对上训练 CLIP 的确切训练任务并不是很明显。所以应该根据标题中的单词对图像进行分类吗?以前的工作已经尝试过并且证明时有效果的,但是并不好 [2, 3]。使用语言建模为每个图像生成标题呢?作者发现预测确切的图像说明太难了——导致模型学习非常缓慢——因为可以描述图像的方式是多种多样的。
理想的 CLIP 预训练任务应该是可扩展的,应该允许模型有效地从自然语言监督中学习有用的表示并可以利用对比表示学习中的相关工作,作者发现可以使用一个非常简单的任务来有效地训练 CLIP——在一组候选字幕中预测正确的相关字幕。下图说明了这样的任务。
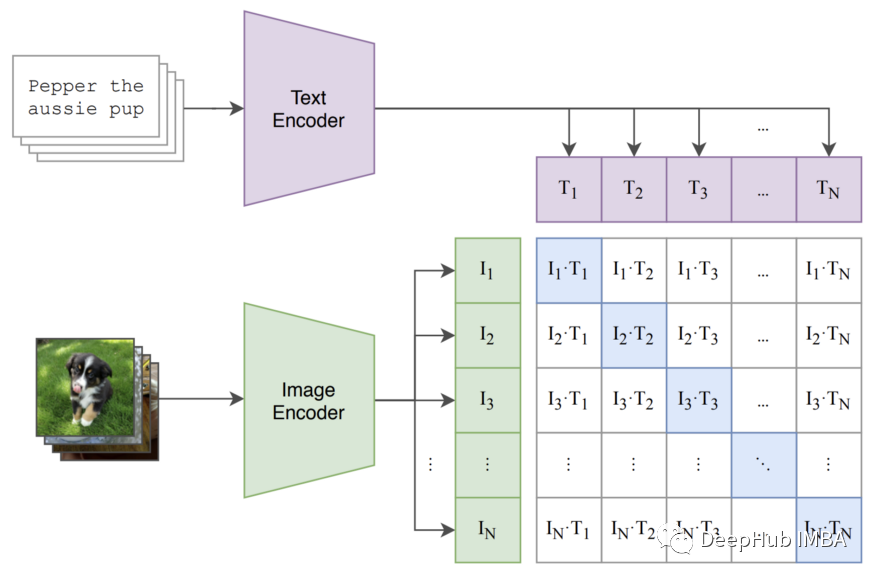
在实践中,通过以下方式实现:
- 通过它们各自的编码器传递一组图像和文本标题
- 最大化真实图像-标题对的图像和文本嵌入之间的余弦相似度
- 最小化所有其他图像-字幕对之间的余弦相似度
这样的目标被称为多类 N 对(或 InfoNCE)损失 [10],通常应用于对比和度量学习中的问题。作为这个预训练过程的结果,CLIP 为图像和文本形成了一个联合嵌入空间,讲相似概念对应到了图像和字幕的嵌入。
更好的任务=更快的学习。通过使用这种更简单的代理任务训练CLIP模型,作者观察到训练效率提高了4倍;如下图所示。
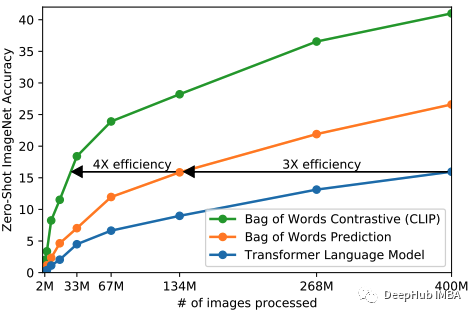
训练效率是使用ImageNet上的零样本学习的迁移率来衡量的。也就是说,当使用这个简单的目标时CLIP 模型需要更少的训练时间(就观察到的图像-文本示例的数量而言)来实现在 ImageNet 上产生高零样本精度的模型。因此,正确选择训练目标会对模型的效率和性能产生巨大影响。
如何在没有训练样本的情况下对图像进行分类?
CLIP 执行分类的能力最初似乎是个谜。鉴于它只从非结构化的文本描述中学习,它怎么可能泛化到图像分类中看不见的对象类别?
CLIP 被训练来预测图像和文本片段是否配对在一起。这种能力可以重新用于执行零样本分类。特别是通过利用未见类的文本描述(例如,类名),可以通过将文本和图像通过各自的编码器并比较生成的嵌入来评估每个候选类;例如下面的图例:
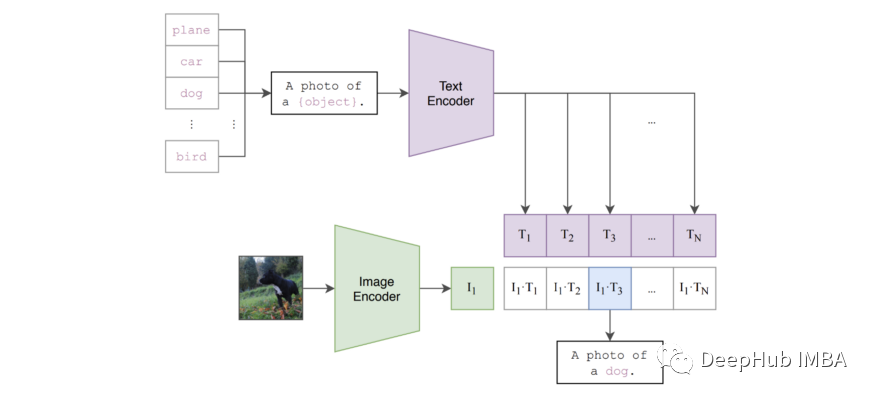
将该过程总结如下,零样本分类实际上包括以下步骤:
- 计算图像特征嵌入
- 从相关文本(即类名/描述)中计算每个类的嵌入
- 计算图像类嵌入对的余弦相似度
- 归一化所有相似性以形成类概率分布
这种方法也有一些局限性:类的名称可能缺乏揭示其含义的相关上下文(即多义问题),一些数据集可能完全缺乏元数据或类的文本描述,并且对图像的描述可能只有一个单词。所以可以通过制作“提示”以文本方式表示不同的类别或创建多个零样本分类器的集合来缓解此类问题;见下图。
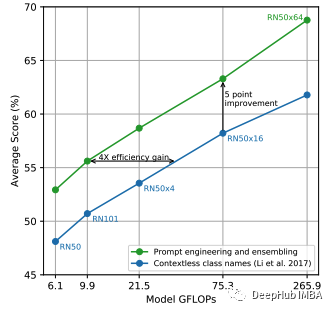
当 (i) 提示用于生成类嵌入和 (ii) 零样本分类器的集合用于预测时,CLIP 实现了改进的性能
然而这种方法仍然存在根本性的限制,并且必须解决这些限制才能提高零样本学习能力。
CLIP 实践——无需训练数据的准确分类!
在原始论文中,CLIP 在零样本域中进行评估,并添加了微调(即少样本或完全监督域)。在这里我将概述使用 CLIP 进行的这些实验的主要发现,并提供有关何时可以使用 CLIP 以及何时不能使用 CLIP 来解决给定分类问题的相关详细信息。
零样本领域,CLIP 取得了突破性的成果,将 ImageNet 上最先进的零样本测试准确率从 11.5% 提高到 76.2%
当将 CLIP 的零样本性能与以预先训练的 ResNet50 特征作为输入的全监督线性分类器的性能进行比较时,CLIP 继续在各种数据集上取得显着的结果。也就是说CLIP 在所研究的 27 个数据集中的 16 个上优于线性分类器(完全监督!)。
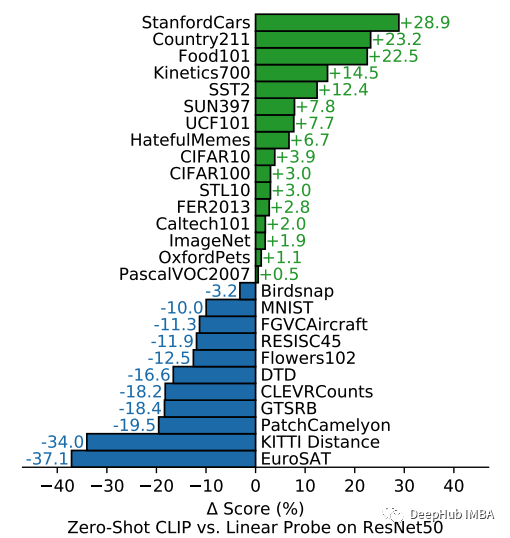
当分析每个数据集的性能时,很明显 CLIP 在一般对象分类数据集(例如 ImageNet 或 CIFAR10/100)上表现良好,甚至在动作识别数据集上表现更好。直观地说,此类任务的良好性能是由于 CLIP 在训练期间接受的广泛监督以及图像说明通常以动词为中心的事实,因此与动作识别标签的相似性比与数据集中使用的以名词为中心的类(如ImageNet )。有趣的是,CLIP 在复杂和专业的数据集(如卫星图像分类和肿瘤检测)上表现最差。
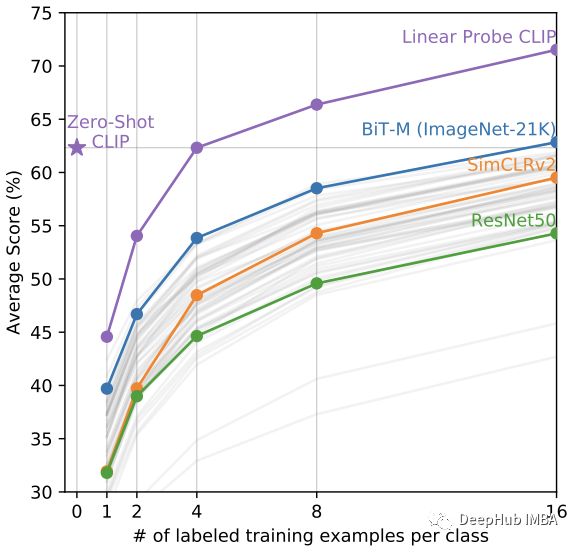
CLIP 的零样本和少样本性能也与其他少样本线性分类器进行了比较。在观察每个类中的四个训练示例后,发现零样本 CLIP 与少样本线性分类器的平均性能相匹配。此外,当允许观察训练示例本身时,CLIP 优于所有小样本线性分类器。这些结果总结在下图中。
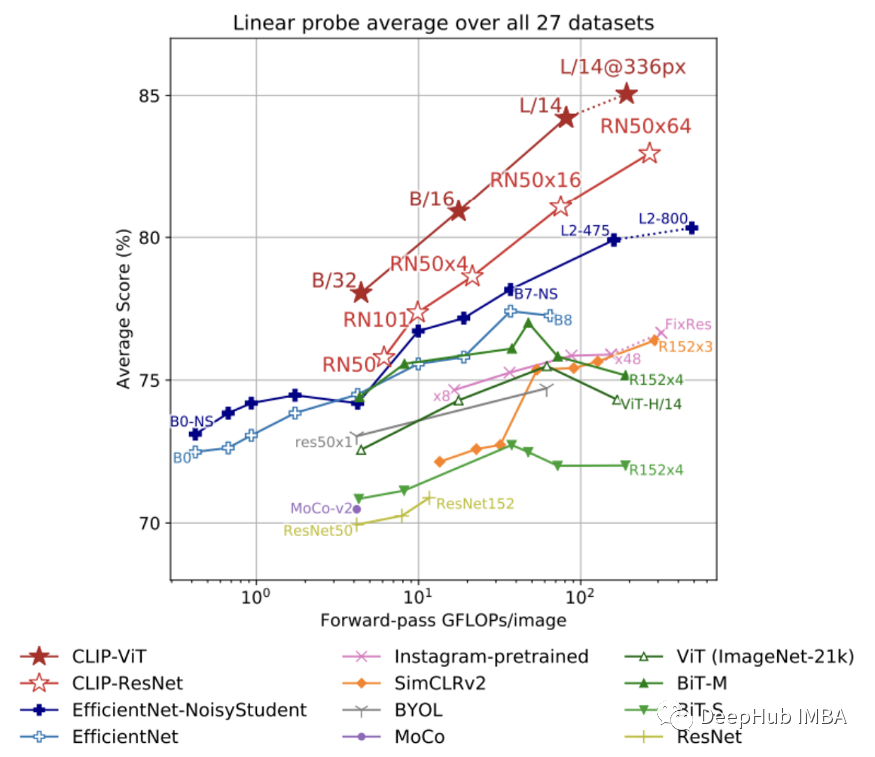
当使用 CLIP 特征训练一个完全监督的线性分类器时,发现它在准确性和计算成本方面都优于许多基线,可以看出 CLIP 通过自然语言监督学习的表示的质量是很高的;见下图。
尽管 CLIP 的性能并不完美(只适用于对每个类别具有良好文本描述的数据集),但 CLIP 实现的零样本和少样本结果预示着的确是可以获得一个高质量的图像和文本的联合嵌入空间。CLIP 为此类通用分类方法提供了初始(令人印象深刻的)概念证明。
CLIP的影响和要点总结
毫无疑问,CLIP 彻底改变了零样本图像分类领域。尽管先前在语言建模方面的工作表明,可以将非结构化输出空间(例如,像 GPT-3 [11] 等文本到文本语言模型)用于零样本分类目的,但 CLIP 扩展了这些结果一种适用于计算机视觉的方法,并且将整个训练过程基于易于获得的图像文本描述。下图提供了 CLIP 及其贡献的摘要。

CLIP 也证明了自然语言提供了足够的训练信号来学习高质量的感知特征。这样的发现对深度学习研究的未来方向产生了重大影响。特别是图像的自然语言描述比遵循特定任务本体的图像注释(即用于分类的传统标签)更容易获得。因此为 CLIP 风格的分类器注释训练数据更具可扩展性,特别是因为许多图像-文本配对可以免费在线下载。
但CLIP 也有一些限制,主要总结如下:在分类问题中获得每个类的良好文本嵌入是困难的,并且复杂/特定的任务(例如,肿瘤检测或预测图像中对象的深度)难以通过学习通用自然语言监督。尽管如此,CLIP 学习的表示是高质量的,可以通过对预训练过程中观察到的数据的修改,提高更专业任务的性能。
如果有兴趣利用 CLIP 生成的高质量图像-文本嵌入,OpenAI 已发布该模型的 python 包。在这个包中,下载不同版本的 CLIP(即,使用VIT或 ResNet 风格的图像编码器和不同大小模型)该包使用 PyTorch 实现, 只需使用 pip 下载包并检查/下载可用的预训练模型。
import clip
available_models = clip.available_models()
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load(available_models[0], device=device)
引用
[1] Radford, Alec, et al. “Learning transferable visual models from natural language supervision.” International Conference on Machine Learning. PMLR, 2021.
[2] Li, Ang, et al. “Learning visual n-grams from web data.” Proceedings of the IEEE International Conference on Computer Vision. 2017.
[3] Joulin, Armand, et al. “Learning visual features from large weakly supervised data.” European Conference on Computer Vision. Springer, Cham, 2016.
[4] Desai, Karan, and Justin Johnson. “Virtex: Learning visual representations from textual annotations.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2021.
[5] Sariyildiz, Mert Bulent, Julien Perez, and Diane Larlus. “Learning visual representations with caption annotations.” European Conference on Computer Vision. Springer, Cham, 2020.
[6] Zhang, Yuhao, et al. “Contrastive learning of medical visual representations from paired images and text.” arXiv preprint arXiv:2010.00747 (2020).
[7] He, Kaiming, et al. “Deep residual learning for image recognition.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
[8] Tan, Mingxing, and Quoc Le. “Efficientnet: Rethinking model scaling for convolutional neural networks.” International conference on machine learning. PMLR, 2019.
[9] Dosovitskiy, Alexey, et al. “An image is worth 16x16 words: Transformers for image recognition at scale.” arXiv preprint arXiv:2010.11929 (2020).
[10] Sohn, Kihyuk. “Improved deep metric learning with multi-class n-pair loss objective.” Advances in neural information processing systems 29 (2016).
[11] Brown, Tom, et al. “Language models are few-shot learners.” Advances in neural information processing systems 33 (2020): 1877–1901.
作者:Cameron Wolfe