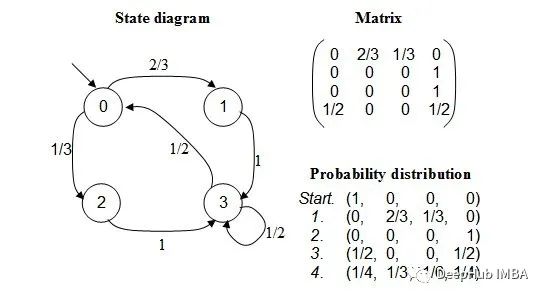
使用马尔可夫链构建文本生成器
本文中将介绍一个流行的机器学习项目——文本生成器,你将了解如何构建文本生成器,并了解如何实现马尔可夫链以实现更快的预测模型。
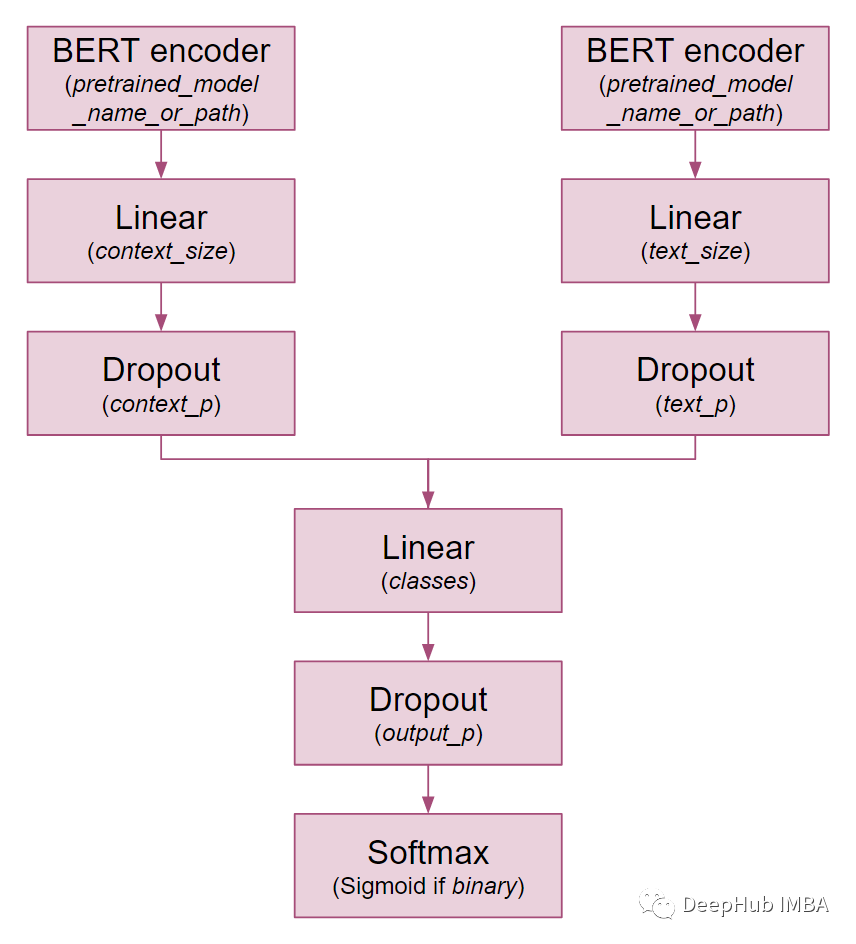
TwoModalBERT进行角色分类
魔改模型,不一定有用,但很好玩
BertTokenizer 使用方法
BertTokenizer 使用方法,BertTokenizer 函数详解,tokenizer使用方法
注意力机制详解
注意力机制
【自然语言处理(NLP)】基于GRU实现情感分类
【自然语言处理(NLP)】基于GRU实现情感分类,基于百度飞桨开发,参考于《机器学习实践》所作。
NLP(自然语言处理)
目前存在的问题有两个方面:一方面,迄今为止的语法都限于分析一个孤立的句子,上下文关系和谈话环境对本句的约束和影响还缺乏系统的研究,因此分析歧义、词语省略、代词所指、同一句话在不同场合或由不同的人说出来所具有的不同含义等问题,尚无明确规律可循,需要加强语用学的研究才能逐步解决。对大规模文档进行索引。自
【关系抽取】深入浅出讲解实体关系抽取(介绍、常用算法)
关系抽取(Relation Extraction,简称RE)的概念是1988年在MUC大会上提出,是信息抽取的基本任务之一,目的是为了识别出文本实体中的目标关系,是构建知识图谱的重要技术环节。知识图谱是语义关联的实体,它将人们对物理世界的认知转化为计算机能够以结构化的方式理解的语义信息。关系抽取通过
自注意力机制(Self-Attention)
自注意力机制
人工智能 —— 知识图谱
概念缩写全称音标含义AIArtificial Intelligence[ˌɑ:tiˈfiʃəl inˈtelidʒəns]人工智能MLMachine Learning[məˈʃi:n ˈlə:niŋ]机器学习DLDeep Learning[diːp ˈlə:niŋ]深度学习CVComputer Vi
竞赛:汽车领域多语种迁移学习挑战赛(科大讯飞)
国内车企为提升产品竞争力、更好走向海外市场,提出了海外市场智能交互的需求。但世界各国在“数据安全”上有着严格法律约束,要做好海外智能化交互,本土企业面临的最大挑战是数据缺少。本赛题要求选手通过NLP相关人工智能算法来实现汽车领域多语种迁移学习。.........
Bert+LSTM+CRF命名实体识别pytorch代码详解
Bert+LSTM+CRF命名实体识别从0开始解析源代码。理解原代码的逻辑,具体了解为什么使用预训练的bert,bert有什么作用,网络的搭建是怎么样的,训练过程是怎么训练的,输出是什么调试运行源代码NER目标NER是named entity recognized的简写,对人名、地名、机构名、日期时
自然语言处理—文本分类综述/什么是文本分类
最近在学习文本分类,读了很多博主的文章,要么已经严重过时(还在一个劲介绍SVM、贝叶斯),要么就是机器翻译的别人的英文论文,几乎看遍全文,竟然没有一篇能看的综述,花了一个月时间,参考了很多文献,特此写下此文。思维导图https://www.processon.com/mindmap/61888043
Encoder-Decoder 模型架构详解
文章目录概述Seq2Seq( Sequence-to-sequence )Encoder-Decoder的缺陷Attention 机制的引入Transformer中的Encoder-Decoder概述Encoder-Decoder 并不是一个具体的模型,而是一个通用的框架。Encoder 和
【实体识别】深入浅出讲解命名实体识别(介绍、常用算法)
命名实体识别(Named Entity Recognition, 简称NER)(也称为实体识别、实体分块和实体提取)是信息提取的一个子任务,旨在将文本中的命名实体定位并分类为预先定义的类别,如人员、组织、位置、时间表达式、数量、货币值、百分比等。命名实体识别是自然语言处理中的热点研究方向之一, 目的
TF-IDF算法(原理+python代码实现)
目录前言一、TF-IDF的由来二、什么是TF-IDF?2.1 TF(Term Frequency)2.2 IDF(Inverse Document Frequency)2.3TF-IDF(Term Frequency-Inverse Document Frequency)三、TF-IDF应用四、代码
【Spark NLP】第 6 章:信息检索
在上一章中,我们遇到了难以描述语料库的常用词。这是不同种类的 NLP 任务的问题。幸运的是,信息检索领域已经开发了许多可用于改进各种 NLP 应用的技术。早些时候,我们谈到了文本数据是如何存在的,并且每天都在生成更多。我们需要一些方法来管理和搜索这些数据。如果有 ID 或标题,我们当然可以对这些数据
【Spark NLP】第 7 章:分类和回归
对文档执行的最常见的机器学习任务是分类和回归。从确定临床记录的保险计费代码(分类)到预测社交媒体帖子的受欢迎程度(回归),大多数文档级机器学习任务都属于这些类别之一,而分类是两者中更为常见的一种。在开始机器学习任务时,尝试手动标记一些文档是非常有用的,即使数据集中已经有标签。这将帮助您了解可以在您的
【Spark NLP】第 9 章:信息提取
如果我们使用模型方法,事情可能会有点模糊,因为模型可以识别可能不完全出现在我们的数据库中的名称。另一方面,考虑到“可能导致头晕”的医学示例,我们可能不想将描述该患者的短语包含在患有头晕的患者集中。还有一些其他的例外,主要是在上下文中合适的非专有名词短语——例如,像“牛仔队”这样的运动队。事实上,如果
【Spark NLP】第 5 章:处理词
本章重点介绍可用于 NLP 入门的基本文字处理技术,包括标记化、词汇缩减、词袋和 N-gram。您可以使用这些技术以及一些基本的机器学习来解决许多任务。了解如何、何时以及为何使用这些技术将帮助您完成简单和复杂的 NLP 任务。这就是语言学技术的讨论涵盖实现的原因。我们现在将专注于使用英语,尽管我们会
【自然语言处理(NLP)】基于FNN网络的电影评论情感分析
【自然语言处理(NLP)】基于FNN网络的电影评论情感分析,基于百度飞桨开发,参考于《自然语言处理实践》所作。



