
大家好,欢迎来到《分享本周所学》第二期。本人是一名人工智能初学者,最近一周学了一下Transformer这个特别流行而且特别强大的模型,觉得非常有收获,就想用浅显易懂的语言让大家对这个超级神器有所了解。然后因为我也只是一名小白,所以有错误的地方还希望大佬们多多指正。
其实这周我还干了一点别的事,就是自己在虚拟机上配置了一个Ubuntu的GPU环境,然后在里面做了一个AI实时语音识别的小程序。其实这是我第一次真正接触Linux系统,之前只是瞎玩一玩,甚至没有在命令行里用过任何指令,连从网上复制下来的都没有,所以这个过程中其实也遇到了很多困难,也有很多收获可以分享,但是加上这些内容的话这次的篇幅就太长了,所以如果有想看的朋友可以在评论区告诉我,我会放在下期。
上期文章链接:
《分享本周所学——人工智能语音识别模型CTC、RNN-T、LAS详解》https://blog.csdn.net/weixin_48978134/article/details/125455764
本期封面:

Transformer是咋回事啊
Transformer这个模型应该说是AI界所有模型中热度和性能的天花板了,它已经火到随便找一个搜索引擎去搜Transformer都很难找到有关变形金刚的内容,全是关于这个AI模型的东西。尽管最近两年有一些像Conformer和Informer这样的改进版,但也只不过是在Transformer的框架上作作修改,真正的强者还得是Transformer。那听到这里有朋友可能就要问了,为什么这个玩意叫Transformer啊,它和变形金刚有任何的关系吗?
这就不得不提到transformer这个词本来的意思了。
然后我就找了张变压器的图:

再看看最知名的那张Transformer的结构图:

好像、似乎、大概、也许有那么一点接近?
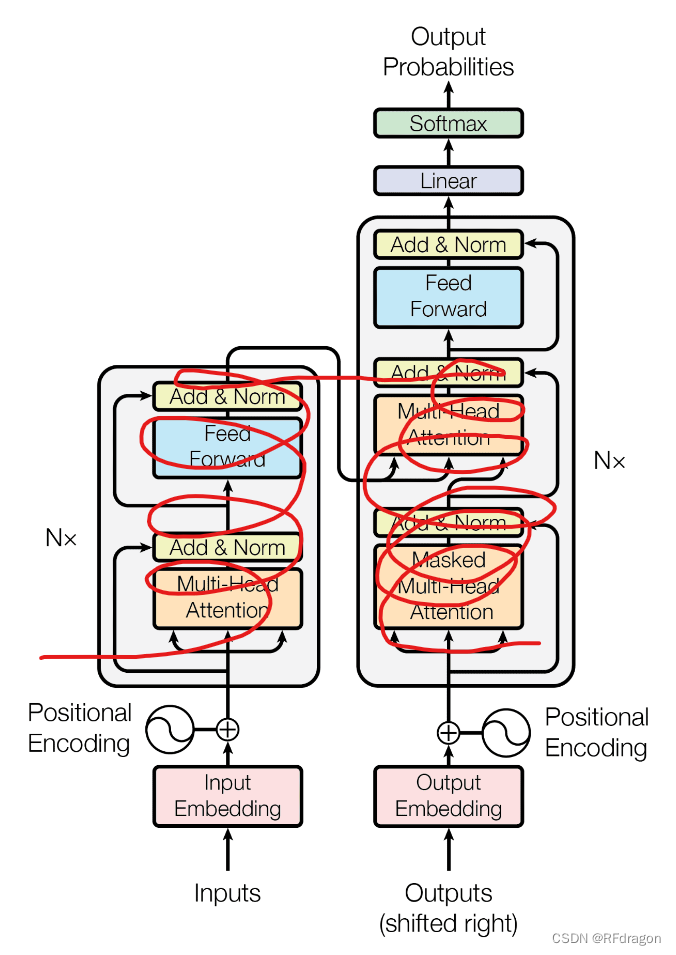
算了,还是不纠结这个了。那接下来,我就带着大家一个一个地看看Transformer这张结构图上的每个模块都是什么东西,它们合起来又是怎么运作的。然后因为现在Python的各种人工智能库基本上都有封装好的Transformer类和其中的子模块,所以我就不放代码了,如果大家在自己的代码里需要用到Transformer的话,我还是比较推荐大家直接用封装好的。
1. Multi-Head Attention
相信大家都有所耳闻,Transformer那篇论文的题目就叫《Attention is All You Need》,所以这也就意味着这个Multi-Head Attention是整个Transformer的核心,其他结构都只是辅助。Attention大家应该都有所了解,如果没有了解也没关系,我在下面1.1这节就会和大家聊聊Attention是怎么回事。但是Multi-Head Attention是怎么一回事呢?大家可能会想一个Attention长出好多个头,这是什么意思啊,不明不白的。但其实Multi-Head Attention的结构非常简单,和一般的Attention差不了多少。
1.1 Attention
我们从普通Attention的结构开始说起,已经有了解的朋友们可以跳过这部分,直接看下面1.3的Multi-Head。
顾名思义,Attention其实就是注意力。那注意力和AI有什么关系呢?举个例子,假设我们现在正在做一个AI翻译的任务,我们想塞给AI一句中文,让它翻译成英文输出出来,然后我们现在扔给AI一句涉及到人体消化系统和人体能量获取机制等多方面专业领域的中文:
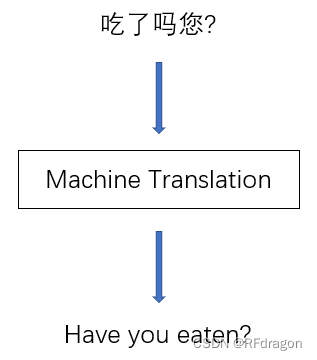
我们可以看到,“吃了吗您”翻译出来是“Have you eaten”,这里有个很有意思的情况啊,我们发现“吃”这个原本在句首的动词在经过翻译之后变成了句尾的“eaten”。而我们又知道,一般的循环神经网络,比如LSTM,它处理语言的方式都是从前往后,从句首往句尾处理,这样一来,尽管LSTM有能控制学习和遗忘的各种稀奇古怪的门,但是还是难免在处理比较长的句子的过程中处理着处理着就把句首的那点东西给忘了,然后大概就是:
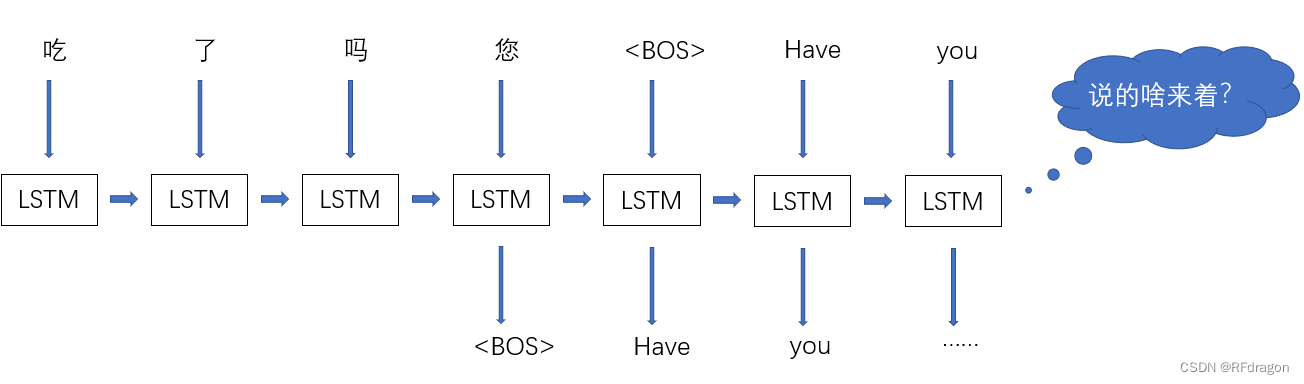
这个时候,我们就应该告诉AI,你在翻译出来“you”之后就很自然地应该把注意力放在一个动词上啊,你去注意一下那个“吃”好不好?
那怎么实现让AI具有注意力呢?其实想法很简单,我们每翻译完一个词之后,都让模型给所有输入的词打个分,得分高的词就会在翻译下一个词的时候被给予更多的注意力。比如说模型已经翻译完了“you”,那“you”在词性上应该算个名词,那么名词搭配动词是比较常见的,所以模型就很可能会在翻译完“you”之后给“吃”这个动词打高分。
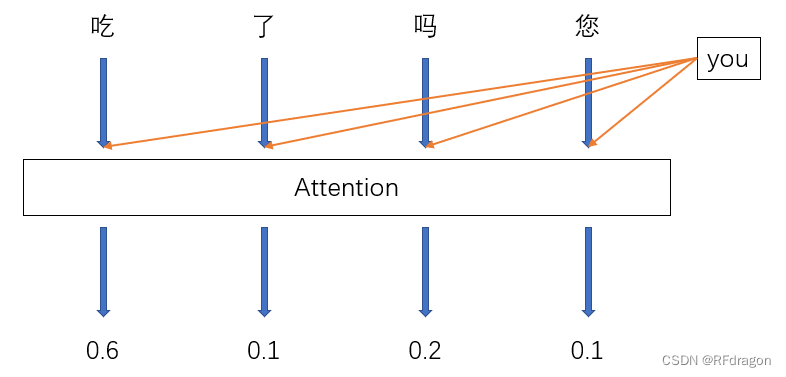
然后我们把Attention给出来的得分扔给神经网络,那它就会重点关照一下这个“吃”。
然后问题来了,模型是怎么知道名词之后应该接动词呢?这其实是神经网络训练出来的。比如说我们把输入的每个词所对应的Embedding向量和“you”所对应的向量拼起来,然后过一个全连接神经网络,让神经网络输出一个得分,再把所有得分过一个Softmax,转换为权重,那经过训练之后,神经网络自然就会给出合理的权重,就像上面所说的,翻译完名词之后给到动词的权重很可能就会高一点。然后我们把所有输入的词的Embedding根据Attention给出的权重做一个加权平均,就会得到一个包含所有输入词的信息的向量,并且那些比较关键的词的信息会更多地被包含进来,因为它们被赋予了更高的权重。这样,我们在让神经网络进行翻译的时候,就相当于提醒神经网络说:“我怕你把前面输入的词忘了,就把所有词的信息打包在这送给你了,并且这里面会有更多关于‘吃’的信息,你重点注意一下。”
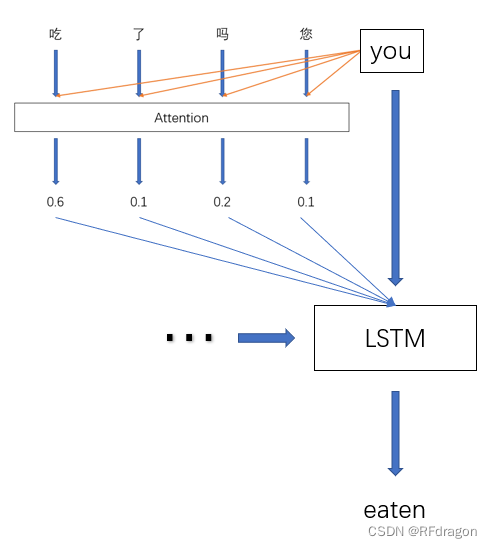
当然,计算Attention权重的方式其实非常灵活,直接用全连接神经网络是一个好办法,但是也可以不用,比如说可以计算上个翻译好的词(也就是上图中的“you”)和输入的每个词之间的余弦相似度或者点积,这些都是可行的,神经网络会自然而然地根据你计算Attention的方法进行调整。另外也不一定是直接用输入词的Embedding去计算Attention,而是先对这些Embedding预处理一下,比如说先让它们过一个encoder,然后用过完encoder之后得到的结果去算Attention,这样通常会有更好的效果。
1.2 Self-Attention
说到Multi-Head Attention,就不得不提到Self-Attention。那朋友们可能又会问了,这Self-Attention又是什么啊?自己注意自己?这模型自恋吗?
其实Self-Attention非常简单啊,和普通的Attention基本没有区别。我们来看一个例子,假设我要提高一个翻译模型的准确率,我们希望在开始翻译之前先用一个encoder对输入的句子进行一些预处理,然后我们想:“欸要不在encoder里加个Attention吧。”但是有个问题啊,我们上面是拿一个翻译好的词去和输入的句子算Attention,但是现在我们还没开始翻译呢,该拿什么去和这个句子算Attention呢?
额,那只好让这句话自己跟自己算Attention了。
我们还用上面“吃了吗您”的例子,假设我正在把“吗”这个字过encoder,然后我们想动用一下Attention这个高级玩意。那其实这个算Attention的过程很简单啊,和上面完全一样,只不过把上面的图里的“you”换成“吗”。

这就是Self-Attention,就这么简单。但是问题来了,我们为什么要在encoder里让一个句子自己和自己算Attention啊,这有什么用吗?我们可以看这样一个例子:“我不能用手机打炉石,它没电了。”那这个句子里的“它”指代的是什么呢?是“手机”还是“炉石”?显然是手机,因为只有手机才可能“没电了”。因此,我们在用encoder对“它”这个字作预分析的时候,就希望模型能多关注“手机”而不是“炉石”。为了达到这个目的,我们就可以用Self-Attention赋予“手机”较多的权重,把“它”和“手机”关联起来。
1.3 Multi-Head
现在到了关键的Multi-Head部分。其实Multi-Head的原理也特别简单啊。我们继续来看上面那句话:“我不能用手机打炉石,它没电了。”我们在把“它”过encoder的时候,可能不仅仅要关注“手机”的信息,还要关注“没电”的信息,而且还不能忽略了“它”这个字原有的信息。也就是说,我们可能要让一个字用Attention关联上三个不同的词,这个任务对于Attention来说可能比较难。那怎么办呢?很简单啊,我们像给CNN加通道数那样,也给Attention加通道数不就完了吗?

如上图所示,我们可以把“它”和输入序列分别做三次Self-Attention,并把得到的结果拼起来。因为三个Attention内神经网络的权重不同,所以它们很可能会注意到不同的信息,从而把“它”的信息和不同的位置关联起来。所以啊,我理解它之所以叫做Multi-Head就是因为这种Attention好像有好多个脑袋一样,每个脑袋注意输入的句子中的一部分关键位置,然后所有的脑袋合起来就可以注意到更多位置。这就是Multi-Head Attention,真的很简单。
1.4 Masked Multi-Head Attention
我们可以看到结构图的右下角有一个Multi-Head Attention前面加了个“Masked”,那什么叫“Masked”呢?是不是因为疫情的原因,连Attention都要戴个口罩?并不是,其实这个Mask就是一个方便模型训练的小技巧。众所周知啊,机器翻译是需要AI一个一个地输出翻译出来的词,而不是一口气就完成所有词的翻译,比如我想翻译“我不能用手机打炉石,它没电了”这句话,我们在把这句话过完encoder之后,需要让decoder一个词一个词地输出翻译结果。
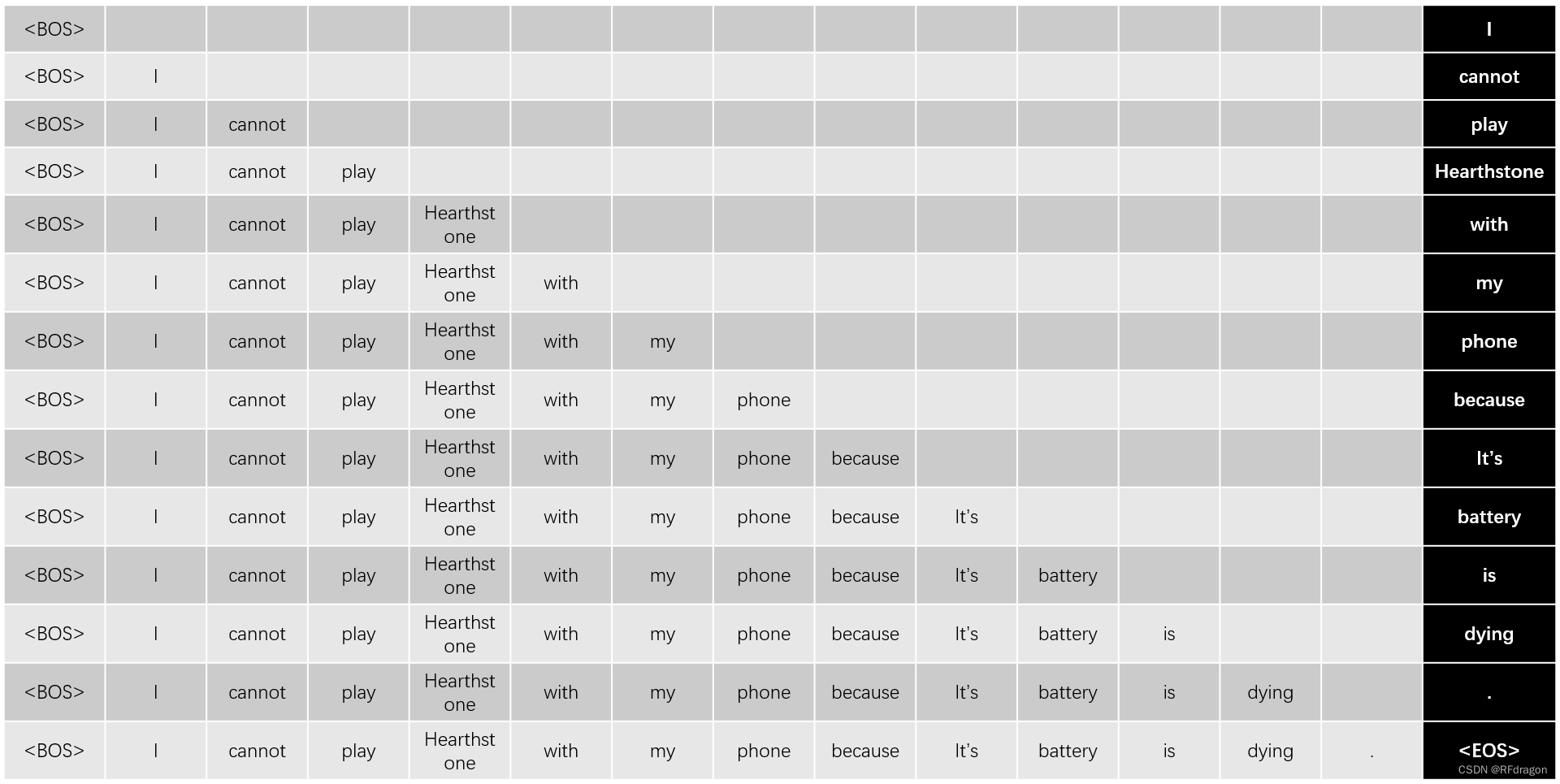
如上图所示,我们先把一个代表翻译开始的标记<BOS>(Beginning of Sequence)塞进decoder,让它根据<BOS>和encoder的输出翻译出“I”,然后再把“<BOS> I”放进decoder,让它根据encoder的输出翻译出“cannot”,再把“<BOS> I cannot”放进decoder,让它输出“play”……最后,我们把“<BOS> I cannot play Hearthstone with my phone because it's battery is dying”(以下简称为“最终输入”)放进encoder,让它输出<EOS>(End of Sequence),表示翻译结束。但是在训练的时候,如果一个词一个词地翻译效率太低。因此,既然我们已经知道了翻译的正确答案,我们可以把“<BOS>”、“<BOS> I”、“<BOS> I cannot”……“最终输入”延batch维度拼接成单个输入,作为一个batch扔进decoder,这样decoder就可以用一次计算完成所有词的翻译。这个batch其实就是上图把最右边黑色的那一列去掉。但是这个截取输出然后拼接的过程比较麻烦,所以我们可以把这个batch中的所有输入都用“最终输入”代替,如下图所示:
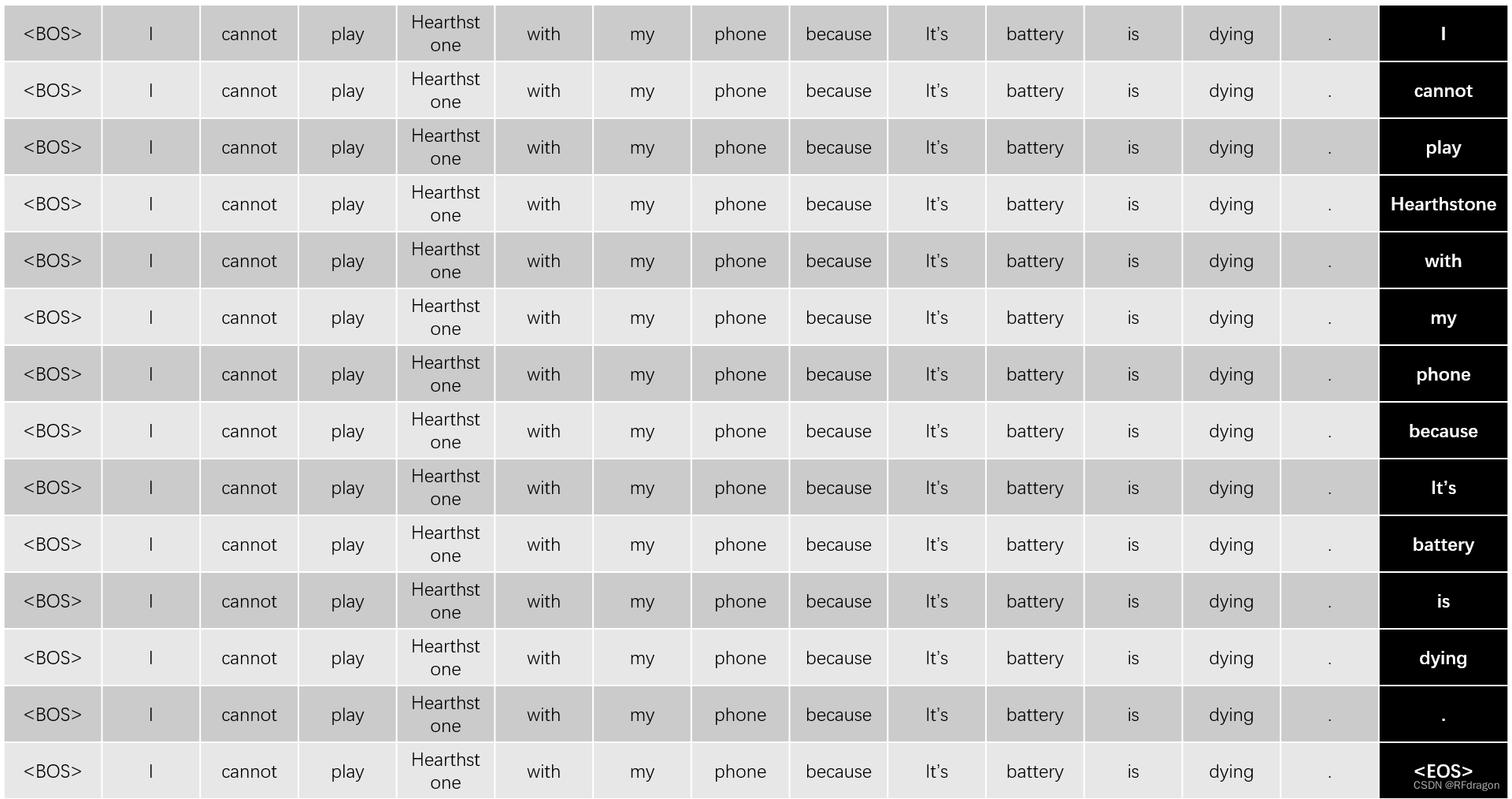
但是问题来了,在翻译第一个词(也就是“I”)的时候,模型应该只接受到“<BOS>”这一个词的信息,但是它实际接收到的是“最终输入”,这里面包含了很多模型在翻译“I”的时候不应该得到的信息。怎么办呢?
这就要靠这个Mask来解决了。其实Mask本质上就是让decoder中的Attention注意不到它不应该得到的信息。怎么实现这个功能呢?其实很简单。Attention里不是有个Softmax吗,我们先对输入的每个词打分,打完分之后通过Softmax才能得到最终权重。如果我们给所有不想让模型看到的输入的得分加上负无穷大,那这些得分通过Softmax之后,算出的权重应该会趋近于0。这样一来,模型的Attention就完全不会注意到这些词,那它们也就对模型的输出没有影响了。下面这个矩阵就是所谓的“Mask”:
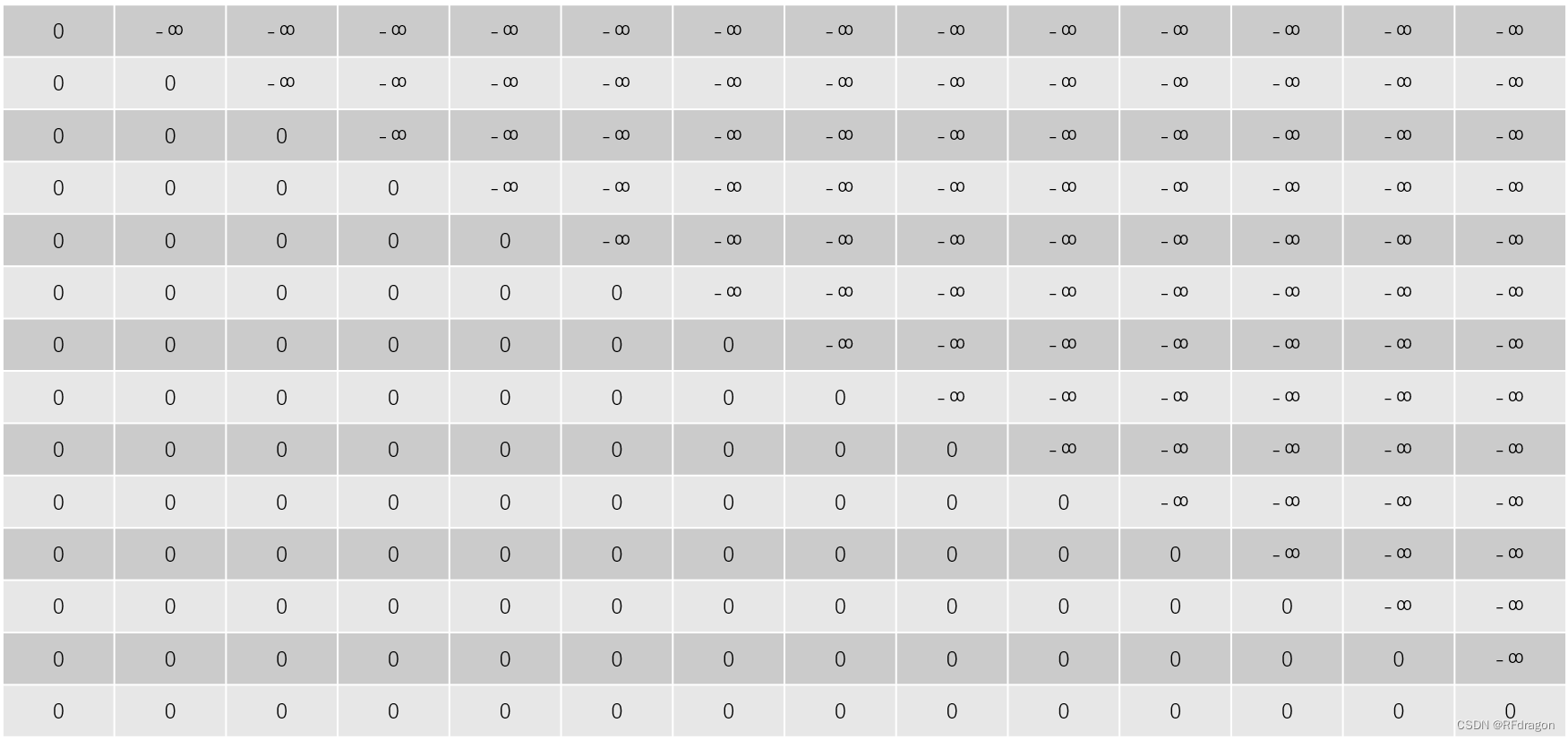
这个矩阵的每一行对应batch中的其中一个输入。虽然看起来十分简单,但是它的作用还是很大的,因为只要把这个矩阵和Attention的打分相加,之后在过Softmax的时候,那些我们不想让模型看到的内容就会被自动忽略掉。所以,有了这个Mask机制,我们就可以大幅加快模型的训练。当然,在验证、测试和应用的时候我们不能用这个Mask,因为我们不能给模型提供最终的正确答案,所以只能继续让decoder一个词一个词地翻译。
2. Add & Norm
为了方便阅读,这里重新贴一下Transformer的结构图。
我们可以发现啊,几乎所有的模块之后都会跟一个“Add & Norm”。那什么叫Add & Norm呢?故名思意,Add就是加,把一个模块的输入和输出像ResNet那样加起来,可以起到辅助梯度传播的作用。Norm就是Normalization,把前面Add那一步得到的结果作归一化。然后就完事了。
3. Positional Encoding
我们可以发现,Transformer的encoder和decoder部分的输入都含有一个Positional Encoding。有的朋友可能不知道什么是Positional Encoding啊,其实就是把输入的一个字的位置作个编码。比如说“我不能用手机打炉石,它没电了”这句话,“我”是第一个字,那我就把1这个数字用一些方法作个处理,就得到了“我”的Positional Encoding。至于具体怎么encode,其实办法也有很多,其中一种办法就是不encode,直接使用一个字出现的位置,“我”就是1,“不”就是2,以此类推。另一种办法就是“我”是0,句尾的“了”是1,所有字均匀分布在0和1之间。这些办法都是可行的,但是也都存在问题。假如两句话,一句有10个字,一句有100个字,如果用第一种方法,那第一句的最后一个字的Encoding是10,第二句是100,差了非常多。同样是最后一个字,虽然一个句子长,一个句子短,但两个字的Encoding真的应该差这么多吗?显然不是,因为句子的长度并不能说明两句话的最后一个字之间差的很远。而第二种方法的问题是,两个相邻的字的Encoding之差会参差不齐,第一句话的相邻两个字之间差了0.1,而第二句话只差0.01,这也是不合理的,因为句子长并不意味着相邻的两个字之间的关系就更近。
那解决这个问题的方案就是使用一系列的正弦和余弦函数。众所周知啊,正弦和余弦函数是有周期性的,不管自变量多大,函数值都在[-1, 1]这个区间,这样就可以在保持相邻的字Encoding的差值的情况下不让最后一个字的Encoding数值太大。这时候有朋友就要问了,正弦函数的周期是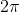,也就是说第一个字、第七个字、第十四个字……的Encoding都是接近的,那我们就没法判断这个字到底在哪了啊。其实这也是为什么我在这段的开头用的词是“一系列”函数而不是“一个”函数。我们可以使用多个周期不同的函数,这里面有些函数的周期只有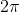那么短,而有些函数可能整句话都没走完一个周期。周期短的函数能够更多地包含一个字和周围其他字的相对位置信息,而周期长的函数可以表示一个字在整句话中的绝对位置信息。这样一来,这个Positional Encoding的问题就得到了较好的解决。 那具体这些函数是怎么设计的我这里就不详细说了,感兴趣的朋友们可以自己去搜一下。
4. 整体来看Transformer
那我们最后再来整体看一下Transformer的结构。首先,先把输入作Embedding,把Embedding和Positional Encoding结合,然后塞进encoder。encoder包含四部分:Multi-Head Attention、Add & Norm、Feed Forward Network和另一个Add & Norm。encoder中的Attention全都是Self-Attention。这里要注意,这四部分是可以被重复很多次的,也就是说输入在经过最后一个Add & Norm之后可以进入一个新的包含这四部分的encoder模块。使用多个encoder模块可以让我们更深入地对输入进行编码。结构图中写的“N×”就是这个意思。
编码结束后,我们对decoder的输入作Embedding,然后结合上Positional Encoding,塞进decoder来进行翻译。关于decoder的输入是什么可以看1.4这节。decoder也可以由很多模块组成,每个模块有六部分:Masked Multi-Head Attention、Add & Norm、Multi-Head Attention、另一个Add & Norm、Feed Forward Network和第三个Add & Norm。这里要注意一下,每个模块中的第一个Attention是对decoder的输入作Self-Attention,而第二个没有Mask的Attention是encoder和decoder之间的Attention而不是Self-Attention,也就是像1.1里那样拿着decoder这边的一个输入去和encoder的每一个输出去打分、算权重。这也就是为什么这个Attention不是Masked Attention。
最终,在得到decoder的输出之后,拿着这个输出去过一个Linear层,再算一下Softmax,就完成了一次翻译。当然,Transformer不止应用于翻译,它具有很强的普适性,能够胜任AI各种领域的各种任务,的确是一个名副其实的强大模型。
5. Transformer与CNN、RNN的优劣势分析
Transformer虽然很强,但是这也不意味着它是完美无缺的。完全抛弃CNN和RNN结构并一味地追求“Attention is All You Need”是注定要付出代价的。

那么古尔丹,代价是什么呢?我们不妨先看看CNN和RNN各有什么优点。
CNN的优点就是能够非常好地提取局部的信息,因为每次卷积运算只会根据很小一部分信息得出结果。而Transformer则放弃了CNN的这一优点,因为Attention运算是在全局范围内寻找需要被注意的内容。这就大大增加了提取有效信息的难度。那之后的Conformer模型也是对这个缺陷作出了改进,把CNN重新融进Transformer中,这也确实提升了模型的性能。
而RNN的优点显然就是能够获取到输入序列的时间顺序相关信息。Transformer显然不具备这个优点,因为Attention内的网络参数不会像RNN那样因为输入的词的时间顺序而改变。这确实是在自然语言相关任务中的一个很致命的缺陷。Transformer对输入进行Positional Encoding可以缓解这个问题,但是还是不能从本质上解决它。
但是Transformer的优点却完全可以弥补这些缺陷,因为Multi-Head Attention这个奇妙的设计真的是太万能了,不管是处理图像还是音频都能够很有效地提取出那些值得注意的信息,而弱化相关性较低的信息,大大增强了模型的特征提取能力。
本文转载自: https://blog.csdn.net/weixin_48978134/article/details/125567184
版权归原作者 RFdragon 所有, 如有侵权,请联系我们删除。
版权归原作者 RFdragon 所有, 如有侵权,请联系我们删除。