
将自然语言转换为SQL语句已经不再遥不可及。NLP的进步使得我们不仅可以使用LLM(大型语言模型),还可以通过微调教授他们新的技能,这也被称为迁移学习。可以使用一个预先训练的模型作为起点,然后使用较小的标记数据集从而获得比单独使用数据训练更好的性能。

在本文中,我们将使用谷歌的文本到文本生成模型T5和我们的自定义数据进行迁移学习,这样它就可以将基本问题转换为SQL查询。我们将在T5中添加一个名为:将英语翻译为SQL的新任务,它可以转换以下示例查询:
Cars built after 2020 and manufactured in Italy
将输出一下SQL语句
SELECT name FROM cars WHERE location = 'Italy' AND date > 2020
创建训练数据
与翻译数据集不同,我们可以在模板的帮助下以编程方式自动构建训练的数据集,下面是整理出来的一些模板:
templates = [
["[prop1] of [nns]","SELECT [prop1] FROM [nns]"],
["[agg] [prop1] for each [breakdown]","SELECT [agg]([prop1]) , [breakdown] FROM [prop1] GROUP BY [breakdown]"],
["[prop1] of [nns] by [breakdown]","SELECT [prop1] , [breakdown] FROM [nns] GROUP BY [breakdown]"],
["[prop1] of [nns] in [location] by [breakdown]","SELECT [prop1] , [breakdown] FROM [nns] WHERE location = '[location]' GROUP BY [breakdown]"],
["[nns] having [prop1] between [number1] and [number2]","SELECT name FROM [nns] WHERE [prop1] > [number1] and [prop1] < [number2]"],
["[prop] by [breakdown]","SELECT name , [breakdown] FROM [prop] GROUP BY [breakdown]"],
["[agg] of [prop1] of [nn]","SELECT [agg]([prop1]) FROM [nn]"],
["[prop1] of [nns] before [year]","SELECT [prop1] FROM [nns] WHERE date < [year]"],
["[prop1] of [nns] after [year] in [location]","SELECT [prop1] FROM [nns] WHERE date > [year] AND location='[location]'"],
["[nns] [verb] after [year] in [location]","SELECT name FROM [nns] WHERE location = '[location]' AND date > [year]"],
["[nns] having [prop1] between [number1] and [number2] by [breakdown]","SELECT name , [breakdown] FROM [nns] WHERE [prop1] < [number1] AND [prop1] > [number2] GROUP BY [breakdown]"],
["[nns] with a [prop1] of maximum [number1] by their [breakdown]","SELECT name , [breakdown] FROM [nns] WHERE [prop1] <= [number1] GROUP BY [breakdown]"],
["[prop1] and [prop2] of [nns] since [year]","SELECT [prop1] , [prop2] FROM [nns] WHERE date > [year]"],
["[nns] which have both [prop1] and [prop2]","SELECT name FROM [nns] WHERE [prop1] IS true AND [prop2] IS true"],
["Top [number1] [nns] by [prop1]","SELECT name FROM [nns] ORDER BY [prop1] DESC LIMIT [number1]"]
]
template = random.choice(templates)
print("Sample Query Template :", template[0])
print("SQL Translation :", template[1])
构建函数使用这些模板并生成我们的数据集
objects = ["countries","wines","wineries","tasters", "provinces","grapes","cities","bottles","deliveries"]
object_single = ["country","wine","winery","taster", "province","grape","city","bottle", "delivery"]
properties = ["points","price","taste","title","texture","age","duration","acidity","flavor","level"]
aggs = [["average","avg"], ["total","sum"],["count","count"], ["minimum","min"], ["maximum","max"]]
breakdowns = ["quality","price","province","country","point", "variety","flavor","age"]
locations = ["Italy","US","Portugal","Spain","Chile","Turkey","Canada"]
verbs = ["produced","bottled"]
regex = r"\[([a-z0-9]*)\]"
number_of_samples = 2500
@dataset("english_sql_translations")
def build_dataset():
rows = []
for index in range(0,number_of_samples):
template = random.choice(templates)
nl = template[0]
sql = template[1]
matches = re.finditer(regex, nl, re.MULTILINE)
for matchNum, match in enumerate(matches, start=1):
key = match.group()
prop = None
prop_sql = None
if key.startswith("[prop"):
prop = random.choice(properties)
prop_sql = prop.replace(" ","_").lower()
if key in ["[nns]"]:
prop = random.choice(objects)
prop_sql = prop
if key in ["[nn]"]:
prop = random.choice(object_single)
prop_sql = prop.replace(" ","_").lower()
if key == "[breakdown]":
prop = random.choice(breakdowns)
prop_sql = prop.replace(" ","_").lower()
if key == "[verb]":
prop = random.choice(verbs)
prop_sql = prop.replace(" ","_").lower()
if key == "[agg]":
aggregation = random.choice(aggs)
prop = aggregation[0]
prop_sql = aggregation[1]
if key == "[location]":
prop = random.choice(locations)
prop_sql = prop
if key.startswith("[number"):
prop = str(random.randint(1,1000))
prop_sql = prop
if key.startswith("[year"):
prop = str(random.randint(1950,2022))
prop_sql = prop
if prop is not None:
nl = nl.replace(key,prop)
sql = sql.replace(key,prop_sql)
prefix = random.randint(1,20)
if prefix == 1:
nl = "Show me "+nl
elif prefix == 2:
nl = "List "+nl
elif prefix == 3:
nl = "List of "+nl
elif prefix == 4:
nl = "Find "+nl
rows.append([nl,sql])
df = pd.DataFrame(rows, columns=["query", "sql"])
return df
这里使用了@Dataset装饰器。现在,我们可以将此函数通过以下方式轻松分层:
layer.run([build_dataset])
运行完成后,可以开始构建自定义数据集加载程序
创建数据加载程序
我们的数据集还需要使用Pytorch的Dataset实现,才能够使用Dataloader进行加载
from torch.utils.data import Dataset
class EnglishToSQLDataSet(Dataset):
def __init__(self, dataframe, tokenizer, source_len, target_len, source_text, target_text):
self.tokenizer = tokenizer
self.data = dataframe
self.source_len = source_len
self.target_len = target_len
self.target_text = self.data[target_text]
self.source_text = self.data[source_text]
self.data["query"] = "translate English to SQL: "+self.data["query"]
self.data["sql"] = "<pad>" + self.data["sql"] + "</s>"
def __len__(self):
return len(self.target_text)
def __getitem__(self, index):
source_text = str(self.source_text[index])
target_text = str(self.target_text[index])
source_text = ' '.join(source_text.split())
target_text = ' '.join(target_text.split())
source = self.tokenizer.batch_encode_plus([source_text], max_length= self.source_len, pad_to_max_length=True, truncation=True, padding="max_length", return_tensors='pt')
target = self.tokenizer.batch_encode_plus([target_text], max_length= self.target_len, pad_to_max_length=True, truncation=True, padding="max_length", return_tensors='pt')
source_ids = source['input_ids'].squeeze()
source_mask = source['attention_mask'].squeeze()
target_ids = target['input_ids'].squeeze()
target_mask = target['attention_mask'].squeeze()
return {
'source_ids': source_ids.to(dtype=torch.long),
'source_mask': source_mask.to(dtype=torch.long),
'target_ids': target_ids.to(dtype=torch.long),
'target_ids_y': target_ids.to(dtype=torch.long)
}
微调 T5
数据集已准备就完毕。现在可以开发微调逻辑。用@model对功能进行装饰,然后将其传递给层。
ef train(epoch, tokenizer, model, device, loader, optimizer):
import torch
model.train()
for _,data in enumerate(loader, 0):
y = data['target_ids'].to(device, dtype = torch.long)
y_ids = y[:, :-1].contiguous()
lm_labels = y[:, 1:].clone().detach()
lm_labels[y[:, 1:] == tokenizer.pad_token_id] = -100
ids = data['source_ids'].to(device, dtype = torch.long)
mask = data['source_mask'].to(device, dtype = torch.long)
outputs = model(input_ids = ids, attention_mask = mask, decoder_input_ids=y_ids, labels=lm_labels)
loss = outputs[0]
step = (epoch * len(loader)) + _
layer.log({"loss": float(loss)}, step)
optimizer.zero_grad()
loss.backward()
optimizer.step()
在这里,我们使用三个单独装饰器:
@model:告诉图层使用此函数训练ML模型
@Fabric:告诉层训练模型所需的计算资源(CPU,GPU等)。T5是一个大型型号,我们需要GPU对其进行微调。
@pip_requirements:微调我们的模型所需的Python软件包。
@model("t5-tokenizer")
@fabric("f-medium")
@pip_requirements(packages=["torch","transformers","sentencepiece"])
def build_tokenizer():
from transformers import T5Tokenizer
# Load tokenizer from Hugging face
tokenizer = T5Tokenizer.from_pretrained("t5-small")
return tokenizer
@model("t5-english-to-sql")
@fabric("f-gpu-small")
@pip_requirements(packages=["torch","transformers","sentencepiece"])
def build_model():
from torch.utils.data import Dataset, DataLoader, RandomSampler, SequentialSampler
from transformers import T5Tokenizer, T5ForConditionalGeneration
import torch.nn.functional as F
from torch import cuda
import torch
parameters={
"BATCH_SIZE":8,
"EPOCHS":3,
"LEARNING_RATE":2e-05,
"MAX_SOURCE_TEXT_LENGTH":75,
"MAX_TARGET_TEXT_LENGTH":75,
"SEED": 42
}
# Log parameters to Layer
layer.log(parameters)
# Set seeds for reproducibility
torch.manual_seed(parameters["SEED"])
np.random.seed(parameters["SEED"])
torch.backends.cudnn.deterministic = True
# Load tokenizer from Layer
tokenizer = layer.get_model("t5-tokenizer").get_train()
# Load pretrained model from Hugging face
model = T5ForConditionalGeneration.from_pretrained("t5-small")
device = 'cuda' if cuda.is_available() else 'cpu'
model.to(device)
dataframe = layer.get_dataset("english_sql_translations").to_pandas()
source_text = "query"
target_text = "sql"
dataframe = dataframe[[source_text,target_text]]
train_dataset = dataframe.sample(frac=0.8,random_state = parameters["SEED"])
train_dataset = train_dataset.reset_index(drop=True)
layer.log({"FULL Dataset": str(dataframe.shape),
"TRAIN Dataset": str(train_dataset.shape)
})
training_set = EnglishToSQLDataSet(train_dataset, tokenizer, parameters["MAX_SOURCE_TEXT_LENGTH"], parameters["MAX_TARGET_TEXT_LENGTH"], source_text, target_text)
dataloader_paramaters = {
'batch_size': parameters["BATCH_SIZE"],
'shuffle': True,
'num_workers': 0
}
training_loader = DataLoader(training_set, **dataloader_paramaters)
optimizer = torch.optim.Adam(params = model.parameters(), lr=parameters["LEARNING_RATE"])
for epoch in range(parameters["EPOCHS"]):
train(epoch, tokenizer, model, device, training_loader, optimizer)
return model
现在可以将代码传递到远程GPU实例上训练我们的模型。
layer.run([build_tokenizer, build_model], debug=True)
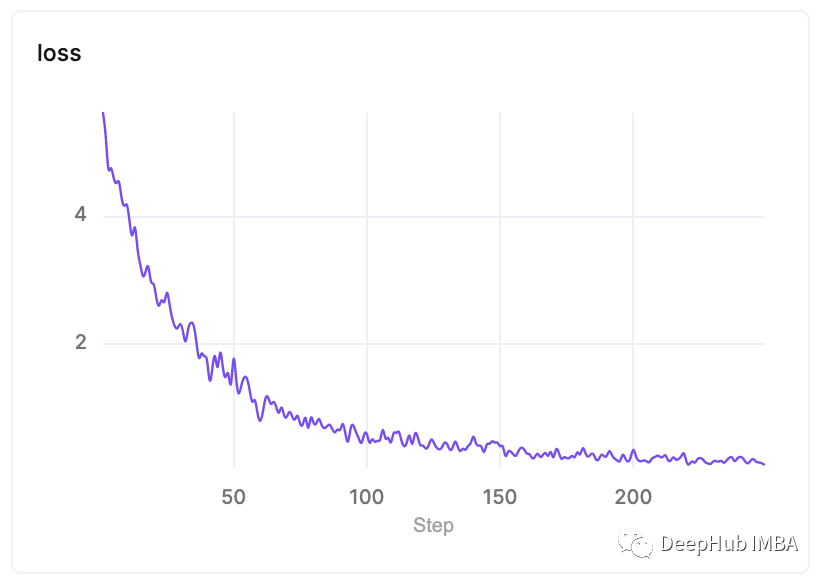
训练完成后,我们可以在UI层中找到我们的模型和指标。这是我们的损失曲线:
使用Gradio构建演示
Gradio是演示机器学习模型的最快方法,任何人在任何地方都可以使用它!我们将与Gradio建立互动演示,以为人们提供UI想要尝试我们的模型。
让我们开始编码。创建一个名为app.py的python文件,并列出以下代码:
import gradio as gr
import layer
model = layer.get_model('layer/t5-fine-tuning-with-layer/models/t5-english-to-sql').get_train()
tokenizer = layer.get_model('layer/t5-fine-tuning-with-layer/models/t5-tokenizer').get_train()
def greet(query):
input_ids = tokenizer.encode(f"translate English to SQL: {query}", return_tensors="pt")
outputs = model.generate(input_ids, max_length=1024)
sql = tokenizer.decode(outputs[0], skip_special_tokens=True)
return sql
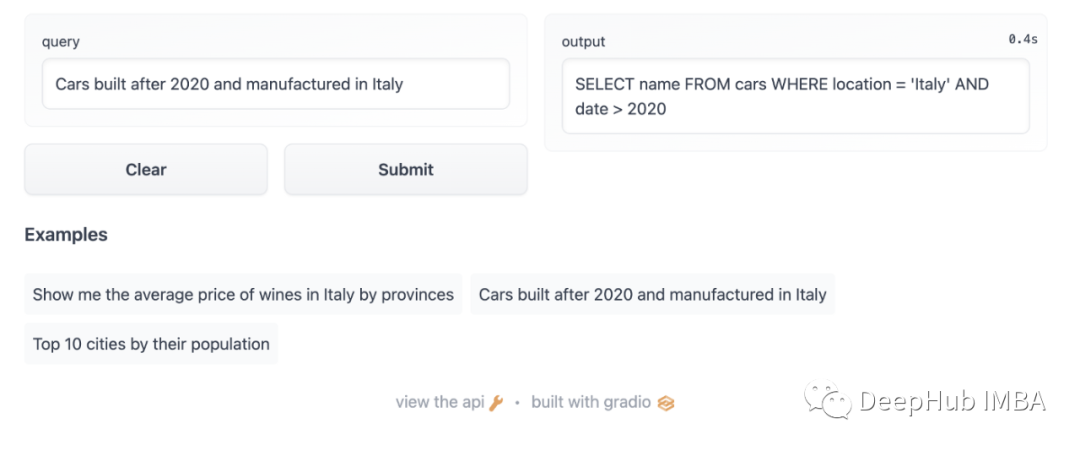
iface = gr.Interface(fn=greet, inputs="text", outputs="text", examples=[
"Show me the average price of wines in Italy by provinces",
"Cars built after 2020 and manufactured in Italy",
"Top 10 cities by their population"
])
iface.launch()
在上面的代码中,使用Gradio创建一个简单的UI:一个用于查询输入的输入TextField和一个输出TextField以显示预测的SQL查询
我们将需要一些额外的库,所以需要创建一个具有以下内容的sumploy.txt文件:
layer==0.9.350435
torch==1.11.0
sentencepiece==0.1.96
这样就可以发布我们的Gradio应用程序:
去Hugging Face创造一个space
输入Gradio的Key作为Space SDK
现在,克隆Hugging Face的space到本地目录中:
$ git clone [YOUR_HUGGINGFACE_SPACE_URL]
将requirements.txt 和app.py文件放入克隆目录中,并在终端中运行以下命令:
$ git add app.py
$ git add requirements.txt
$ git commit -m "Add application files"
$ git push
现在前往Hugging Face的space,部署应用程序后,就可以看到如下的界面
最后
本文展示了如何微调大型语言模型来教他们新技能。我们可以设计自己的任务,并进行微调T5供自己使用。
本文的项目demo和完整代码在这里:
https://huggingface.co/spaces/mecevit/english-to-sql
https://app.layer.ai/layer/t5-fine-tuning-with-layer
作者:Mehmet Ecevit