
目录
1. AI、机器学习、大模型、生成式 AI 和安全
1.1. 前言
最近 ChatGPT 很火, 安全圈有不少大咖们写了文章介绍 ChatGPT 和安全, 感觉都说 ChatGPT 要颠覆了我们这个时代。我最近也在学习相关的知识, 参加了不少会议, 现在也想总结一下, 说说自己的看法。
首先 Chat GPT 只是生成式 AI 的一种, 然后生成式 AI 又是使用大模型进行推理运算的。更准确说, ChatGPT 只是 Open AI 旗下的文字生成类 AI, 只是因为 ChatGPT 火出圈了, 所以大家言必称 Chat GPT 而已。
AI、机器学习、大模型、生成式 AI 和 ChatGPT 的关系如下图:
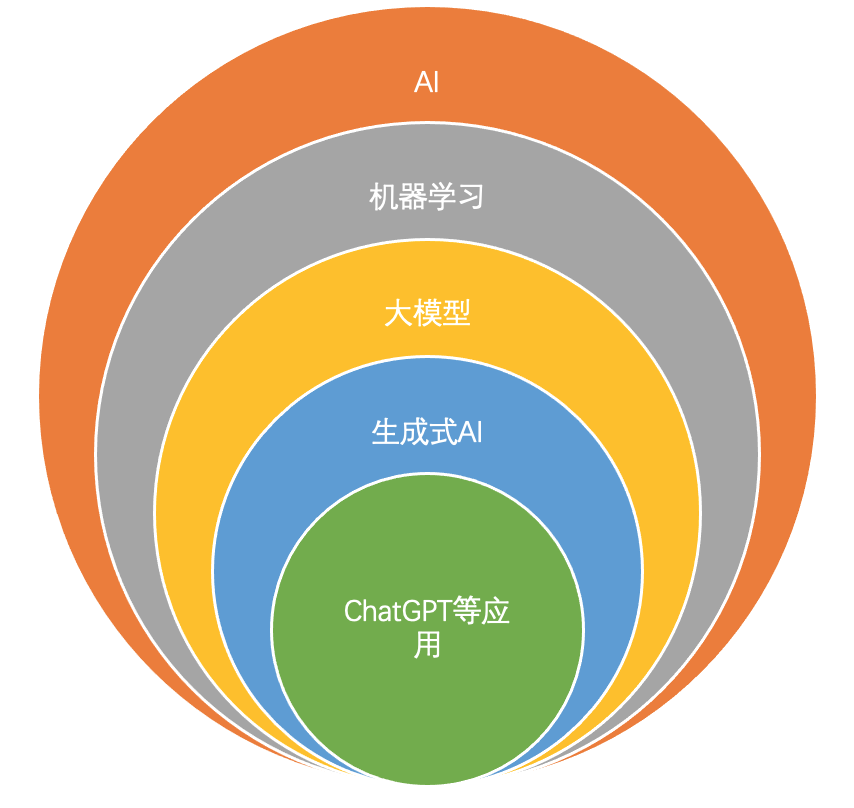
1.2. 人工智能(AI)
人工智能(Artificial Intelligence, AI)是一门研究、开发、实现和应用智能的科学技术, 旨在使计算机和机器具备一定程度的人类智能, 以便执行某些复杂的任务, 甚至超越人类的智能水平。
上世纪 50 年代美国科学家麦克斯韦·洛伦兹提出了"人工智能"这个概念, 并开始了相关领域的研究。1956 年, 达特茅斯学院召开了第一次人工智能研讨会, 正式提出了人工智能这一术语, 标志着人工智能领域的诞生。
自上世纪 60 年代以来, 人工智能领域经历了多次发展和变革。1969 年, 美国计算机科学家约瑟夫·维森鲍姆和纳撒尼尔·罗切斯特提出了"专家系统"的概念, 这是一种基于知识工程的人工智能技术, 可以模拟人类专家的决策过程。1980 年, 美国国防高级研究计划局发起了"语音识别"计划, 开始大规模研究语音识别技术。
上世纪 90 年代至 21 世纪初, 随着计算机技术和数据存储技术的快速发展, 人工智能领域的研究和应用得到了极大的推动。2006 年, 谷歌创始人拉里·佩奇和谢尔盖·布林提出了"深度学习"的概念, 这项技术是人工智能领域的重要突破之一。
人工智能天生就有两个安全问题:
- 人工智能系统的可靠性问题。
人工智能系统在设计和应用过程中可能会出现故障或遭受攻击, 导致系统失灵、崩溃或被篡改, 从而引发安全问题。例如, 人工智能系统可能会遭受黑客攻击、恶意软件感染、数据泄露等安全威胁, 导致系统无法正常运行或者数据被窃取。
- 人工智能的透明度问题。
人工智能系统在决策过程中可能会存在不透明性, 即无法解释的决策过程, 这会导致人们对系统的信任度和接受度降低, 甚至引发安全问题。例如, 人工智能系统在做出某些决策时可能会存在偏见或误判, 导致不公平、不公正的结果, 从而引发社会矛盾和政治问题。
1.3. 机器学习
机器学习是人工智能的一个分支。人工智能的研究历史有着一条从以"推理"为重点, 到以"知识"为重点, 再到以"学习"为重点的自然、清晰的脉络。显然, 机器学习是实现人工智能的一个途径之一, 即以机器学习为手段, 解决人工智能中的部分问题。
机器学习是基于推理的专家系统的另辟蹊径。机器学习的核心是大数据和概率论。
针对机器学习, OWASP 在 2023 年发布了机器学习十大安全风险
- 对抗性攻击
对抗性攻击是一种攻击类型, 在这种攻击中, 攻击者故意更改输入数据以误导模型。
训练深度学习模型将图像分类为不同的类别, 例如狗和猫。攻击者创建了一个与猫的合法图像非常相似的对抗图像, 但带有一些精心设计的小扰动, 导致模型将其错误分类为狗。当模型部署在真实环境中时, 攻击者可以使用对抗图像绕过安全措施或对系统造成危害。我们可以形象地称为指鹿为马。
- 数据中毒攻击
当攻击者操纵训练数据导致模型以不好的方式运行, 就会发生数据中毒攻击。
攻击者使深度学习模型的训练数据中毒, 该模型将电子邮件分类为垃圾邮件或非垃圾邮件。攻击者通过将恶意标记的垃圾邮件注入训练数据集来执行此攻击。
这可以通过破坏数据存储系统来完成, 例如通过侵入网络或利用数据存储软件中的漏洞。攻击者还可以操纵数据标记过程, 例如伪造电子邮件标记或贿赂数据标记者以提供不正确的标签。这个就是著名的漏报。
- 模型逆向攻击
当攻击者对模型进行逆向并从中提取信息, 就会发生模型逆向攻击。
攻击者训练深度学习模型来执行人脸识别。然后, 使用该模型对公司或组织使用的不同人脸识别模型执行模型逆向攻击。
攻击者将个人图像输入模型, 并从模型的预测中恢复例如姓名、地址或身份证等个人信息。
- 成员推理攻击
当攻击者操纵模型的训练数据以使其以暴露敏感信息的方式运行时, 就会发生推理攻击。
恶意攻击者想要访问个人的敏感财务信息, 他们可以通过在财务记录数据集上训练机器学习模型并使用该模型来查询特定个人的记录是否包含在训练数据中来做到这一点。然后, 攻击者可以使用此信息来推断个人的财务历史和敏感信息。
- 模型窃取
当攻击者获得对模型参数的访问权限时, 就会发生模型窃取攻击。
恶意攻击者正在为一家开发了有价值的机器学习模型的公司的竞争对手工作。攻击者想要窃取此模型, 以便他们的公司可以获得竞争优势并开始将其用于自己的目的。
- 损坏的包攻击
当攻击者修改或替换系统使用的机器学习库或模型时, 就会发生损坏的包攻击。
恶意攻击者想要破坏大型组织正在开发的机器学习项目。攻击者知道该项目依赖于几个开源包和库, 并找到一种方法来破坏这些包。这个就是我们经常说的供应链攻击。这种类型的攻击可能特别危险, 因为大家可能会在很长一段时间内都忽视这个危险。攻击者的恶意代码可用于窃取敏感信息、修改结果, 甚至导致机器学习模型失效。
- 迁移学习攻击
当攻击者在一项任务上训练模型, 然后在另一项任务上对其进行微调以使其以不良方式运行时, 就会发生迁移学习攻击。
攻击者在包含经过处理的人脸图像的恶意数据集上训练机器学习模型。攻击者想要针对安全公司用于身份验证的人脸识别系统。然后攻击者将模型的知识传输到目标人脸识别系统。目标系统开始使用攻击者操纵的模型进行身份验证。结果, 人脸识别系统开始做出不正确的预测, 使攻击者能够绕过安全措施并获得对敏感信息的访问权限。这个可以称为移花接木。
- 模型倾斜攻击
当攻击者操纵训练数据的分布以导致模型以不希望的方式运行时, 就会发生模型倾斜攻击。
一家金融机构正在使用机器学习模型来预测贷款申请人的信用度, 并将该模型的预测整合到贷款审批流程中。攻击者通过操纵了模型的反馈循环, 向系统提供虚假的反馈数据, 结果该模型的预测发生错误, 攻击者获得贷款批准的机会显着增加。
这种类型的攻击可能会损害模型的准确性和公平性, 导致意外后果并对金融机构及其客户造成潜在伤害。
- 输出完整性攻击
在输出完整性攻击场景中, 攻击者旨在修改或操纵机器学习模型的输出, 以改变其行为或对其所使用的系统造成危害。
攻击者获得了对医院用于诊断疾病的机器学习模型输出的访问权限。攻击者修改模型的输出, 使其为患者提供错误的诊断。结果, 患者得到了不正确的治疗, 导致进一步的伤害, 甚至可能导致死亡。
- 神经网络重编程攻击
当攻击者操纵模型的参数使其以非期望的方式运行时, 就会发生神经网络重编程攻击。
比如银行正在使用机器学习模型来识别支票上的手写字符, 以实现清算流程的自动化。该模型已在大型手写字符数据集上进行训练, 旨在根据大小、形状、倾斜度和间距等特定参数准确识别字符。攻击者可以通过改变训练数据集中的图像或直接修改模型中的参数来操纵模型的参数。这可能导致模型被重新编程以不同地识别字符。例如, 攻击者可以更改参数, 使模型将字符"5"识别为字符"2", 从而导致处理的金额不正确。
攻击者可以通过在清算过程中引入伪造支票来利用此漏洞, 由于操纵参数, 该模型将处理为有效。这可能会给银行带来重大的经济损失。
以上十大风险都是在机器学习的过程中需要注意的, 详情大家可以参考 OWASP 的官网 https://owasp.org/www-project-machine-learning-security-top-10/。
1.4. 大模型(LLM)
大模型(Large Language Model, 大语言模型)是指具有大量参数和复杂结构的机器学习模型。这些模型可以应用于处理大规模的数据和复杂的问题。大模型的概念起源于深度学习模型, 如卷积神经网络和循环神经网络等, 这些模型在处理大规模数据和复杂问题方面具有较高的性能。
大模型的发展历史可以追溯到 20 世纪 90 年代初, 当时机器学习模型主要以逻辑回归、神经网络、决策树和贝叶斯方法等为代表。这些传统的机器学习模型规模较小, 只能处理较小的数据集。随着计算机硬件和软件的发展, 深度学习模型逐渐兴起。2006 年, 加拿大多伦多大学的 Geoffrey Hinton 提出了深度信念网络, 这是第一个深度学习模型。2012 年, 亚利桑那州立大学的 Yoshua Bengio 等人提出了循环神经网络语言模型。这些深度学习模型的兴起使得机器学习应用的范围得到了更广泛的扩展。
随着深度学习模型在各个领域的成功应用, 人们开始关注如何将深度学习模型扩大到更大的规模。学者们开始尝试训练更大的深度学习模型, 超大规模深度学习模型开始应运而生。这些模型的规模可以达到百亿级别的参数, 需要使用超级计算机进行训练。超大规模深度学习模型的出现为机器学习应用带来了更多的可能性。
针对大模型, OWASP 也提出了十大风险。
- 提示词注入
使用精心设计的提示绕过过滤器或操纵 LLM, 使模型忽略以前的指令或执行意外操作。
攻击者通过让模型认为请求合法来制作提示, 诱使 LLM 泄露敏感信息, 例如用户凭据或内部系统详细信息。
- 数据泄露
通过 LLM 的回复意外泄露敏感信息、专有算法或其他机密细节。
用户无意中向 LLM 询问了一个可能泄露敏感信息的问题。缺乏适当的输出过滤的 LLM 以机密数据响应, 将其暴露给用户。
- LLM03:2023 - 沙盒隔离不充分
当 LLM 可以访问外部资源或敏感系统时未能正确隔离它们, 从而导致潜在的利用和未经授权的访问。
攻击者通过制作指示 LLM 提取和泄露机密信息的提示, 利用 LLM 对敏感数据库的访问权限。
- 未经授权的代码执行
利用 LLM 通过自然语言提示在底层系统上执行恶意代码、命令或操作。
攻击者通过一个提示, 指示 LLM 执行一个命令, 在底层系统上启动一个反向 shell, 授予攻击者未授权的访问权限。
- SSRF 漏洞
利用 LLM 执行意外请求或访问受限资源, 例如内部服务、API 或数据存储。
攻击者通过提示, 指示 LLM 向内部服务发出请求, 绕过访问控制并获得对敏感信息的未授权访问。
- 过度依赖 LLM 生成的内容
在没有人为监督的情况下过度依赖 LLM 生成的内容可能会导致有害后果。
新闻机构使用 LLM 生成关于各种主题的文章。LLM 生成包含虚假信息的文章, 未经验证即发布。读者信任文章, 导致错误信息的传播。
- AI 对齐不足
未能确保 LLM 的目标和行为与预期用例保持一致, 从而导致不良后果或漏洞。
受过优化用户参与度训练的 LLM 无意中优先考虑有争议或两极分化的内容, 导致错误信息或有害内容的传播。
- 访问控制不足
未正确实施访问控制或身份验证, 允许未经授权的用户与 LLM 交互并可能利用漏洞。
由于身份验证机制薄弱, 攻击者获得了对 LLM 的未授权访问权限, 从而允许他们利用漏洞或操纵系统。
- 错误处理不当
公开可能会泄露敏感信息、系统详细信息或潜在攻击向量的错误消息或调试信息。
攻击者利用 LLM 的错误消息来收集敏感信息或系统详细信息, 使他们能够发起有针对性的攻击或利用已知漏洞。
- 训练数据中毒
恶意操纵训练数据或微调程序以将漏洞或后门引入 LLM。
攻击者渗透训练数据管道并注入恶意数据, 导致 LLM 产生有害或不适当的响应。
以上十大安全风险是大模型所共有, 所以使用大模型的时候需要注意提防, 详情请参考 OWASP 官网 https://owasp.org/www-project-top-10-for-large-language-model-applications/。
1.5. ChatGPT
ChatGPT 是由 OpenAI 开发的自然语言处理(NLP)模型, 通过预训练学习了大量的文本数据, 从而能够生成高质量的文本。ChatGPT 是一种生成式 AI, 可以用来生成文章、代码、机器翻译等各种文本形式。
ChatGPT 有很多竞争对手, 包括国内的百度的文心一言, 阿里的通义千问以及国外的 Google Bard 等。
ChatGPT 是一种基于大模型的机器学习, 所以机器学习的安全风险和大模型的安全风险 ChatGPT 都有。
另外 ChatGPT 是 OpenAI 公司私有的, 而且 ChatGPT 在中国国内是不开放的, 所以在中国国内使用 ChatGPT 会有法律风险。
同时 ChatGPT 部署是国外的, 如果公司为了使用 ChatGPT 将个人敏感信息发送过去进行训练, 就会带来数据安全问题, 这可能违反国内的《数据安全法》和《个人数据保护法》。
还有 ChatGPT 会将训练数据放到模型中, 如果个人根据《个人数据保护法》要求删除数据, 可能没有办法很容易删除, 这个也违反了《个人数据保护法》。
所以企业要使用 ChatGPT 进行商业活动, 就要慎之又慎了。
1.6. 总结
ChatGPT 很火, 但是 ChatGPT 也不是无所不能的。我刚接触 ChatGPT, 真的觉得它是无所不能, 深深感觉到人工智能要真的威胁人类了, 但是经过亲自学习研究, 发现 ChatGPT 有个特点就是只管生成, 不管正确性, 通俗讲就是只管杀不管埋, 所以使用 ChatGPT 或者其他生成式 AI 要慎重, 因为它只提供它认为的内容, 不管内容的准确性。
美国就刚刚发生一个案例, 一个律师使用 ChatGPT 提供的案例进行法律诉讼, 结果被发现都是假案例, 这个后果就有点严重了。
ChatGPT 不是无中生有, 它也是从机器学习, 大模型, 生成式 AI 一步一步走来的, 大家不要过度神化。这个不仅仅是 ChatGPT, 对于文心一言, 通义千问也是如此。机器学习、大模型等与生俱来的安全问题该有它都有, 没有什么例外。
对于 ChatGPT 类似的生成式 AI, 会对我们的生活产生影响, 但是我们要透过现象看本质, 不要轻易被忽悠了。
版权归原作者 云满笔记 所有, 如有侵权,请联系我们删除。