
这是一篇非常有意思的论文,它将时间序列分块并作为语言模型中的一个token来进行学习,并且得到了很好的效果。
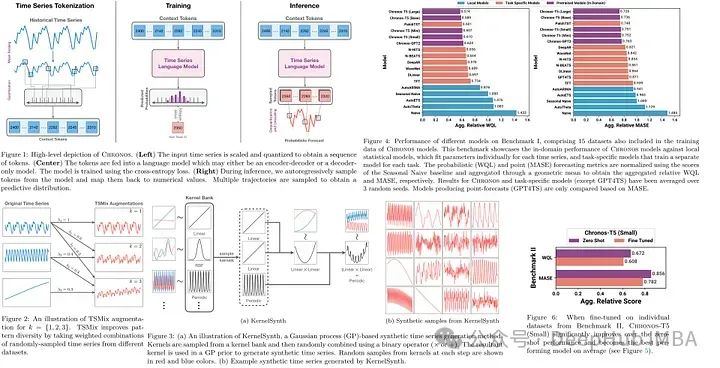
Chronos是一个对时间序列数据的概率模型进行预训练的框架,它将这些值标记为与基于transformer的模型(如T5)一起使用。模型将序列的值缩放和量化到一个固定的词汇表,并在通过高斯过程创建的公共和合成数据集上进行训练。Chronos模型的参数范围从20M到710M不等,在已知数据集上优于传统和深度学习模型,在新数据集上表现出具有竞争力的零样本性能。
标记
为了使时间序列数据适应基于transformer的语言模型,使用了两个步骤:缩放和量化。缩放使用平均缩放将数据规范化到一个公共范围,其中每个点都通过历史上下文中绝对值的平均值进行调整。在缩放之后,量化通过将数据范围分成箱(每个箱由一个记号表示)将实值序列转换为离散标记。作者更喜欢统一的分位数分组,据说是要适应不同数据集的可变性,因为预测范围受到预定义的最小值和最大值的限制。另外就是还添加了用于填充和序列结束的特殊标记。
目标函数
Chronos是通过使用分类交叉熵损失函数将预测作为分类问题来训练时间序列数据。模型在表示量化时间序列数据的标记化词汇表上预测分布,并将该分布与真实分布之间的差异最小化。与距离感知度量不同,这种方法不直接考虑箱之间的接近程度,而是依赖于模型从数据中学习箱关系。这样就有两个优势:与现有语言模型体系结构和训练方法的无缝集成,可以学习任意的、潜在的多模态输出分布的能力,并且可以在不同领域之间通用,无需更改模型结构或训练目标。
Chronos模型通过对其预测的令牌分布进行自回归采样,对未来的时间步长进行概率预测。然后使用去量化函数和逆缩放将生成的令牌转换回实际值。
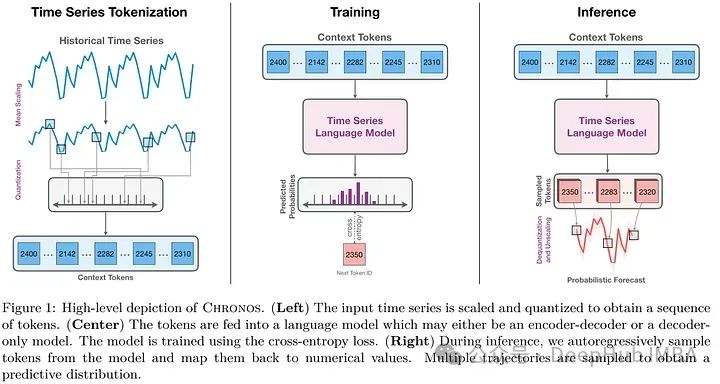
数据增广
TSMix通过组合两个以上的数据点,将Mixup数据增强概念(最初是为图像分类而开发的)扩展到时间序列数据。它从训练数据集中随机选择一些不同长度的时间序列,对它们进行缩放,并创建它们的凸组合。这种组合的权重是从对称狄利克雷分布中得出的。
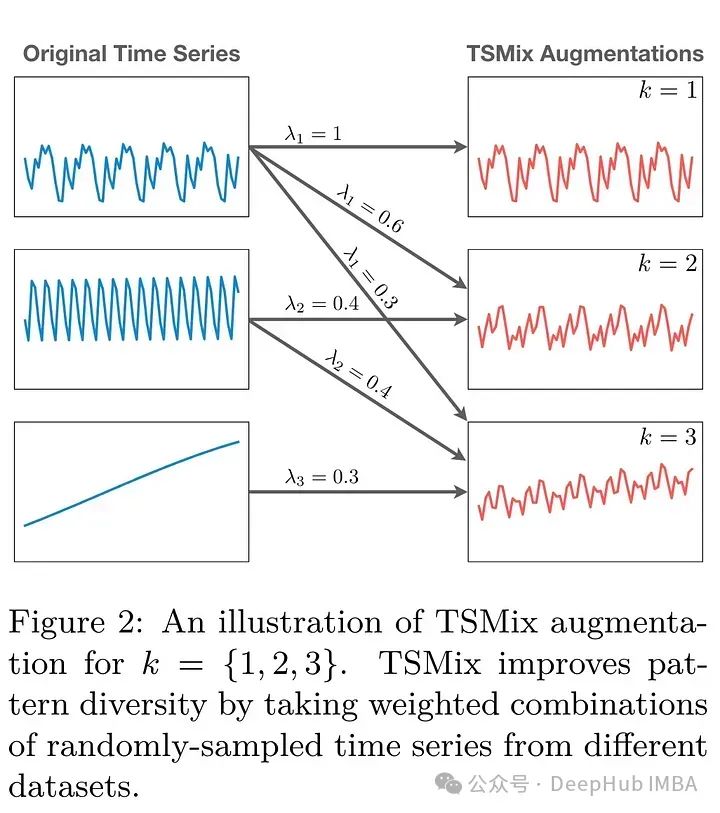
KernelSynth则使用高斯过程合成数据生成。KernelSynth组装GP核来创建新的时间序列,利用一组基核来处理常见的时间序列模式,如趋势、平滑变化和季节性。通过随机选择这些核,并通过加法或乘法将其组合在一起,产生不同的时间序列数据。
实验结果
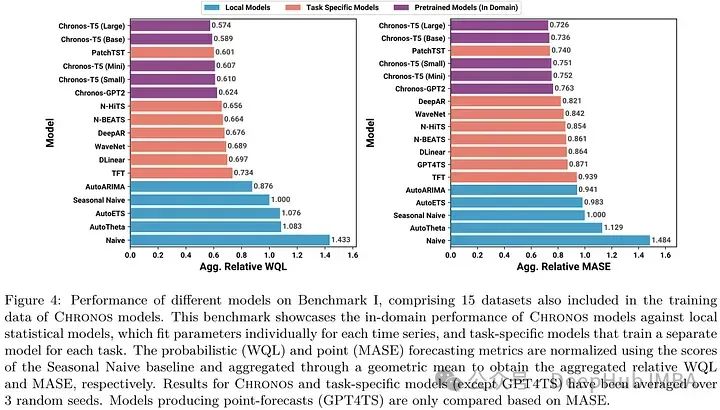
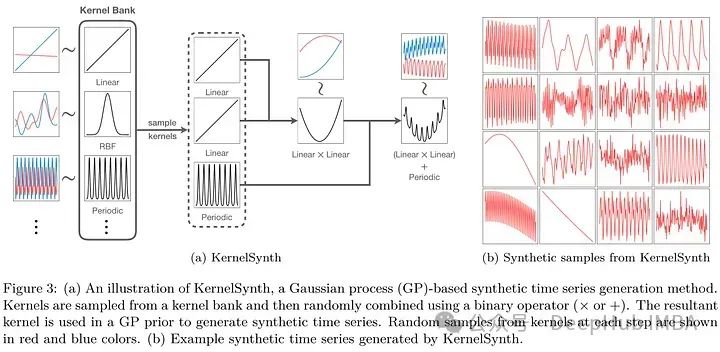
较大的Chronos-T5模型(基础和大型)超过基线模型,展示了优越的概率和点预测能力。这些模型不仅超越了AutoETS和AutoARIMA等传统统计模型,也超越了PatchTST和DeepAR等特定任务的深度学习模型。较小的Chronos变体和Chronos- gpt2也优于大多数基线,尽管PatchTST在某些情况下显示出更强的结果。季节性传统模型的竞争表现表明,这些数据集(主要来自能源和运输部门)具有很强的季节性趋势。
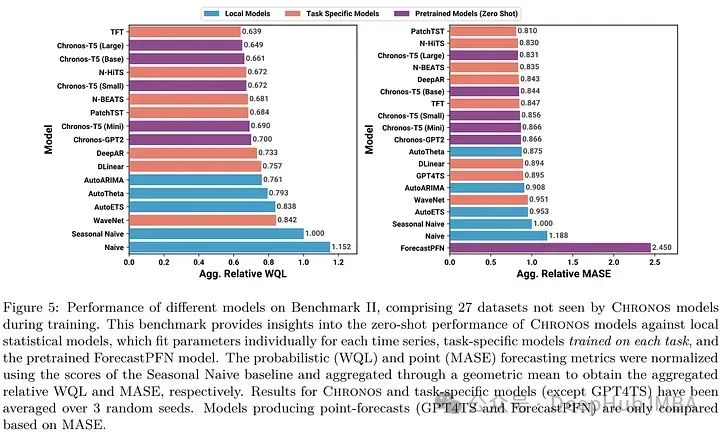
零样本预测概率预测方面,Chronos模型超过了局部统计模型和大多数特定任务模型,其中Chronos- t5 Large模型在点预测方面排名第三。它们的表现甚至超过了ForecastPFN和GPT4TS(微调GPT2),显示出作为通用时间序列预测器的显著前景。
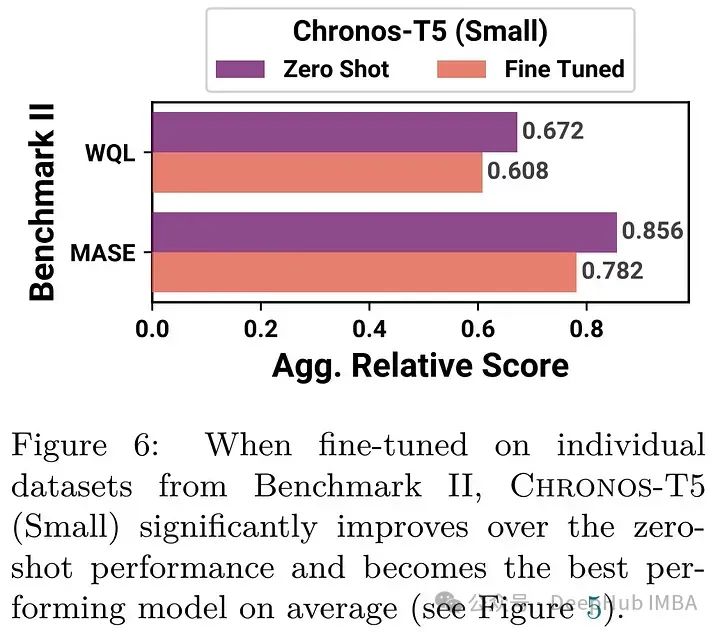
微调小型模型也显示了显著的性能改进,使其在零样本设置和最佳任务特定模型中优于大型Chronos变体。
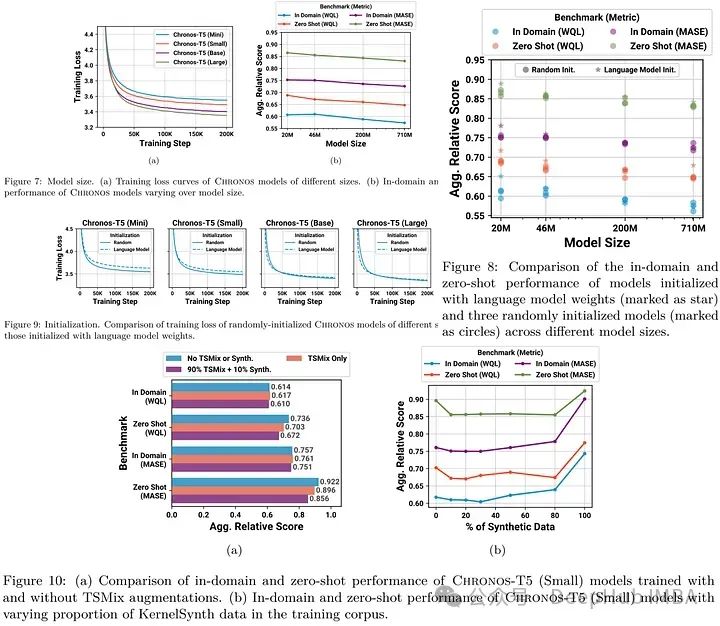
论文的一些研究
更大的型号更好;随机权重初始化比使用LLM权重更好,因为它们可能与时间预测无关;TSMix改善了零样本学习能力;使用大约10%的合成数据是最好的;
讨论
该研究证明了Chronos在各种数据集上的零样本能力,表明它有潜力通过微调技术(如LoRA或特定任务校准的保形方法)胜过特定任务模型。特定于任务的适配器或像LightGBM这样的模型的堆叠集成可以用来添加协变量并应用于多变量预测。
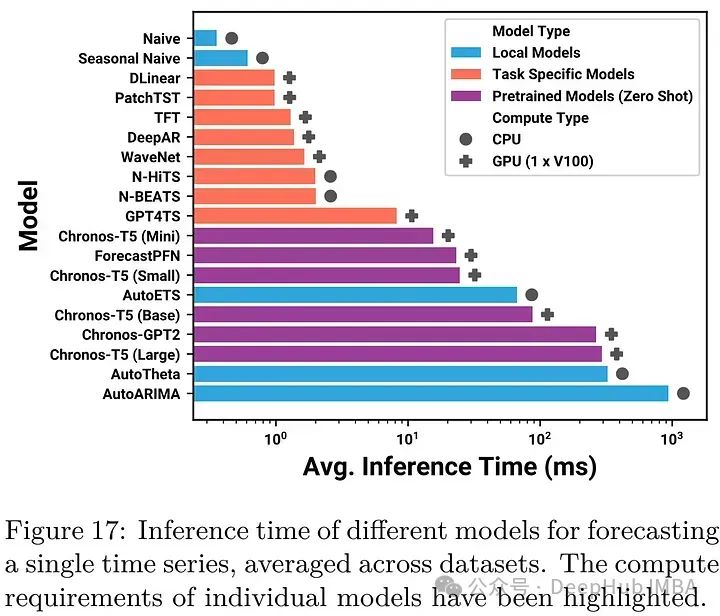
与特定任务的深度学习模型相比,大型Chronos模型的推理速度较慢。Chronos模型的优势在于其在不同数据集特征上的通用性,而不需要单独的特定任务训练,简化了预测流程。此外,通过优化的计算核、量化和更快的解码方法等技术也适用于Chronos,有可能提高推理速度和预测质量。处理长上下文数据的方法可以进一步提高Chronos在高频数据集上的性能,受nlp启发的方法,如温度调节和采样策略,可以提高预测的效率和准确性。
论文地址:
https://arxiv.org/abs/2403.07815
作者:Andrew Lukyanenko