
由于Mixtral的发布,专家混合(MoE)架构在最近几个月变得流行起来。虽然Mixtral和其他MoE架构是从头开始预训练的,但最近出现了另一种创建MoE的方法:Arcee的MergeKit库可以通过集成几个预训练模型来创建moe。这些人通常被称为frankenMoEs或MoErges,以区别于预先训练的MoEs。
在本文中,我们将详细介绍MoE架构是如何工作的,以及如何创建frankenmoe。最后将用MergeKit制作自己的frankenMoE,并在几个基准上对其进行评估。

MOE
混合专家是为提高效率和性能而设计的体系结构。它使用多个专门的子网,称为“专家”。与激活整个网络的密集模型不同,MoEs只根据输入激活相关专家。这可以获得更快的训练和更有效的推理。
MoE模型的核心有两个组件:
稀疏MoE层:它们取代了transformer 体系结构中的密集前馈网络层。每个MoE层包含几个专家,并且只有这些专家的一个子集被用于给定的输入。
Gate Network或Router:该组件确定哪些令牌由哪些专家处理,确保输入的每个部分由最合适的专家处理。
在下面的示例中,我们展示了如何将Mistral-7B块转换为具有稀疏MoE层(前馈网络1、2和3)和路由器的MoE块。本例表示一个拥有三个专家的MoE,其中两名目前正在工作(ffn1和ffn3)。
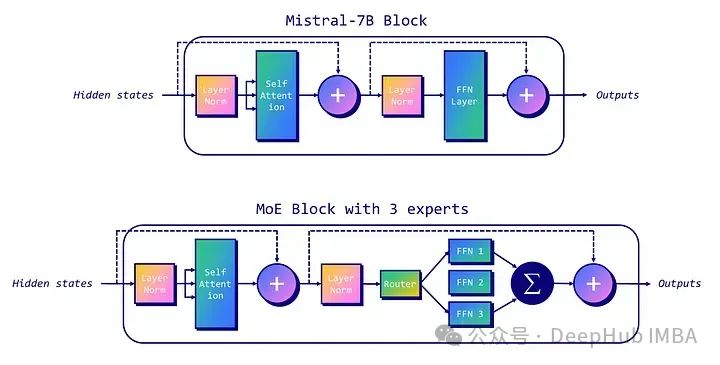
由于模型的复杂性,微调moe过程可能很困难,需要在训练期间平衡专家的使用,以适当地训练门控权重以选择最相关的权重。在内存方面,即使在推理过程中只使用了总参数的一小部分,但包括所有专家在内的整个模型都需要加载到内存中,这需要很高的VRAM容量。
moe有两个基本参数:
专家数(num_local_experts):这决定了体系结构中专家的总数(例如,Mixtral为8)。专家数越多,VRAM的使用率就越高。
每专家的令牌数(num_experts_per_tok):这决定了每个令牌和每个层所使用的专家数量(例如,Mixtral为2)。在每个令牌的高数量专家与快速训练和推理的低数量专家之间存在权衡。
以前moe的表现不如密集模型。但是2023年12月发布的Mixtral-8x7B改变了这个观点。另外就是传闻GPT-4也是一个MoE,这是有道理的,因为与密集模型相比,OpenAI运行和训练它要便宜得多。
MoEs vs frankenMoEs
传统的moe,专家和路由共同训练。但是我们今天要介绍的frankenMoEs只升级现有的模型,然后初始化路由器。
也就是说我们从基本模型中复制大多数的权重(LN和注意力层),然后再复制每个专家中的FFN层的权重。也就是说除了ffn之外,所有其他参数都是共享的。这个原理和Mixtral-8x7B与8个专家没有8*7 = 56B参数,而是大约45B,每个令牌使用两个专家可以提供12B密集模型的推理速度(FLOPs),而不是14B是一样的。
MergeKit为了选择最相关的专家并适当地初始化他们,实现了三种初始化路由器的方式:
随机权重Random:这是最简单但是最不建议的方法,因为每次都可能选择相同的专家(它需要进一步微调或num_local_experts = num_experts_per_tok,这意味着不需要任何路由)。
低成本嵌入Cheap embed:它直接使用输入标记的原始嵌入,并在所有层上应用相同的转换。这种方法计算成本低,适合在功能较弱的硬件上执行。
隐藏层表示Hidden:它通过从LLM的最后一层提取积极和消极提示列表来创建隐藏表示。对它们进行平均和归一化来初始化门控单元。
通过上面描述就可以猜到“Hidden”初始化是将令牌正确路由到最相关专家的最有效方法。在下一节中,我们将使用这种技术创建自己的frankenMoE。
创建frankenMoEs
首先我们需要选择n位专家。这里将使用Mistral-7B,因为它的尺寸合适,并且也经过了测试是目前比较好的模型。像Mixtral这样的8个专家有点多了,所以在本例中我们将使用总共四个专家,每个令牌和每个层使用其中两个专家。我们最终将得到一个具有24.2B个参数的模型,而不是4*7 = 28B个参数。
我们这次的目标是创建一个全面的模型,它可以做几乎所有的事情:写故事、解释文章、用Python编写代码等等。所以可以将这个需求分解为四个任务,并为每个任务选择最好的专家。我是这样分解它的:
聊天模型:使用的通用模型mlabonne/AlphaMonarch-7B,完全符合要求。
代码模型:能够生成良好代码的模型。我对基于mistral - 7b的代码模型没有太多的经验,但我发现beowolx/CodeNinja-1.0-OpenChat-7B与其他代码模型相比来说会好一些。
数学模型:数学对LLM来说很棘手,所以我们想要一个专门的数学模型。这里选择了mlabonne/ neuralaredevil - 7b,因为它的MMLU和GMS8K分数很高
角色扮演模式:这种模式的目标是写出高质量的故事和对话。所以SanjiWatsuki/ Kunoichi-DPO-v2-7B看样子不错,因为MT-Bench评分很高(8.51)。
可以看到我们都是选择的基于mistral - 7b的模型,因为这是MergeKit的要求,模型的架构必须要一致,所以除了我们以上的方法以外还可以选择使用不同数据进行微调的模型,只要模型表现有差异即可,但是最重要的一点是模型架构必须相同。
现在我们已经有了使用的专家,就可以创建YAML配置,MergeKit将使用它来创建frankenMoE。我们的配置如下:
base_model: mlabonne/AlphaMonarch-7B
experts:
- source_model: mlabonne/AlphaMonarch-7B
positive_prompts:
- "chat"
- "assistant"
- "tell me"
- "explain"
- "I want"
- source_model: beowolx/CodeNinja-1.0-OpenChat-7B
positive_prompts:
- "code"
- "python"
- "javascript"
- "programming"
- "algorithm"
- source_model: SanjiWatsuki/Kunoichi-DPO-v2-7B
positive_prompts:
- "storywriting"
- "write"
- "scene"
- "story"
- "character"
- source_model: mlabonne/NeuralDaredevil-7B
positive_prompts:
- "reason"
- "math"
- "mathematics"
- "solve"
- "count"
还有很多其他配置,请参看MergeKit的文档。
对于每个专家,提供了五个基本的积极提示。如果真正使用的话可以更加详细,比如写出完整的句子。因为最好的策略是使用能够触发特定专家的真实提示,添加负面提示来做相反的事情也是一个好方法。
准备好之后,可以将配置保存为config.yaml。在同一个文件夹中,我们将下载并安装mergekit库(mixtral分支)。
git clone -b mixtral https://github.com/arcee-ai/mergekit.git
cd mergekit && pip install -e .
pip install -U transformers
如果你的计算机有足够的内存(大约24 - 32gb),你可以运行以下命令:
mergekit-moe config.yaml merge --copy-tokenizer
如果你没有足够的内存,你可以像下面这样对模型进行分片(这需要更长的时间):
mergekit-moe config.yaml merge --copy-tokenizer --allow-crimes --out-shard-size 1B --lazy-unpickle
这个命令自动下载专家并在目录中创建frankenMoE。对于我们选择的 “hidden”门模式,还可以使用load-in-4bit和load-in-8bit选项以较低的精度计算隐藏状态。
还可以将配置复制到LazyMergekit中,我们将在Colab提供中(本文最后),可以输入您的模型名称,选择混合分支,指定Hugging Face用户名/令牌,并运行。
为了更好地了解其功能,我们在三个不同的基准测试上对其进行了评估:Nous的基准测试套件、EQ-Bench和Open LLM Leaderboard。这个模型不是为了在传统的基准测试中脱颖而出而设计的,因为代码和角色扮演模型通常不适用于那些环境。但是由于强大的通用专家,它表现得非常好。
beyond - 4x7b -v3是Nous基准测试套件中最好的模型之一(使用LLM AutoEval进行评估),性能明显优于v2。
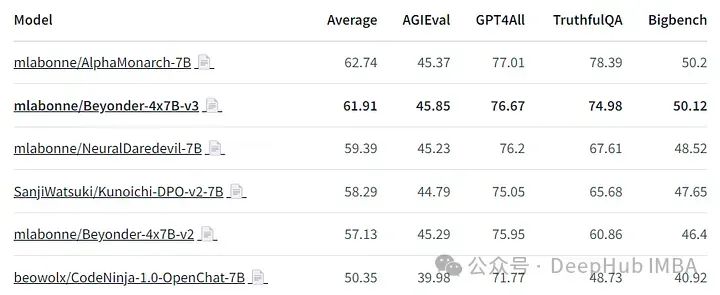
它也是EQ-Bench排行榜上最好的4x7B模型,优于旧版本的ChatGPT和Llama-2-70b-chat。beyond与Mixtral-8x7B-Instruct-v0.1和Gemini Pro非常接近,后者(据说)要大得多。
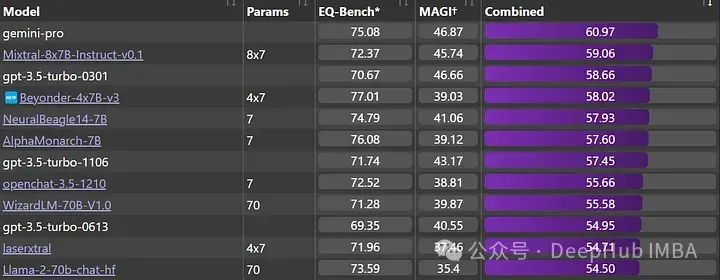
最后,它在Open LLM排行榜上的表现也很强劲,明显优于v2模型。
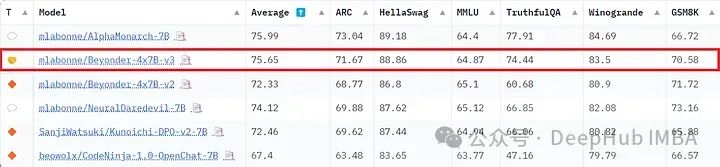
在这些定量评估之上,我还建议使用LM Studio上以更定性的方式检查模型的输出。测试这些模型的一种常用方法是收集一组问题并检查它们的输出。通过这种策略,我发现与其他模型(包括AlphaMonarch-7B)相比,beyond - 4x7b -v3对用户和系统提示的变化非常稳健。这是非常酷的,因为它提高了模型的可用性。
frankenMoEs是一种很有前途但仍处于实验阶段的方法。可能会比SLERP或DARE TIES等更简单的合并技术更具优势。并且当只对两个专家使用frankenMoEs时,它们的表现可能不如简单地合并两个模型那么好。但是frankenMoEs擅长保存知识,这可以获得更强大的模型,如我们上面的beyond - 4x7b -v3所示。
总结
在本文中,我们介绍了混合专家体系结构。与从零开始训练的传统moe不同,MergeKit通过整合专家来促进moe的创建,提供了一种提高模型性能和效率的创新方法。我们还详细介绍了使用MergeKit创建MoE的过程,以下是本文的一些代码
LazyMergekit
https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb#scrollTo=d5mYzDo1q96y
推理
https://colab.research.google.com/drive/1SIfwhpLttmoZxT604LGVXDOI9UKZ_1Aq?usp=sharing
作者:Maxime Labonne