【AI落地应用实战】灵办AI——学术检索与论文阅读必备插件
作为一名学术领域的探索者,。然而,这一过程并非总是一帆风顺,特别是当我们面对海量的英文学术文献时,语言障碍往往成为制约我们深入研究的瓶颈。

使用Ollama和OpenWebUI,轻松探索Meta Llama3–8B
大家好,2024年4月,Meta公司开源了Llama 3 AI模型,迅速在AI社区引起轰动。紧接着,Ollama工具宣布支持Llama 3,为本地部署大型模型提供了极大的便利。本文将介绍如何利用Ollama工具,实现Llama 3–8B模型的本地部署与应用,以及通过Open WebUI进行模型交互的
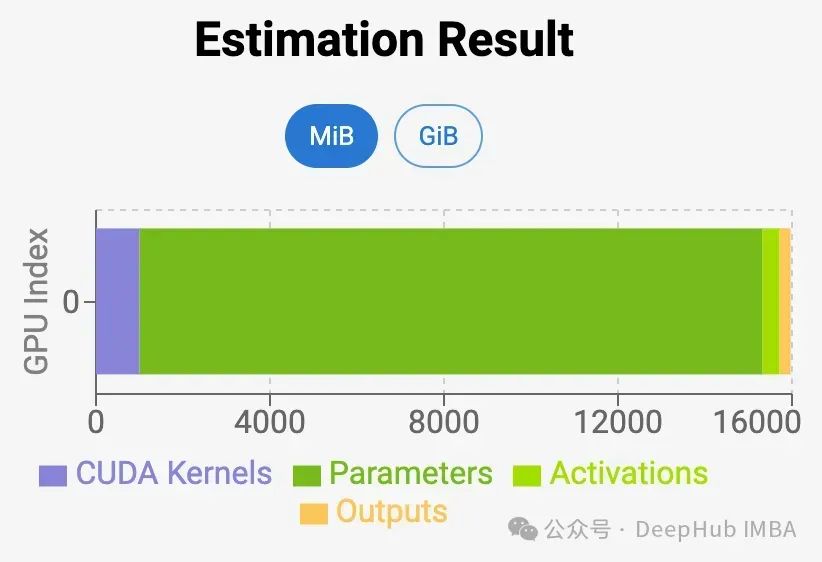
大语言模型VRAM估算指南和工具介绍
在本文中,我们将深入研究如何计算执行LLM推理所需的VRAM数量。确定在LLM上运行或执行推理所需的GPU VRAM通常是一个挑战。

使用vLLM在一个基座模型上部署多个lora适配器
在本文中,我们将看到如何将vLLM与多个LoRA适配器一起使用。我将解释如何将LoRA适配器与离线推理一起使用,以及如何为用户提供多个适配器以进行在线推理。
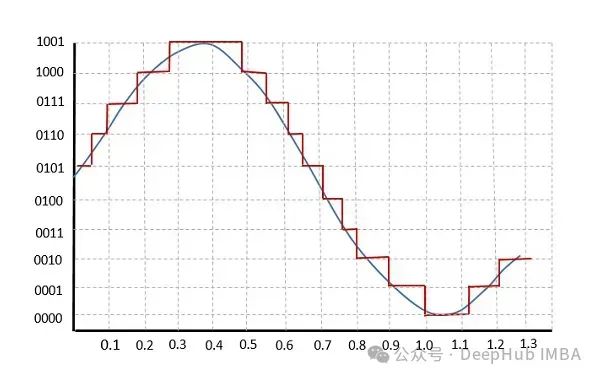
用PyTorch 从零开始构建 BitNet 1.58bit
我们手动实现BitNet的编写,并进行的一系列小实验证实,看看1.58bit 模型是否与全精度的大型语言模型相媲美!
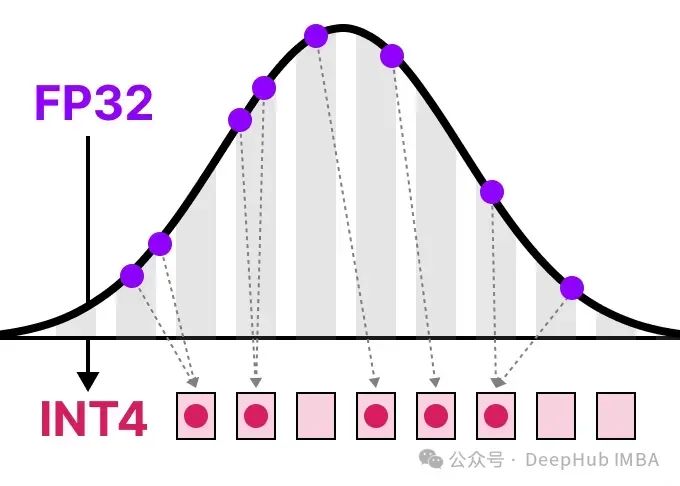
模型量化技术综述:揭示大型语言模型压缩的前沿技术
在这篇文章中,我将在语言建模的背景下介绍量化,并逐一探讨各个概念,探索各种方法论、用例以及量化背后的原理。
LLMs之memory:mem0(个性化的AI记忆层)的简介、安装和使用方法、案例应用之详细攻略
LLMs之memory:mem0(个性化的AI记忆层)的简介、安装和使用方法、案例应用之详细攻略目录mem0的简介mem0的安装和使用方法mem0的案例应用mem0的简介2024年7月19日,Mem0 AI公司公开发布mem0,这是一款个性化 AI 的记忆层。Mem0 为大语言模型提供了一个智能、
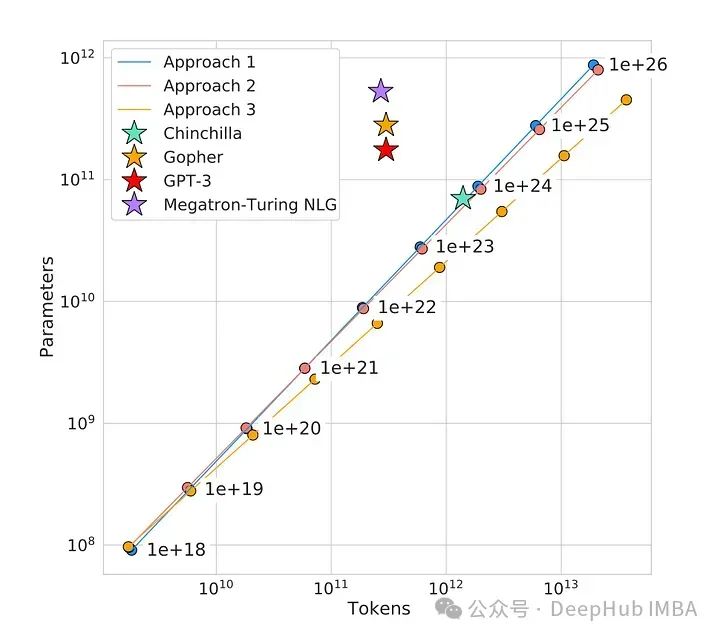
大语言模型的Scaling Law:如何随着模型大小、训练数据和计算资源的增加而扩展
在这篇文章中,我们将介绍使这些模型运作的秘密武器——一个由三个关键部分组成的法则:模型大小、训练数据和计算能力。通过理解这些因素如何相互作用和规模化,我们将获得关于人工智能语言模型过去、现在和未来的宝贵见解。

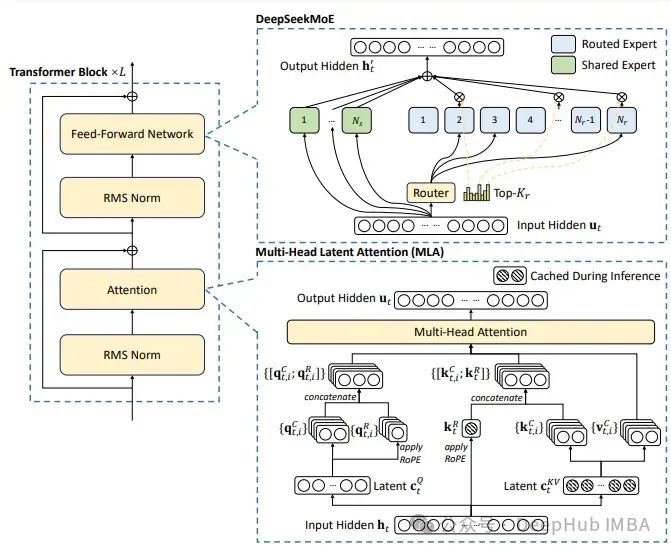
用PyTorch从零开始编写DeepSeek-V2
DeepSeek-V2是一个强大的开源混合专家(MoE)语言模型,通过创新的Transformer架构实现了经济高效的训练和推理。该模型总共拥有2360亿参数,其中每个令牌激活21亿参数,支持最大128K令牌的上下文长度。
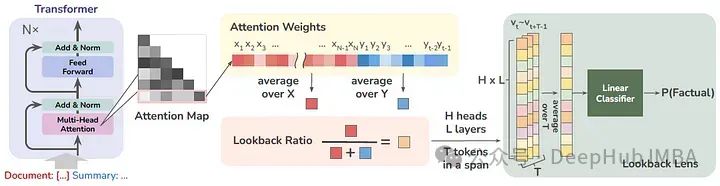
Lookback Lens:用注意力图检测和减轻llm的幻觉
这篇论文的作者提出了一个简单的幻觉检测模型,其输入特征由上下文的注意力权重与新生成的令牌(每个注意头)的比例给出。
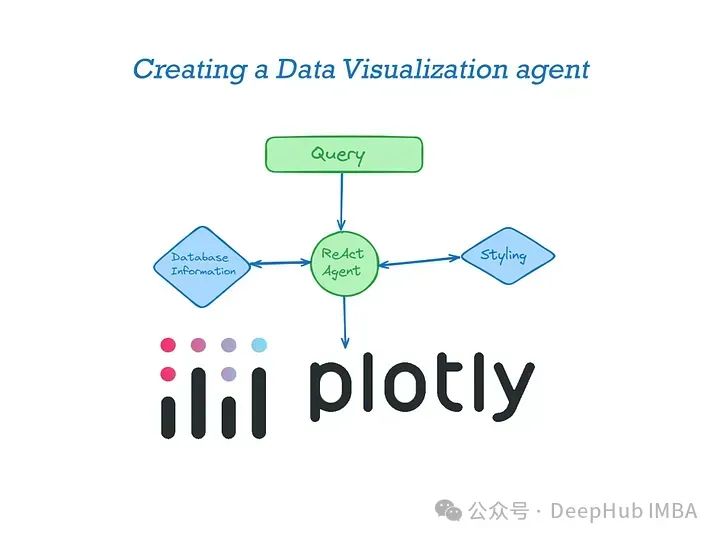
LLM代理应用实战:构建Plotly数据可视化代理
我们构建一个数据可视化的代理,通过代理我们只需提供很少的信息就能够让LLM生成我们定制化的图表。
LLM推理引擎怎么选?TensorRT vs vLLM vs LMDeploy vs MLC-LLM
有很多个框架和包可以优化LLM推理和服务,所以在本文中我将整理一些常用的推理引擎并进行比较。
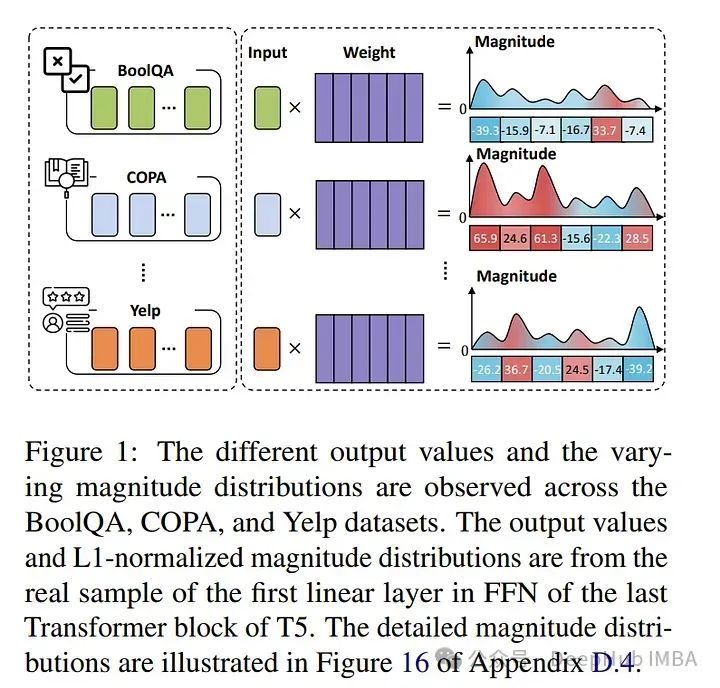
2024年6月后2周重要的大语言模型论文总结:LLM进展、微调、推理和对齐
本文总结了2024年6月后两周发表的一些最重要的大语言模型论文。这些论文涵盖了塑造下一代语言模型的各种主题,从模型优化和缩放到推理、基准测试和增强性能。

RouteLLM:高效LLM路由框架,可以动态选择优化成本与响应质量的平衡
该论文提出了一个新的框架,用于在强模型和弱模型之间进行查询路由选择。通过学习用户偏好数据,预测强模型获胜的概率,并根据成本阈值来决定使用哪种模型处理查询 。该研究主要应用于大规模语言模型(LLMs)的实际部署中,通过智能路由在保证响应质量的前提下显著降低成本。
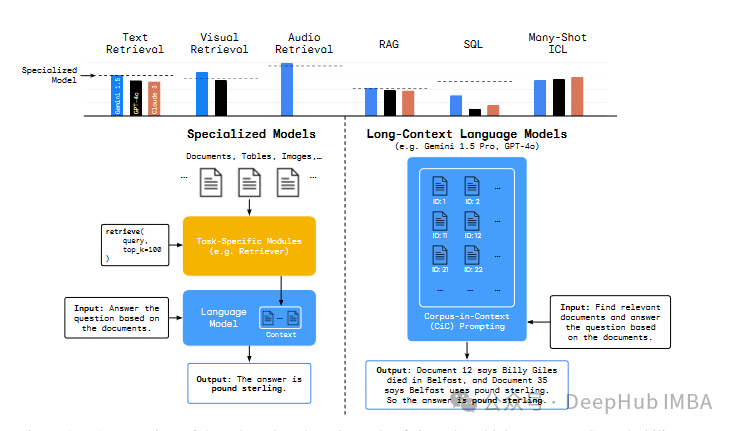
DeepMind的新论文,长上下文的大语言模型能否取代RAG或者SQL这样的传统技术呢?
关于长上下文大型语言模型是否真正利用其巨大的上下文窗口,以及它们是否真的更优越
阿里通义千问:本地部署Qwen1.5开源大模型
通义千问为阿里云研发的大语言系列模型。千问模型基于Transformer架构,在超大规模的预训练数据上进行训练得到。预训练数据类型多样,覆盖广泛,包括大量网络文本、专业书籍、代码等。同时,在预训练模型的基础之上,使用对齐机制打造了模型的chat版本。
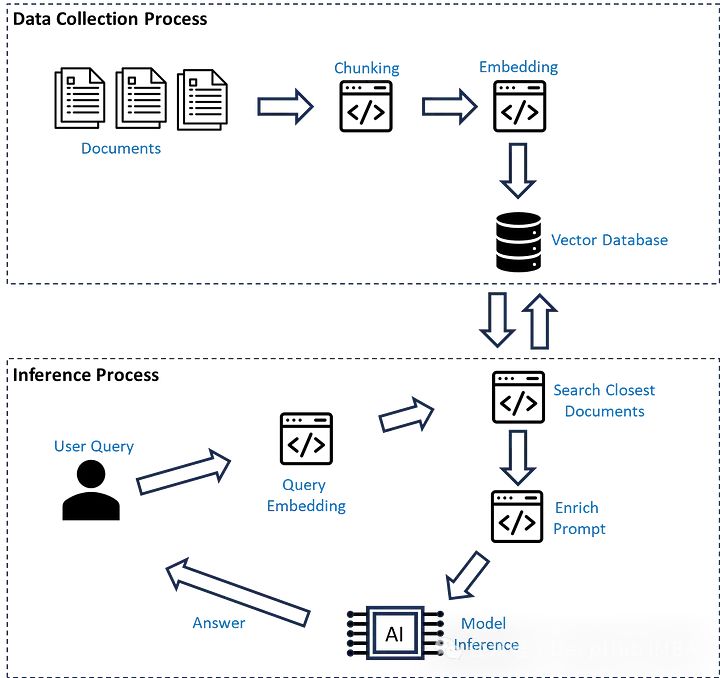
RAG流程优化(微调)的4个基本策略
在本文中,我们将介绍使用私有数据优化检索增强生成(RAG)的四种策略,可以提升生成任务的质量和准确性。通过使用一些优化策略,可以有效提升检索增强生成系统的性能和输出质量,使其在实际应用中能够更好地满足需求。
英伟达推出”生成式AI专业认证“,帮你成为大模型开发专家!
同时英伟达也推出了相应的培训课程,包括生成式AI解释,深度学习入门/基础知识,基于Transformer 的自然语言处理,使用大语言模型进行定制应用开发,大语言模型的部署、定制、微调等,帮助学员顺利通过考试。该认证由英伟达颁发,考试主题包括生成式AI和大语言模型两大块,考试时间1小时,包括50道题,



