
如果你一直在关注大型语言模型的架构,你可能会在最新的模型和研究论文中看到“SwiGLU”这个词。SwiGLU可以说是在大语言模型中最常用到的激活函数,我们本篇文章就来对他进行详细的介绍。SwiGLU其实是2020年谷歌提出的激活函数,它结合了SWISH和GLU两者的特点。

我们一个一个来介绍:
Swish
Swish是一个非线性激活函数,定义如下:
Swish(x) = x*sigmoid(ßx)
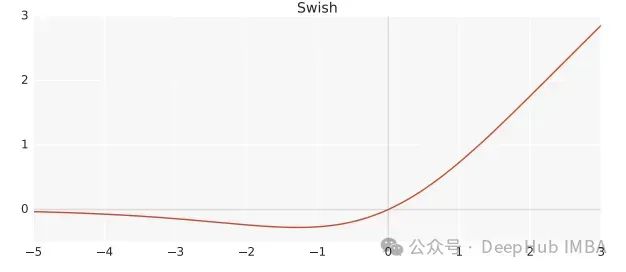
其中,ß 为可学习参数。Swish可以比ReLU激活函数更好,因为它在0附近提供了更平滑的转换,这可以带来更好的优化。
Gated Linear Unit
GLU(Gated Linear Unit)定义为两个线性变换的分量积,其中一个线性变换由sigmoid激活。
GLU(x) = sigmoid(W1x+b)⊗(Vx+c)
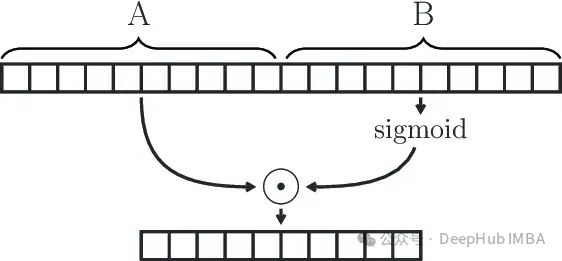
GLU可以有效地捕获序列中的远程依赖关系,同时避免与lstm和gru等其他门控机制相关的一些梯度消失问题。
SwiGLU
上面我们已经说到SwiGLU是两者的结合。它是一个GLU,但不是将sigmoid作为激活函数,而是使用ß=1的swish,因此我们最终得到以下公式:
SwiGLU(x) = Swish(W1x+b)⊗(Vx+c)
我们用SwiGLU函数构造一个前馈网络
FFNSwiGLU(x) = (Swish1(xW)⊗xV)W2
Pytorch的简单实现
如果上面的数学原理看着比较麻烦枯燥难懂,我们下面直接使用代码解释。
class SwiGLU(nn.Module):
def __init__(self, w1, w2, w3) -> None:
super().__init__()
self.w1 = w1
self.w2 = w2
self.w3 = w3
def forward(self, x):
x1 = F.linear(x, self.w1.weight)
x2 = F.linear(x, self.w2.weight)
hidden = F.silu(x1) * x2
return F.linear(hidden, self.w3.weight)
我们代码使用的F.silu函数与ß=1时的swish相同的,所以就直接拿来使用了。
代码可以看到,我们的激活函数中也有3个权重是可以训练的,这就是来自于GLU公式里的参数。
SwiGLU的效果对比
SwiGLU与其他GLU变体进行比较,我们可以看到SwiGLU在两种预训练期间都表现得更好。
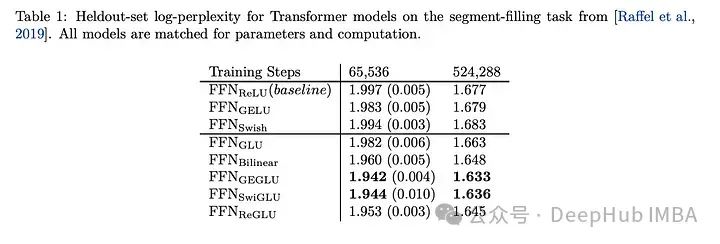
下游任务
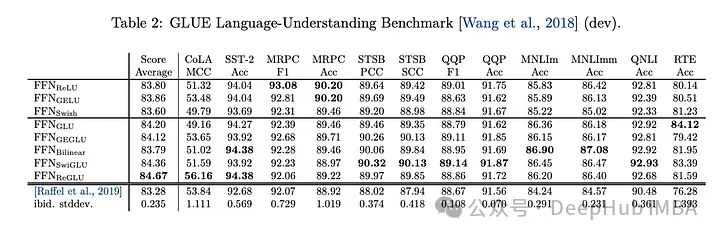
效果表现得最好,所以现在的llm,如LLAMA, OLMO和PALM都在其实现中采用SwiGLU。但是为什么SwiGLU比其他的好呢?
论文中只给了测试结果而且并没有说明原因,而是说:
We offer no explanation as to why these architectures seem to work; we attribute their success, as all else, to divine benevolence.
作者说炼丹成功了。
但是现在已经是2024年了我们可以强行的解释一波:
1、Swish对于负值的响应相对较小克服了 ReLU 某些神经元上输出始终为零的缺点
2、GLU 的门控特性,这意味着它可以根据输入的情况决定哪些信息应该通过、哪些信息应该被过滤。这种机制可以使网络更有效地学习到有用的表示,有助于提高模型的泛化能力。在大语言模型中,这对于处理长序列、长距离依赖的文本特别有用。
3、SwiGLU 中的参数 W1,W2,W3,b1,b2,b3W1,W2,W3,b1,b2,b3 可以通过训练学习,使得模型可以根据不同任务和数据集动态调整这些参数,增强了模型的灵活性和适应性。
4、计算效率相比某些较复杂的激活函数(如 GELU)更高,同时仍能保持较好的性能。这对于大规模语言模型的训练和推理是很重要的考量因素。
选择 SwiGLU 作为大语言模型的激活函数,主要是因为它综合了非线性能力、门控特性、梯度稳定性和可学习参数等方面的优势。在处理语言模型中复杂的语义关系、长依赖问题、以及保持训练稳定性和计算效率方面,SwiGLU 表现出色,因此被广泛采用。
论文地址
https://arxiv.org/abs/2002.05202
作者:Aziz Belaweid