
在本篇文章我们将详细讨论推测解码,这是一种可以将LLM推理速度提高约2 - 3倍而不降低任何准确性的方法。我们还将会介绍推测解码代码实现,并看看它与原始transformer 实现相比到底能快多少。

推测解码是一种“先推测后验证” (Draft-then-Verify) 的解码算法,涉及并行运行两个模型,可与i将语言模型推理的速度有望提高2-3倍。
自回归抽样
从语言模型生成文本的标准方法是使用自回归采样,其中解码K个标记需要对模型进行K次串行运行。
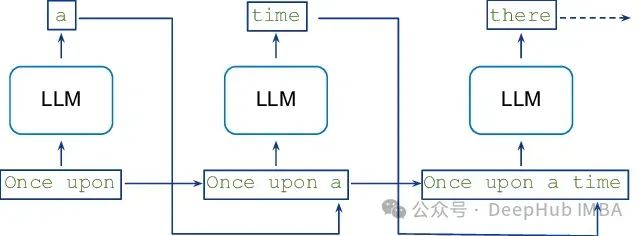
从像Transformers 这样的大型自回归模型中进行推理是缓慢的——解码K个令牌需要对模型进行K次连续运行。
def generate(prompt: str, tokens_to_generate: int) -> str:
tokens = tokenize(prompt)
for i in range(tokens_to_generate):
next_token = model(tokens)
tokens.append(next_token)
return detokenize(tokens)
推测解码
使用一种称为推测解码的方法可以使语言模型(LLM)在不改变其结果的情况下工作得更快。通过并行运行两个模型,有望将LLM推理的速度提高2 - 3倍,这两个模型是
1、目标模型;在任务中使用的主要LLM;2、小型草稿模型:一个更小,轻量级的LLM,与主LLM一起运行,以帮助加快主LLM的推理过程。目标模型和草稿模型都必须使用相同的标记器。
他的工作工作方式如下:
预测一个token“of”非常容易,而且它可能很容易被更小的模型预测,因此使用较小的模型来预测容易的token,而使用大模型只用于预测更困难的token。

虽然模型通常一次生成一个单词,但它们可以一次处理多个令牌。在生成下一个标记时,它们需要一次检查序列中的所有标记。较小的模型预测“Toronto”,但正确的单词是“Edinburgh”,较大的模型可以看到“Toronto”的概率较低,并将其修正为“Edinburgh”。
语言建模任务通常包括一些更容易的子任务,这些子任务可以通过更有效的轻量级模型很好地解决,这些模型的执行时间非常短。当在LLM上执行推理时,推测解码使用较小的草稿模型生成推测令牌,然后目标LLM验证由较小草稿模型生成的那些草稿输出令牌。通过推测执行,可以更快地从大型模型生成精确解码。这是通过同时在较小模型的粗略猜测上运行较大模型来实现的。这意味着我们可以在一个较大模型的前向传播中生成几个令牌,而不改变输出分布。
所以推测解码提供的加速在很大程度上取决于草稿模型的选择。使用更通俗的语言描述就是,使用一个小模型来编写草稿,然后让大模型对草稿进行修正。

上图的算法解释如下:
(1)使用更高效的小模型Mq生成γ完井。
(2)使用目标模型Mp来并行评估所有来自Mq的猜测及其各自的概率,接受所有可能导致相同分布的猜测。
(3)从调整后的分布中采样一个额外的令牌,修复第一个被拒绝的令牌。或者如果它们都被接受,则添加一个额外的令牌。这样目标模型Mp的每次并行运行将至少产生一个新的标记(即使在最坏的情况下,目标模型的串行运行的数量也永远不会大于简单的自回归方法),但它可以潜在地生成许多新的标记(最高可达γ + 1),这取决于Mq和Mp输出的近似程度
代码实现和实验结果
为了运行和评估LLM,所以需要一个显存大一些的GPU,这里使用NVIDIA RTX 6000。
我们使用transformers库直接指定assistant_model就可以实现推测解码
fromtransformersimportAutoModelForCausalLM, AutoTokenizer
importtorch
prompt="Alice and Bob"
checkpoint="EleutherAI/pythia-1.4b-deduped"
assistant_checkpoint="EleutherAI/pythia-160m-deduped"
device="cuda"iftorch.cuda.is_available() else"cpu"
tokenizer=AutoTokenizer.from_pretrained(checkpoint)
inputs=tokenizer(prompt, return_tensors="pt").to(device)
model=AutoModelForCausalLM.from_pretrained(checkpoint).to(device)
assistant_model=AutoModelForCausalLM.from_pretrained(assistant_checkpoint).to(device)
outputs=model.generate(**inputs, assistant_model=assistant_model)
print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
这里的参数num_assistant_tokens:定义在每次迭代中由目标模型检查之前,草稿模型应生成的_speculative token_的数量。较高的' num_assistant_tokens '值使生成更好:如果辅助模型性能良好,则可以达到较大的加速,如果辅助模型需要大量修正,则可以达到较低的加速。
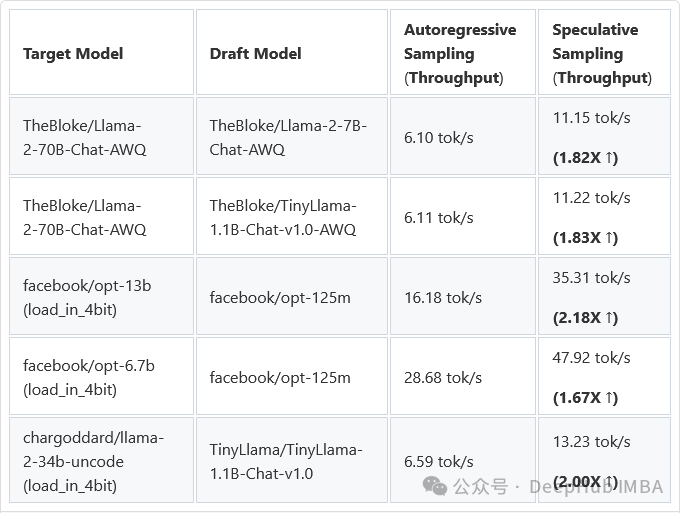
最后我们来看看结果:
总结
我们看到,推理的速度的还真是有2倍的提升,并且还可以看到我们的草稿模型要比目标模型小了10倍左右(1.4B和160M)
Deepmind论文中提到的2 - 2.5倍的加速比也可能适用于70B目标模型和7B草稿模型,所以如果多卡的话可以加载2个大语言模型来提供加速。
以下是推测解码的论文
https://arxiv.org/abs/2302.01318
和一个非官方的实现: