
GitHub CoPilot拥有超过130万付费用户,部署在5万多个组织中,是世界上部署最广泛的人工智能开发工具。使用LLM进行编程辅助工作不仅提高了生产力,而且正在永久性地改变数字原住民开发软件的方式,我也是它的付费用户之一。
低代码/无代码平台将使应用程序创建、工作流自动化和数据分析更加广泛的应用,这种变革潜力支撑着人们对开源替代方案的极大兴趣,我们今天将要介绍的这个令人兴奋的发展。最近BigCode与NVIDIA合作推出了StarCoder2,这是一系列专为编码而设计的开放式LLM,我认为在大小和性能方面是目前最好的开源LLM。
在本文中,我们将介绍StarCoder2的一些基本信息,然后建立一个本地环境,搭建StarCoder2-15B模型并用Python, JavaScript, SQL, c++和Java测试其编码能力。
StarCoder2简介
StarCoder2模型有三种不同大小可供选择,包括3B、7B和15B参数,并且支持广泛的编程语言。每个模型都是在The Stack v2上进行训练的,这是当前最广泛的用于LLM预训练的开源代码数据集。模型的主要特点如下:
- 3B(由ServiceNow提供)、7B(由Hugging Face提供)和15B参数版本(由NVIDIA使用NVIDIA NeMo)
- 所有模型使用分组查询注意力(Grouped Query Attention)
- 上下文窗口为16,384个标记,滑动窗口注意力为4,096个标记
- 模型是使用填空目标(Fill-in-the-Middle objective)进行训练的
- 训练时使用了3+ T(3B)、3.5+ T(7B)、4+ T(15B)标记以及600多种编程语言
- StarCoder2–15B在StarCoder2模型中是最佳的,并在许多评估中与其他33B+模型相匹配。StarCoder2–3B的性能与StarCoder1–15B相当
- 训练时使用了1024 x H100 NVIDIA GPU
- 所有模型均具有商业友好的许可证
StarCoder2的能力(特别是15B模型)在性能指标中明显优于其他相同尺寸的模型,并且与CodeLlama-34B相匹配。
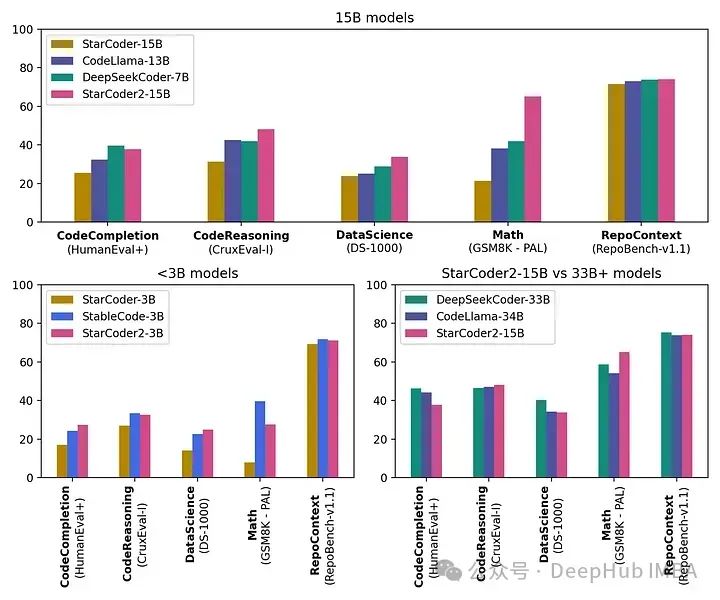
在具有16K标记的上下文长度下,模型处理广泛的代码库和指令,确保了全面的代码理解和生成能力。
StarCoder2安装
为了简单起见,我们使用venv创建虚拟环境,然后安装相应的包
# Create a virtual environment
mkdirstarcoder2&&cdstarcoder2
python3-mvenvstarcoder2-env
sourcestarcoder2-env/bin/activate
# Install dependencies
pip3installtorch
pip3installgit+https://github.com/huggingface/transformers.git
pip3installdatasets
pip3installipykerneljupyter
pip3install--upgradehuggingface_hub
pip3installaccelerate# to run the model on a single / multi GPU
pip3installbitsandbytes
# Loging to Huggingface Hub
huggingface-clilogin
# Optionally, fire up VSCode or your favorite IDE and let's get rolling!
code .
看看15B模型的内存占用:
torch.bfloat16,~32.2 GBload_in_8bit, ~16.9 GBload_in_4bit, ~9.2 GB
可以看到,如果使用24G的GPU,那么最高的量化模型是8bit,所以这里我们呢直接使用它
fromtransformersimportAutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
#如果你的内存太小需要使用 4bit 那么用这个参数 `load_in_4bit=True`
quantization_config=BitsAndBytesConfig(load_in_8bit=True)
checkpoint="bigcode/starcoder2-15b"
tokenizer=AutoTokenizer.from_pretrained(checkpoint)
model=AutoModelForCausalLM.from_pretrained(checkpoint, quantization_config=quantization_config)
这样模型就会自动下载和加载
让我们检查模型的内存占用:
print(f"Memory footprint: {model.get_memory_footprint() /1e6:.2f} MB")
# Memory footprint: 16900.18 MB
这样模型就算加载成功了,下面我们使用5道不同语言的编码题,如Python, JavaScript, SQL, c++和Java,来评估其编码能力。
编码能力测试
我们直接调用generate函数就可以获得模型的输出,这里也可以更改max_length来获得更多的上下文
inputs=tokenizer.encode("def factorial(n):", return_tensors="pt").to("cuda")
outputs=model.generate(inputs, eos_token_id=tokenizer.eos_token_id, max_length=100, num_return_sequences=1)
print(tokenizer.decode(outputs[0]))
下面的prompt就是我们让它为我们的函数进行补全,我们输入的是
def factorial(n):
让模型帮我们继续生成这个函数,结果如下:
def factorial(n):
if n == 0:
return 1
else:
return n * factorial(n-1)
print(factorial(5))
Python中使用递归计算数字的阶乘是正确的。当调用factorial(5)时,它会正确地计算出5。如果n == 0,返回1,确保递归正确结束。因为我们没有输入任何要求,所以它返回这个结果没有任何问题,并且这个函数是可以正确运行的,看样子还不错。
下面我们来进行一个JS的问题,后面我们就不编写代码了,直接输入我们的prompt
function filterArray(arr) {
// Complete the function to filter out numbers greater than 10
结果如下:
function filterArray(arr) {
// Complete the function to filter out numbers greater than 10
return arr.filter(function(num){
return num <= 10;
});
}
filterArray函数使用array .prototype.filter方法,该方法创建一个包含所有通过所提供函数实现的测试的元素的新数组。测试是num <= 10,因此新数组将只包含小于或等于10的数字,有效地过滤掉所有大于10的数字。这也是按照我们的函数注释要求来编写的。
下一个是SQL语句
# generate a SQL query that selects all columns from a table named 'employees' where the 'salary' is greater than 50000.
SELECT * FROM employees WHERE
结果如下:
SELECT * FROM employees WHERE
salary > 50000;
c++
#include <iostream>
class Rectangle {
private:
int width, height;
public:
Rectangle(int w, int h) : width(w), height(h) {}
// Complete the class with methods to calculate area and perimeter
int getArea();
int getPerimeter();
};
结果如下:
#include <iostream>
class Rectangle {
private:
int width, height;
public:
Rectangle(int w, int h) : width(w), height(h) {}
// Complete the class with methods to calculate area and perimeter
int getArea();
int getPerimeter();
};
int Rectangle::getArea() {
return width * height;
}
int Rectangle::getPerimeter() {
return 2 * (width + height);
}
int main() {
int w, h;
std::cin >> w >> h;
Rectangle r(w, h);
std::cout << r.getArea() << std::endl;
std::cout << r.getPerimeter() << std::endl;
return 0;
}
Rectangle类的实现是正确的。它正确地定义了成员函数getArea和getPerimeter,分别计算并返回矩形的面积和周长。main函数从标准输入中读取矩形的宽度和高度,然后创建一个rectangle对象r并输出其面积和周长。
运行这个程序时,它将等待用户输入两个整数(表示宽度和高度),然后它将根据这些值显示计算出的面积和周长。
Java
public class Main {
public static boolean isPrime(int number) {
// Complete the method to check if number is prime
}
}
结果如下:
public class Main {
public static boolean isPrime(int number) {
if (number <= 1) {
return false;
}
for (int i = 2; i < number; i++) {
if (number % i == 0) {
return false;
}
}
return true;
}
}
代码在语法和逻辑上都是正确的,它涵盖了排除小于或等于1的数字的基本情况,并迭代检查给定数字的任何除数。如果找到除数,则返回false;如果没有找到除数,则返回true,正确识别该数为素数。
总结
上面的几个简单的例子可以证明StarCoder2作为Copilot的本地替代应该是没有问题的,我们日常工作中也只是让LLM帮我们完成一些简单的代码,并不会让他进行具体的系统设计工作,所以StarCoder2在这方面应该是没问题的。
但是我们也可以看到在所有这些例子中,代码都是有优化的空间的,如果你需要极致的效率恐怕StarCoder2做不到,估计Copilot也做不到。
目前看StarCoder2是拥有巨大的潜力,特别是考虑到它的大小和性能指标。虽然完全取代GitHub Copilot估计还做不到。因为它还有一些小毛病,比如在提供解决方案后,它会不时输出额外的乱码(这可能和精度有关,据说使用版精度或全精度会好,但我不确定)。
另外就是它需要在本地占用大约16G的显存,如果没有显卡使用cpu推理的话那就需要额外的16G内存,并且速度还很慢(但是国内Copilot也不快)。
如果你没有Copilot它还是值得一试的,因为毕竟对于我们来说多了一个选择和获取解决方案的渠道。这里我们也可以看到在2024年这类高性能的开源编码LLM还会继续发展,我们会深入的关注它的发展。
论文地址:
https://drive.google.com/file/d/17iGn3c-sYNiLyRSY-A85QOzgzGnGiVI3/view
github代码
https://github.com/bigcode-project/starcoder2/
训练数据集
https://huggingface.co/datasets/bigcode/the-stack-v2/
作者:Datadrifters