
长上下文大型语言模型(LCLLMs)确实引起了一些关注。这类模型可能使某些任务的解决更加高效。例如理论上可以用来对整本书进行总结。有人认为,LCLLMs不需要像RAG这样的外部工具,这有助于优化并避免级联错误。但是也有许多人对此持怀疑态度,并且后来的研究表明,这些模型并没有真正利用长上下文。还有人声称,LCLLMs会产生幻觉错误,而其他研究则表明,较小的模型也能高效解决这些任务。
关于长上下文大型语言模型是否真正利用其巨大的上下文窗口,以及它们是否真的更优越,这些问题仍然没有定论,因为目前还没有能够测试这些模型的基准数据集。
但是要充分发挥LCLLMs的潜力,需要对真正的长上下文任务进行严格评估,这些任务在现实世界应用中很有用。现有的基准测试在这方面表现不佳,它们依赖于像“大海捞针”这样的合成任务或固定长度的数据集,这些数据集无法跟上“长上下文”的不断发展的定义。
所以DeepMind最近构建了一个名为Long-Context Frontiers(LOFT)新基准数据集,试图解决这一不足。这个新数据集包括六个任务,涵盖了35个数据集,这些数据集跨越文本、视觉和音频模态。
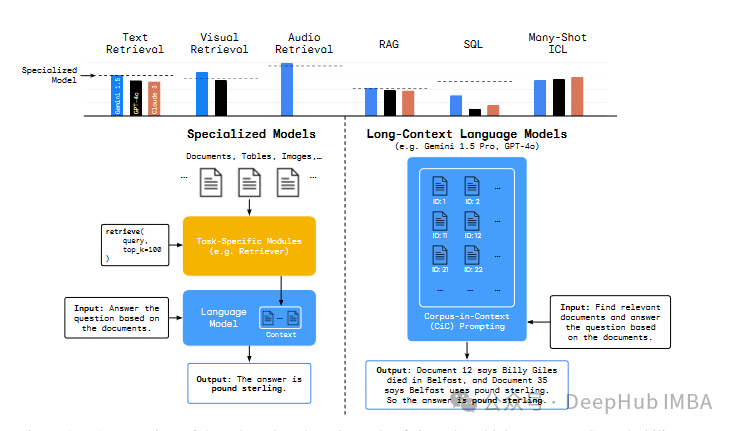
这些任务包括:
- 文本、视觉和音频检索:该数据集旨在测试模型在多跳推理、指令遵循和少量样本任务适应等重要挑战上的能力,你可以在文本、视觉和音频模态中测试这些能力。
- 检索增强生成(RAG):在整个语料库上进行推理,并由于检索遗漏而减少错误。
- SQL:将整个数据库作为文本处理,从而避免进行SQL转换。
- 多样本ICL:扩大在上下文中学习的示例数量,以避免找到少量样本的最佳数量。
这些新任务和数据集的引入,旨在为长上下文模型的开发和评估提供更全面和现实的测试场景,从而更好地理解和利用这些模型在多模态环境中的潜力。
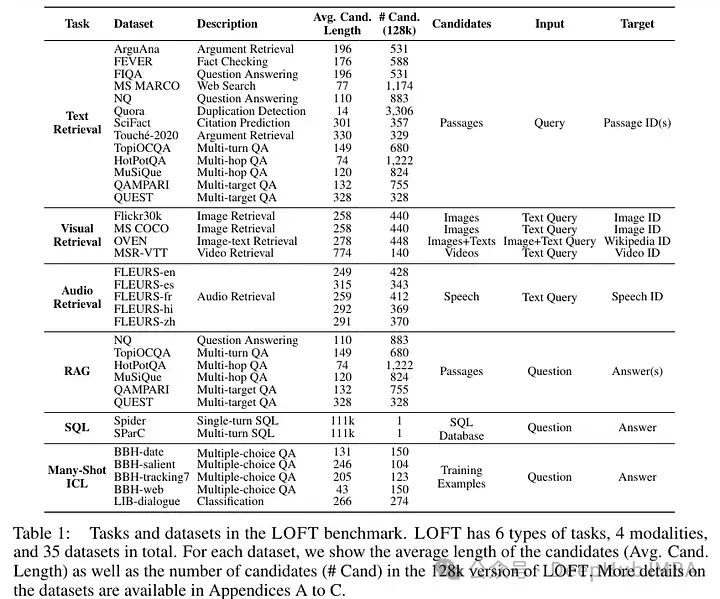
在考虑新类型任务时,作者们创造了他们所称的一种新提示方式:语料库上下文提示(Corpus-in-Context Prompting)。换句话说,整个语料库都在提示中。这个提示包括:
- 指令:一套指导模型的指令。
- 语料库格式化:他们将整个语料库插入到提示中,并为语料库中的每个元素(例如,段落、图像、音频)添加一个唯一标识符(以便在需要时可以识别)。
- 格式化的重要性:对作者而言,格式化对于提高检索精度尤为重要,特别是对于仅解码器中的因果注意力。
- 少量样本示例:提供有限数量的演示有助于让大型语言模型(LLM)掌握所需的响应格式,并提高任务准确性。示例是从同一语料库中选择的,以便学习关于语料库的细节。
- 查询格式化:查询格式化类似于少量样本中的一个,以提高响应的相关性和准确性。
这种方法的设计旨在让模型能够更好地处理和理解大量、多模态的信息,同时减少处理错误或误解的可能。通过这种结构化的提示方式,模型不仅能够更有效地从语料库中检索信息,还能根据具体任务需求进行适当的响应。这种方法的引入可能会对未来的大型语言模型的开发和评估产生重要影响,尤其是在处理长上下文或复杂查询的场景中。

编码高达一百万个令牌的上下文可能会很慢且计算成本高昂。语料库上下文提示(CiC)的一个关键优势在于它与自回归语言模型中的前缀缓存兼容,因为查询出现在提示的末尾。这意味着语料库只需要被编码一次,类似于传统信息检索中的索引过程。
尽管这种方法看起来复杂,但对于作者来说,这种提示与前缀缓存兼容,因此在模型中只需编码一次。
作者决定使用以下模型来比较他们的方法:
- Google的Gemini 1.5 Pro(上下文长度超过2M)。
- GPT-4o(128K上下文长度)。
- Claude 3 Opus(200K上下文长度)。
- 为手头任务开发的专门模型。例如,Gecko是一种最新的双编码器,作为检索任务的专门模型。
这种比较的设定旨在展示不同模型处理长上下文任务的能力,并评估CiC提示策略在实际应用中的效果。通过这种方式,可以更清楚地理解各种模型在处理复杂查询和长上下文信息时的性能差异。
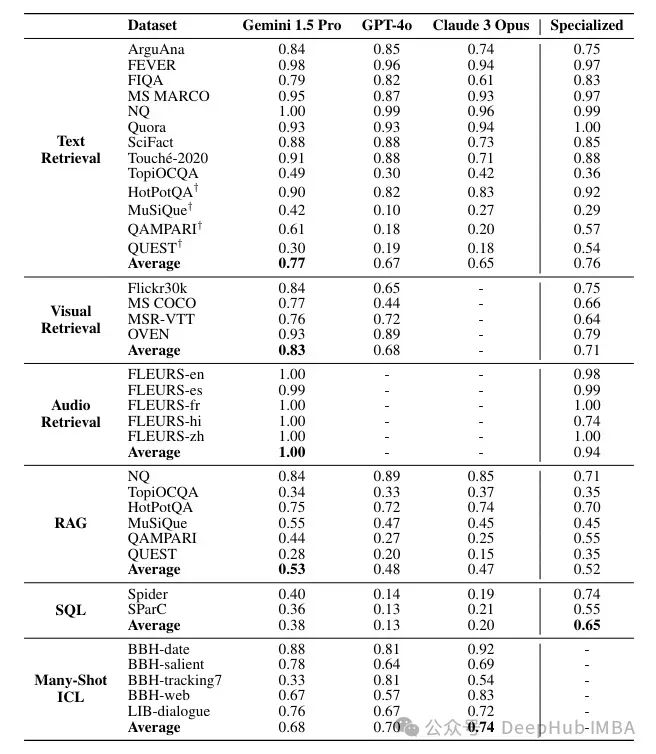
对于作者来说,使用提示的Gemini模型的表现与专门模型一样好。当上下文减少到100万个令牌时,性能会有所下降,但在Gecko模型中这种下降不太明显。
这表明Gemini模型在处理大量上下文时具有较强的能力,尤其是当利用语料库上下文提示(CiC)策略时。然而,即使在上下文量减少时,专门为检索任务设计的Gecko模型仍能保持较高的性能水平。这种差异可能源于Gecko模型特有的结构和优化,使其更适合处理大规模的信息检索任务,即便在较长的上下文中也能有效地减少性能退化。
这些发现对于理解不同类型的语言模型在处理长上下文任务时的优势和局限具有重要意义,也为未来模型的设计和优化提供了宝贵的参考。
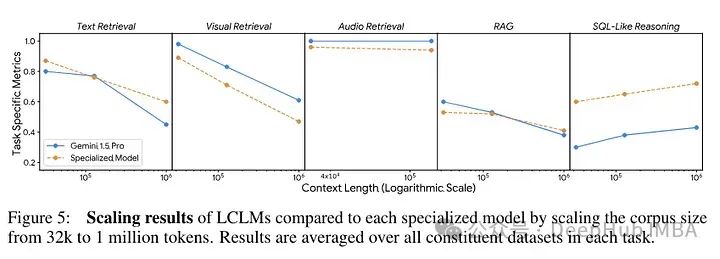
如果需要找到的文档位于上下文长度的末尾,性能会有所下降,这主要是因为在提示的后部分注意力减弱。这是自回归模型处理长文本时常见的问题,尤其是在那些需要维持高度注意力跨度的任务中。
在自回归语言模型中,由于解码过程是按顺序进行的,模型在处理长文本的后部时可能不如前部那样敏感和精确。这种现象通常被称为“注意力衰减”(attention decay),意味着模型在对长距离依赖进行编码时的效果会随着距离的增加而逐渐减弱。
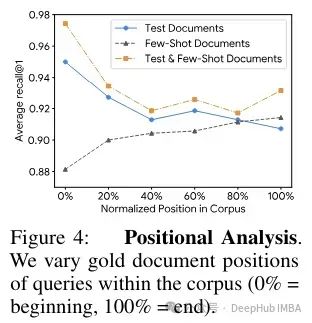
作者指出:
- Gemini 1.5 Pro 在所有四个视觉基准测试中都优于 GPT-4o。Gemini 也优于 CLIP 的文本到图像检索。
- Gemini 1.5 Pro 在音频检索方面与专门模型 PaLM 2 DE 表现相当。
- 在多跳数据集上的检索增强生成(RAG)流程中,Gemini 表现更为优越。这是因为长上下文大型语言模型(LCLLM)能够进行多步骤推理(而简单的 RAG 并不支持这一点)。
对于作者来说,这种性能主要源于长上下文的使用,而不是参数记忆,因为当移除上下文时,性能会显著下降。这表明,Gemini 模型的高性能依赖于其能够访问和处理大量上下文信息的能力。当这些上下文被移除时,模型的性能会受到重大影响,这强调了长上下文在处理复杂问题和任务时的重要性。
长上下文的使用不仅提高了模型在特定任务上的性能,也使得模型在面对需要广泛信息和多步推理的复杂场景时更加有效。但是这也暴露了模型在缺乏足够上下文支持时的局限性,进一步表明改进模型的上下文管理和处理能力是未来发展的一个关键方向。
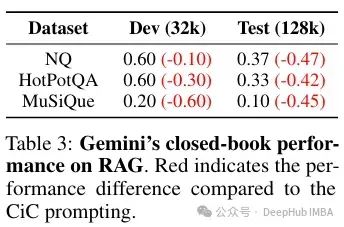
在文章中提到,虽然 Gemini 在SQL任务上相比于专门的处理流程表现落后(这并不令人意外,因为这些流程现在已经非常成熟,能够处理复杂的分析),但它在多样本上下文学习(Many-Shot ICL)任务中表现优于 GPT-4,在这种任务中,它实际上是在扩大上下文中的示例数量。Claude 似乎表现更好。增加示例数量似乎是有益的,并且性能呈单调增加。但是在更复杂的任务中,情况并非如此,更多的示例似乎并没有带来益处。
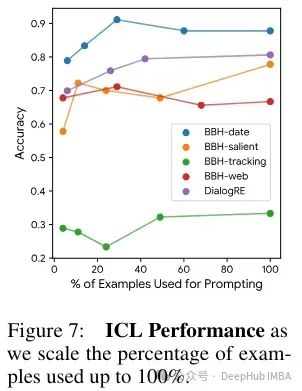
这些结果表明,在更复杂的任务中,模型从扩大上下文示例数量中学习的能力可能会更早地达到极限。这暗示了在处理高复杂度任务时,仅仅增加上下文中的示例数量并不能持续提升模型的性能,反而可能达到一个性能瓶颈。
这一发现强调了在设计和优化语言模型用于复杂任务处理时的挑战。它提示我们,在这些情境下,可能需要探索更多的优化策略或者引入新的模型架构,而不是简单地依赖增加上下文示例的数量。此外,这也表明了模型的泛化能力和适应复杂数据结构的能力在实际应用中的重要性。这种理解有助于未来在设计模型和训练策略时做出更加明智的选择,尤其是在面对多样化和高复杂度任务的场景中。
这项研究通过引入LOFT(Long Context Frontiers benchmark)来衡量长上下文大型语言模型(LCLLMs)的进展。LOFT是一组旨在为检索、检索增强生成、类SQL推理和上下文中学习等任务提供严格评估的任务套件,这些任务被认为是技术变革的成熟领域。
但是该数据集也存在一些局限性。首先是成本问题,如作者所述:
LOFT 128k 测试集包含大约35个数据集×100个提示×128k 令牌 = 448M 输入令牌,根据当前的计算,对于Gemini 1.5 Pro的成本是$1,568,对于GPT-4o是$2,240,而对于Claude 3 Opus是$6,720。为了降低成本,论文还发布了开发集,这些开发集的大小是原来的十分之一,使用Gemini 1.5 Pro或GPT-4o评估的成本大约是$200。
这项研究并没有显示出使用长上下文的明显优势。Gemini似乎并不优于Gecko(由DeepMind发布的模型,因此讨论的公平性有限)。在实际使用时 RAG的成本并不是高,因为RAG的检索的成本与大量的令牌成本基本相似,并且对于大多数工业应用来说,2M个令牌还远远不够。
并且,这项研究并没有消除关于长上下文的疑虑。基准测试中所有模型的表现都非常高,而且可能并不需要使用LCLLM来解决问题,一个正确设置的小型模型就足够了。Google给出的提示对于许多应用来说过于昂贵,而且需要有少量样本(与人们通常使用的更动态、对话式的用法相比)。
最后,作者还表明,模型仍然存在位置问题(可能还包括粒度问题),性能在扩展到100万时迅速下降(大约减半)。
总之,在使用新数据集的这项研究中,LCLLM似乎没有这些所谓的优势,或者至少在这项研究中并没有表现出来。
论文:
Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?