
我们已经看到了语言模型的巨大进步,但时间序列任务,如预测呢?今天我们推荐一篇论文,对现有的语言模型和时间序列做了深入的研究。将探讨了是否可以从大型语言模型(LLMs)中获益于时间序列(TS)预测。
时间序列
时间序列是机器学习中最具挑战性的工作领域之一,解决时间序列任务,如异常检测、时间序列预测等,在多个行业中至关重要,能够节省大量资金。
由OpenAI发起的规模化法则显示,模型能在更多原始数据上更好地泛化结果就得到了ChatGPT。自那以后,大型语言模型(LLMs)吸引了所有人的注意。
自那以后,研究者们一直在尝试将LLMs用于时间序列!这在某种程度上是有道理的,因为无论是语言数据还是时间序列都是序列数据,研究者认为如果LLMs能在语言数据上表现出良好的泛化能力,那么它可能也适用于时间序列。
关于这方面有很多酷炫的研究成果,但问题是“有多少LLMs真正适用于时间序列任务?”
我认为一些工作展示了时间序列的光明未来,例如使用LLMs实现的时间序列推理和理解(代理)等。
时间序列推理:
使用大型语言模型(LLMs)进行时间序列推理可以通过整合三种主要的分析任务来增强时间序列推理:因果推理、问答和辅助上下文预测。
因果推理涉及假设观察到的时间序列模式背后的潜在原因,使模型能够识别最有可能产生给定时间序列数据的场景。
问答使模型能够解释和回应关于时间序列的事实性查询,如识别趋势或对数据变化进行反事实推断。
辅助上下文预测允许模型利用额外的文本信息来增强对未来数据点的预测,整合相关上下文以提高预测准确性。
但当前的LLMs在这些任务中表现出有限的熟练程度,比如在因果和问答任务中的表现仅略高于随机水平,并在辅助上下文预测中显示出适度的改进。
社会理解:
使用大型语言模型(LLMs)进行时间序列分析可以显著提高社会理解,使代理能够系统地分析和预测社会趋势和行为。基于LLM的代理使用来自财经、经济、民调和搜索趋势等多个领域的真实世界时间序列数据来近似社会的隐藏状态。这种近似有助于通过将时间序列数据与新闻和社交媒体等其他信息源相关联,对社会行为进行假设和验证。
通过整合这些多样化的数据流,LLMs能够深入洞察多面且动态的社会问题,促进包含逻辑和数字分析的复杂和混合推理。
这种方法确保代理不仅仅是执行历史数据拟合,而是积极与不断流动的真实世界数据互动并适应,使其分析和预测在真实场景中保持相关和适用。
但是当涉及到时间序列时,这些新模型并没有使用预训练的LMs的自然推理能力。
LLMs对时间序列任务真的有帮助吗?
一项新研究显示,如果我们用注意力层替换语言模型,性能不会有显著变化。即使完全移除它们,性能会变得更好。这甚至可以将训练和推理速度提高多达三个数量级。
研究者选择了三种改造方法:删除或替换LLM组件。这三种修改如下:

不使用LLM(图1(b))。完全移除语言模型,将输入令牌直接传递给参考方法的最后一层。
LLM2Attn(图1(c))。用一个单独的随机初始化的多头注意力层替换语言模型。
LLM2Trsf(图1(d))。用一个单独的随机初始化的Transformer块替换语言模型。
测试结果
使用的数据集主要是所有其他时间序列研究中的基准数据集:ETT、疾病、天气、交通、电力、汇率、Covid死亡人数、出租车(30分钟)、NN5(每日)和FRED-MD。
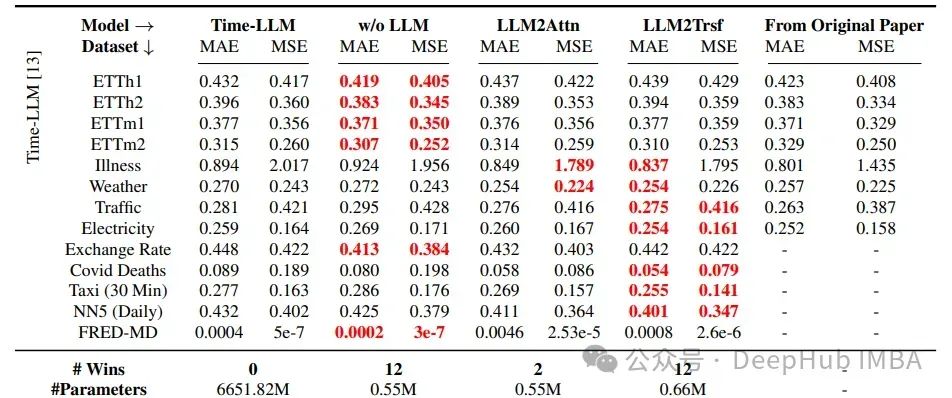
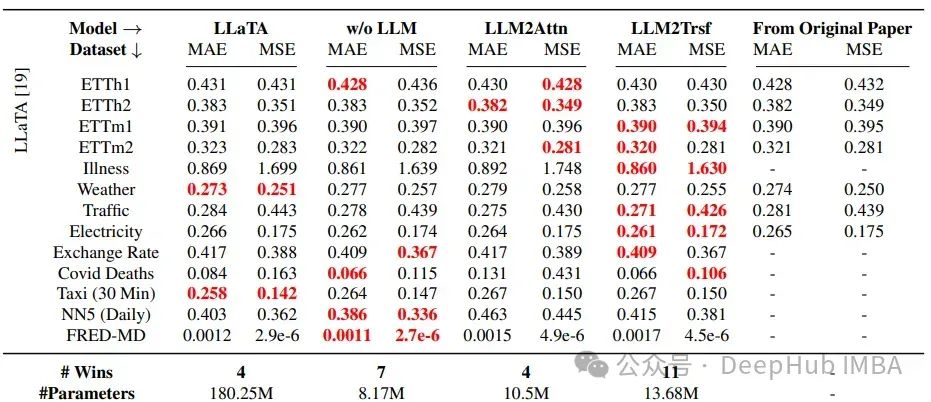
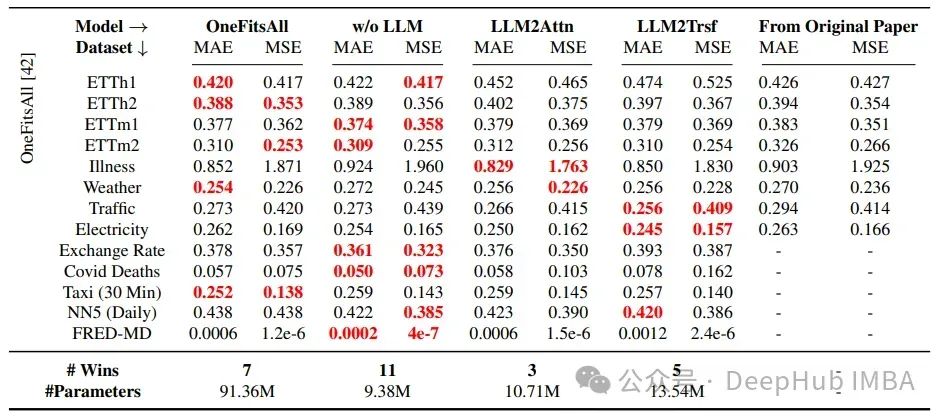
在所有情况下,这些改造方法都优于Time-LLM,在22个中的26个案例中优于LLaTA,在19个中的26个案例中优于OneFitsAll。这里使用的指标是MAE和MSE,分别代表平均绝对误差和均方误差。
可以得出的结论是,LLMs在时间序列预测任务上并没有以有意义的方式提高性能。
现在让我们看一下参数和时间消耗:
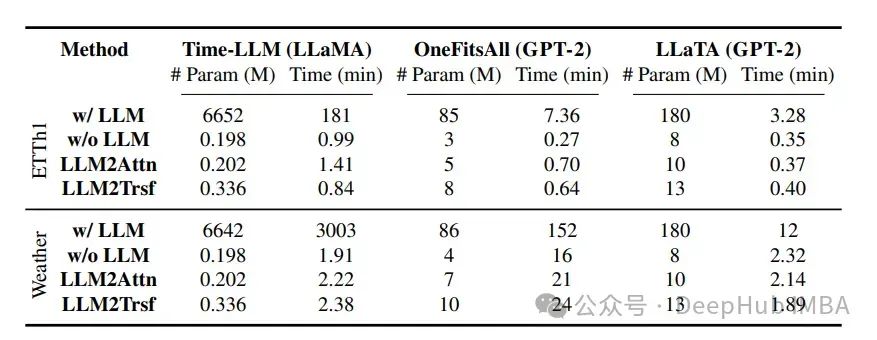
在时间序列任务中,LLM(如LLaMA和GPT-2)显著增加了训练时间。表格显示了在ETTh1和Weather数据上,对长度为96的预测,三种方法的模型参数数量(以百万计)和总训练时间(以分钟计)。与原始方法“带LLM”的比较是“不带LLM”,“LLM2Attn”和“LLM2Trsf”。
Time-LLM、OneFitsAll和LLaTA的平均训练时间分别是修改后模型的28.2倍、2.3倍和1.2倍。这表明,LLMs在时间序列计算上的权衡并不值得。
那么使用语言数据集进行预训练是否能够改善时间序列预测的结果?
该研究采用了四种不同的组合:预训练 + 微调、随机初始化 + 微调、预训练 + 不微调以及随机初始化 + 不微调。
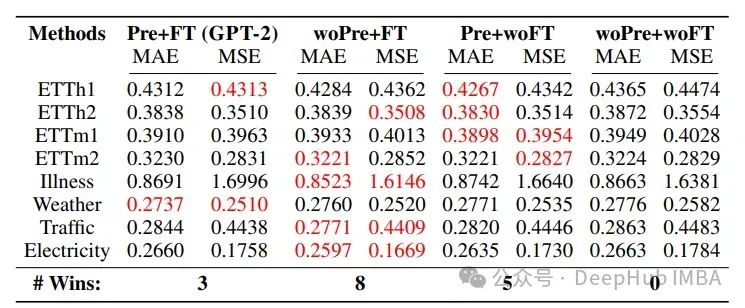
随机初始化LLM参数并从头开始训练(无预训练,woPre)比使用预训练(Pre)模型取得了更好的结果。“无微调”(woFT)和“微调”(FT)分别指的是LLM参数是冻结的还是可训练的。
语言知识对预测的改进非常有限。然而,“预训练 + 不微调”和基线“随机初始化 + 不微调”分别在少样本(5次)和零样本的比较中表现最好,这暗示在微调过程中语言知识并没有帮助。
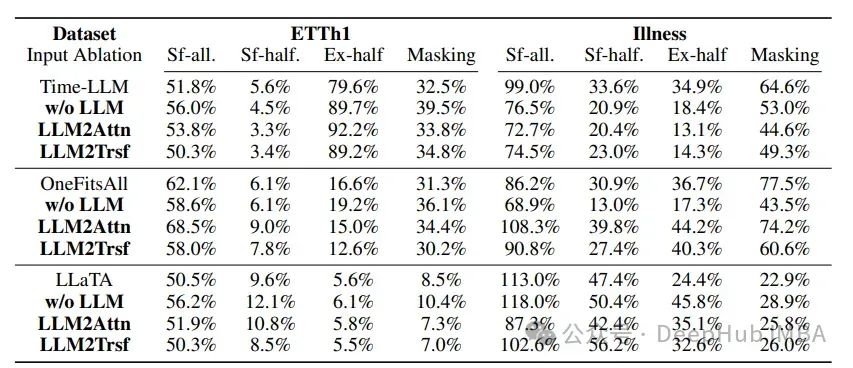
在ETTh1(预测长度为96)和Illness(预测长度为24)的输入打乱/遮蔽实验中,模型修改前后,输入打乱对时间序列预测性能的影响并没有显著变化。
在这个实验中,使用了三种类型的打乱方式:随机洗牌整个序列(“sf-all”),只洗牌序列的前半部分(“sf-half”),以及交换序列的前半部和后半部(“ex-half”)。
结果表明,基于LLM的模型对输入打乱的脆弱性并不比其改造版本更高。
总结
这项研究表明,最好还是让传统的时间序列预测方法继续使用它们习惯的方式,而不是尝试使用大型语言模型来处理时间序列任务。
但是这并不意味着不做任何事情;在时间序列和大型语言模型的交叉领域,还有一些新的、可能值得探索的有趣方向。
论文地址:
https://arxiv.org/abs/2406.16964
作者:Reza Yazdanfar