
现有的RAG解决方案可能因为最相关的文档的嵌入可能在嵌入空间中相距很远,这样会导致检索过程变得复杂并且无效。为了解决这个问题,论文引入了多头RAG (MRAG),这是一种利用Transformer的多头注意层的激活而不是解码器层作为获取多方面文档的新方案。
MRAG
不是利用最后一个前馈解码器层为最后一个令牌生成的单个激活向量,而是利用最后一个注意力层为最后一个令牌生成的H个单独的激活向量,然后通过矩阵Wo(结合所有注意头结果的线性层)对其进行处理。
可以公式化为一组嵌入S = {ek∀k},其中ek = headk(xn),它是输入的最后一个标记xn上的所有注意力头的输出的集合
由于多个头的处理不会改变输出向量的大小,因此具有与标准RAG相同的嵌入空间,这种使用解码器块的多头注意力部分的激活作为嵌入有助于捕获数据的潜在多面性,并且不增加空间需求
MRAG处理流程
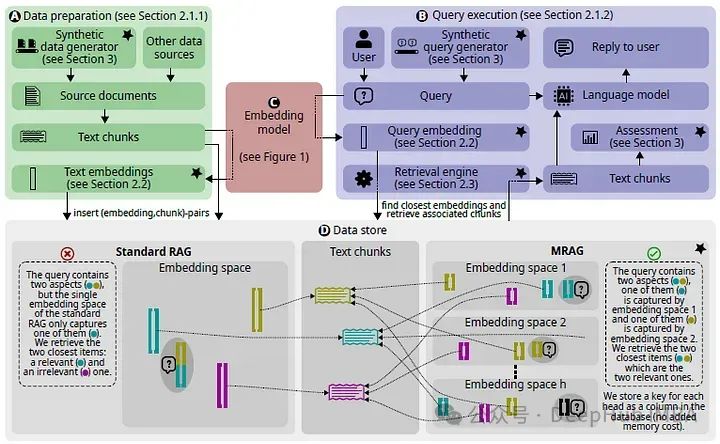
1、数据准备
对于MRAG,每个多向嵌入由h个单向嵌入组成,每个单向嵌入都指向原始文本块,从而产生包含h个嵌入空间的数据存储,每个嵌入空间捕获文本的不同方面。
2、构建multi-aspect嵌入
MRAG可以利用任何具有多头注意力的嵌入模型来为给定的输入文本构建嵌入,论文采用了MTEB排行榜中的两个嵌入模型,即SFR-Embedding-Model和e5-mistral-7b-instruct。实验结果表明,从最后一个多头注意力中提取的嵌入在实验环境下效果最好
3、查询执行
使用选定的嵌入模型生成输入查询嵌入,然后使用一种特殊的multi-aspect检索策略在数据存储中找到最近的多嵌入及其对应的文本块。检索到的数据可以有选择地使用新的度量来评估它与需求的对应程度。
MRAG检索策略包括三个步骤:
a)分配重要性分数
在数据准备过程中,为所有h个嵌入空间分配重要性分数,捕获不同空间(以及相应的头)可能与所使用的数据或多或少相关的分数,下面的算法详细介绍了重要性分数的构造:

一个给定的头部hi的得分si由两个部分组成,ai和bi。
ai是向量空间i中所有嵌入的L2范数的平均值;它代表了给定头部的重要性:规范越大,对该注意头部的关注就越多。
bi是向量空间I中所有嵌入(或随机抽样子集,如果想减少预计算时间)之间余弦距离的平均值。bi是测量向量空间i的“扩展”:Bi越大,该空间中不同嵌入之间的平均角度越大
将si作为ai·bi乘积这样可以确保获得奖励平均关注度高、平均传播度高的头,并且同时惩罚平均关注度低或平均传播度低的头(ai和bi都是适当缩放的)
b)获取最接近的文本块
在查询执行期间,MRAG首先对每个嵌入空间分别应用传统的RAG检索,为每个嵌入空间返回c个最接近的文本块列表(总共h个列表)。然后使用一种特殊的投票策略,用预先计算的重要性分数,从所有hc块中选出前k个块。将来自各个嵌入空间的文本块的构造列表合并到top k块的单个列表中,使用的算法概述如下:

向量空间i的列表i中的每个文本块在这个列表中有一个特定的位置,我们用p表示这个位置。计算块的权重为si·2−p,其中si是前面定义的空间i的重要性分数。乘以2然后减p会降低不太相关的文本块的重要性。
得到权重后,所有列表中的所有块都使用它们的权重排序,前k个块形成最终列表。
实验指标
数据集构建
通过选择n个类别创建查询,从每个选择的类别中抽样一个文档(确保总体上没有重复),然后使用LLM (GPT-3.5 Turbo)生成一个结合这些文档的故事。构建了包含1、5、10、15和20个方面的25个查询(总共125个查询)
给LLM的一个示例查询需要从10个不同的类别中检索10个文档,如下图的顶部所示
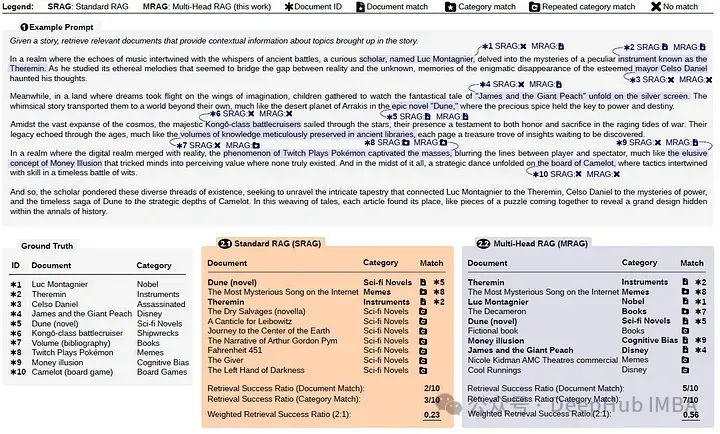
指标计算
对于查询Q、使用的检索策略S和要检索的n个类别中的n个文档,Qrel表示应该为Q检索的理想文档集。然后,S(Q, n)是实际检索的文档集。
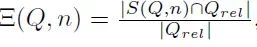
当RAG方案没有检索所需的确切文档,但它仍然成功地从同一类别检索其他文档时,定义了另一个度量,称为类别检索成功率。它与上面提到的度量相同,但有一点不同:S(Q, n)现在是属于理想所需文档类别的所有检索文档的集合。
最后将这两个指标结合起来,得到加权检索成功率。通过改变w,用户可以调整精确文档匹配和类别匹配的重要性
指标评价
论文使用两个主要基线:标准RAG和Split RAG
标准RAG表示传统的RAG管道,其中每个文档使用最后一个解码器层的激活作为其嵌入;Split RAG是标准RAG和MRAG的混合,它以与MRAG相同的方式拆分最后一个解码器层的激活,并应用投票策略。Split RAG的目的是显示MRAG的好处是来自于使用多头输出作为嵌入,而不仅仅是使用多个嵌入空间。Fusion RAG也被认为是一种可选的机制,可以利用它来进一步增强MRAG,但要付出额外令牌查询成本。
下面的箱线图显示了MRAG和标准RAG之间超过25个查询的检索成功率,其中每个查询包括10个不同的方面
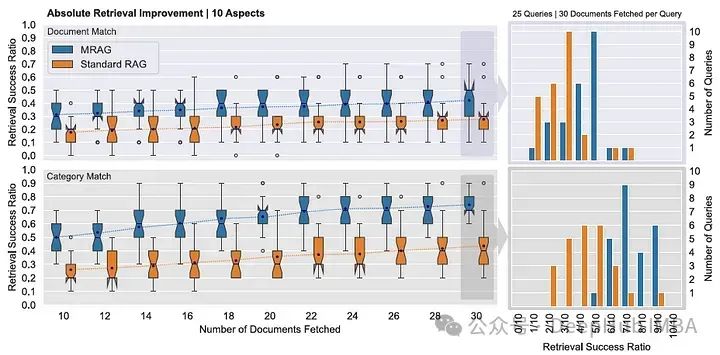
上面的结果表明,MRAG始终优于标准RAG(对于精确的文档匹配,平均检索成功率增加> 10%)。此外,检索性能在类别匹配上的提升更为显著(检索成功率平均提升> 25%)。对于获取的特定数量的文档,MRAG的直方图显示了更好的检索成功率分布(在所有25个查询中)。
下图显示了当我们改变查询中出现的方面的数量时,MRAG相对于标准RAG的加权性能改进
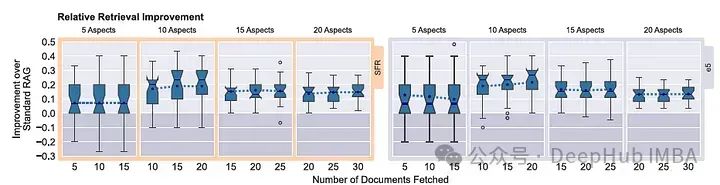
对于这两种模型,MRAG的平均性能始终比标准RAG高出10-20%,下表显示了单个方面的25个查询的检索成功率(精确的文档匹配)
将MRAG与Fusion RAG相结合,使用LLM(额外令牌成本)进行更准确检索的RAG方案。
Fusion RAG使用LLM创建关于RAG查询的固定数量的问题。每个问题通过使用标准RAG的嵌入模型分别应用
下图显示了SFR嵌入模型的MRAG相对于标准RAG的相对检索改进(蓝色图),以及Fusion MRAG相对于Fusion RAG和MRAG的相对检索改进(红色图)。
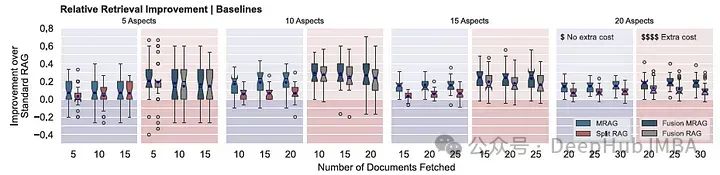
Fusion RAG和Fusion MRAG的性能都优于标准 RAG,平均精度提高了10 - 30%
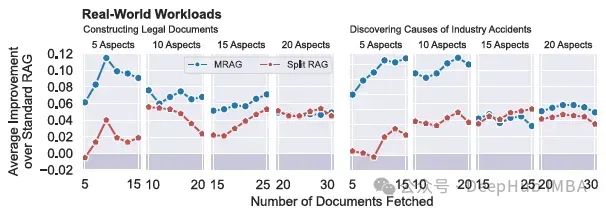
论文还介绍了来自内部行业数据分析项目的两个实际用例,法律文件的合成和工业事故原因的分析下图显示了在构建法律文件(左)和发现工业事故原因(右)的两个实际工作,MRAG和Split RAG相对于标准RAG的检索成功率的平均改进。
总结
论文提出了一种利用解码器模型的多头注意层而不是传统的前馈层激活的新方案——多头RAG (MRAG)。通过综合评估方法,包括具体的度量、合成数据集和实际用例,证明了MRAG的有效性。
MRAG在检索文档的相关性有了显著改善,与传统RAG基线相比,性能提高了20%,并且它不需要额外的LLM查询、或者多个模型实例、也不会增加的存储。
论文: https://arxiv.org/abs/2406.05085
代码: https://github.com/spcl/MRAG
作者:SACHIN KUMAR