Transformer技术深度剖析:AI语言处理的新纪元
Transformer技术深度剖析:AI语言处理的新纪元
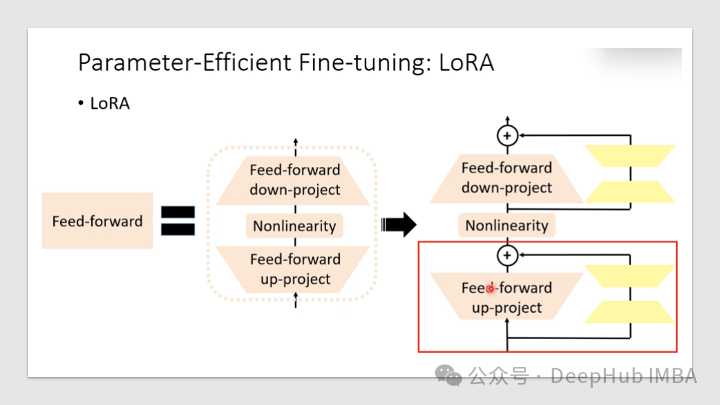
使用LORA微调RoBERTa
LORA可以大大减少了可训练参数的数量,节省了训练时间、存储和计算成本,并且可以与其他模型自适应技术(如前缀调优)一起使用,以进一步增强模型。
深度学习网络模型————Swin-Transformer详细讲解与代码实现
经典网络模型系列——Swin-Transformer详细讲解与代码实现
极智AI | 解读Mamba对LLM基础架构的冲击 作者一定是科密吧
大家好,我是极智视界,本文分享一下 解读Mamba对LLM基础架构的冲击 作者一定是科密吧。希望我的分享能对你的学习有一点帮助。
transformer概述和swin-transformer详解
transformer和swin-transformer
Swin Transformer详解
Vit出现后虽然让大家看到了Transformer在视觉领域的潜力,但并不确定Transformer可以做掉所有视觉任务。Swin Transformer可以作为一个通用的骨干网络。面对的挑战:1、多尺度。2、高像素。移动窗口提高效率,并通过Shifted操作变相达到全局建模能力。层次结构:灵活,可
Transformer模型详解
transformer结构是google在2017年的Attention Is All You Need论文中提出,在NLP的多个任务上取得了非常好的效果,可以说目前NLP发展都离不开transformer。最大特点是抛弃了传统的CNN和RNN,整个网络结构完全是由Attention机制组成。 由于

在Colab上测试Mamba
本文整理了一个能够在Colab上完整运行Mamba代码,代码中还使用了Mamba官方的3B模型来进行实际运行测试。
基于GPT-3、ChatGPT、GPT-4等Transformer架构的自然语言处理
【好书分享 • 第一期】——基于GPT-3、ChatGPT、GPT-4等Transformer架构的自然语言处理

挑战Transformer的新架构Mamba解析以及Pytorch复现
今天我们来详细研究这篇论文“Mamba:具有选择性状态空间的线性时间序列建模”
OpenAI开发系列(二):大语言模型发展史及Transformer架构详解
大语言模型发展史及Transformer架构详解
基于Transformer的多变量风电功率预测TF2
Transformer目前大火,作为一个合格的算法搬运工自然要跟上潮流,本文基于tensorflow2框架,构建transformer模型,并将其用于多变量的风电功率负荷预测。实验结果表明,相比与传统的LSTM,该方法精度更高,缺点也很明显,该方法需要更多的数据训练效果才能超过传统方法,而且占用很高
MAMBA介绍:一种新的可能超过Transformer的AI架构
屹立不倒的 Transformer 迎来了一个强劲竞争者。CMU、普林斯顿研究者发布的MAMBA架构,解决了Transformer核心注意力层无法扩展的致命bug,推理速度直接飙升了5倍!一个时代终于要结束了?
AI生成中Transformer模型
在深度学习中,有很多需要处理时序数据的任务,比如语音识别、文本理解、机器翻译、音乐生成等。Transformer模型由Vaswani等人在2017年的论文《Attention Is All You Need》中首次提出,它在自然语言处理领域引起了巨大变革。该模型摒弃了传统的循环网络结构,转而使用自注
Transformer中的注意力机制及代码
transformer注意力机制实现过程整理。
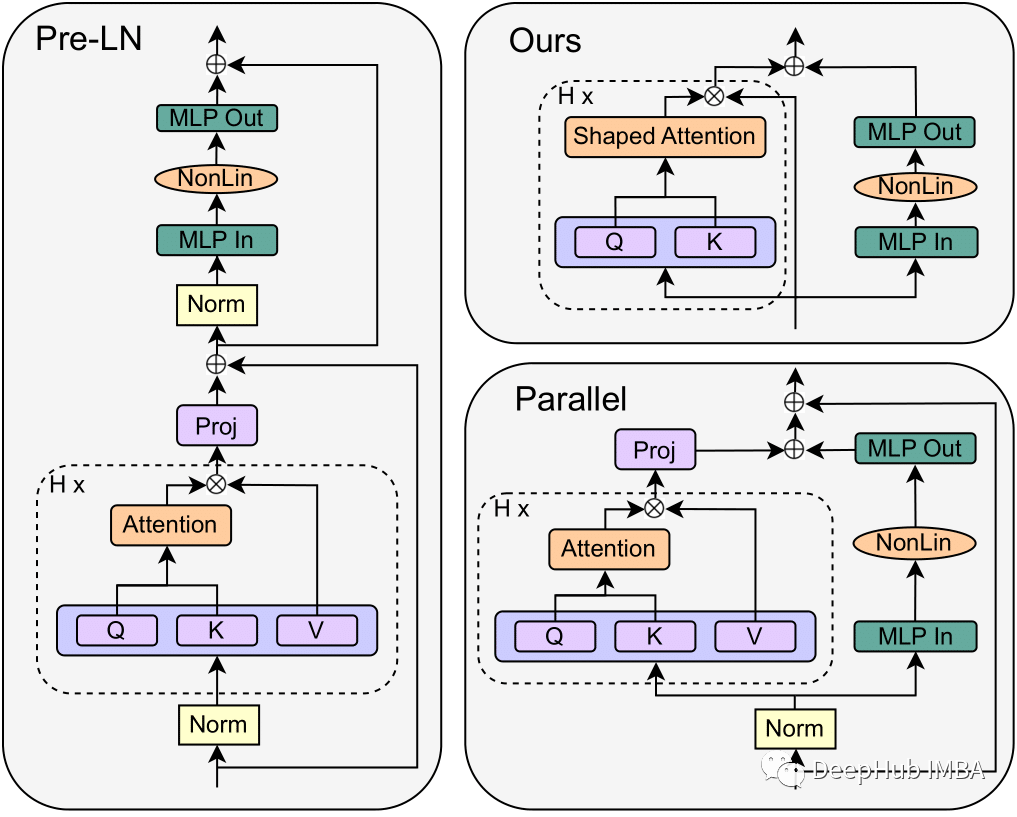
简化版Transformer :Simplifying Transformer Block论文详解
在这篇文章中我将深入探讨来自苏黎世联邦理工学院计算机科学系的Bobby He和Thomas Hofmann在他们的论文“Simplifying Transformer Blocks”中介绍的Transformer技术的进化步骤。这是自Transformer 开始以来,我看到的最好的改进。
DETR(DEtection TRansformer)要点总结
DETR翻译过来就是检测transformer,是Detection Transformers的缩写。这是一个将2017年大火的transformer结构首次引入目标检测领域的模型,是transformer模型步入目标检测领域的开山之作。利用transformer结构的自注意力机制为各个目标编码,依
注意力机制(五):Transformer架构原理和实现、实战机器翻译
注意力机制(Attention Mechanism)是一种人工智能技术,它可以让神经网络在处理序列数据时,专注于关键信息的部分,同时忽略不重要的部分。在自然语言处理、计算机视觉、语音识别等领域,注意力机制已经得到了广泛的应用。注意力机制的主要思想是,在对序列数据进行处理时,通过给不同位置的输入信号分
Swin-transformer详解
这篇论文提出了一个新的 Vision Transformer 叫做 Swin Transformer,它可以被用来作为一个计算机视觉领域一个通用的骨干网络.但是直接把Transformer从 NLP 用到 Vision 是有一些挑战的,这个挑战主要来自于两个方面一个就是尺度上的问题。因为比如说现在有
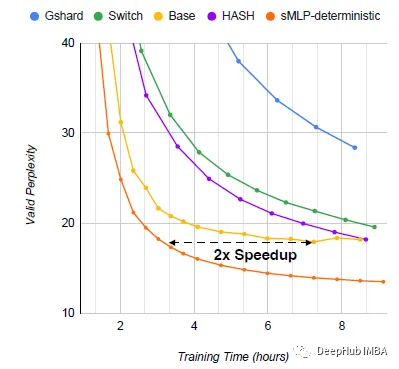
sMLP:稀疏全mlp进行高效语言建模
论文提出了sMLP,通过设计确定性路由和部分预测来解决下游任务方面的问题。



