WiseFlow:开源AI信息挖掘工具,传统的爬虫可以下线了
是一款快速准确的信息挖掘工具。我们在使用时提前设定好自己的。
【模型架构】学习最火热的Mamba、Vision Mamba、MambaOut模型
状态空间模型(State Space Model, SSM)是一种用于描述动态系统的数学模型,特别适用于时间序列分析和控制系统设计。它将系统的状态表示为一个状态向量,并通过状态方程和观测方程描述系统的动态行为和观测过程。因此,SSM是可以用于描述这些状态表示并根据某些输入预测其下一个状态可能是什么的
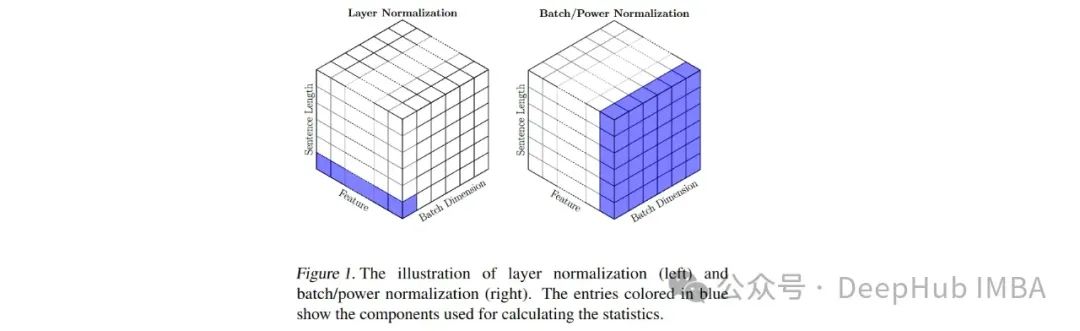
使用BatchNorm替代LayerNorm可以减少Vision Transformer训练时间和推理时间
本文我们将详细探讨ViT的一种修改,这将涉及用批量归一化(BatchNorm)替换层归一化(LayerNorm) - transformer的默认归一化技术。
基于人工智能的口试模拟、LLM将彻底改变 STEM 教育
本文开发了一个基于大规模语言模型的原型,模拟了高等教育中的口试,探索了大规模语言模型在教育环境中的潜力,展示了将人工智能引入教育的广泛可能性。尽管作为一项研究还处于早期阶段,但它为大规模语言模型在这一新应用领域的能力和局限性提供了重要见解,而最新版本的 OpenAI API 及其助手在为不同学生定制
基于Transformer解决机器翻译任务学习笔记记录#AI夏令营 #Datawhale #夏令营
基于循环或卷积神经网络的序列到序列建模方法是现存机器翻译任务中的经典方法。然而,它们在建模文本长程依赖方面都存在一定的局限性。对于卷积神经网络来说,受限的上下文窗口在建模长文本方面天然地存在不足。如果要对长距离依赖进行描述,需要多层卷积操作,而且不同层之间信息传递也可能有损失,这些都限制了模型的能力
Transformer预测模型及其Python和MATLAB实现
通过将输入的查询、键和值线性变换为多个不同的头部,然后并行计算每个头的注意力,最后将所有头的结果拼接后经过线性变换。- **查询(Query)、键(Key)和值(Value)**:对输入的词嵌入进行线性变换,得到查询、键和值。- **解码器**:解码器结构类似于编码器,但在每个层中加入了对先前生成的
探索LLaMA模型:架构创新与Transformer模型的进化之路
LLaMA模型代表了一种先进的人工智能技术,能够在自然语言处理(NLP)任务上表现出卓越的能力,如文本生成、问答、对话交互、机器翻译以及其他基于语言的理解和生成任务。LLaMA模型家族的特点在于包含了不同参数规模的多个模型版本,参数量从70亿(7B)至650亿(65B)不等。这些模型设计时借鉴了Ch
Datawhale AI夏令营- 讯飞机器翻译挑战赛: 基于transformer框架实现
本文章基于使用了transformer模型去实现了一个英译中的模型,并参加了讯飞科大的NLP翻译比赛。
大语言模型系列-Transformer
Transformer模型的核心思想是利用自注意力机制来捕捉输入序列中的长距离依赖关系,从而有效地处理序列数据。它摒弃了传统的循环神经网络(RNN)和卷积神经网络(CNN)结构,通过编码器-解码器架构实现了并行化计算,大大提高了训练效率。
与传统RNN相比,AI模型当红大神Transformer有什么新魔法呢?
在处理“我决定明年再回去”这一小部分时,自注意力机制允许模型直接关联到“去年我去了西湖”中的“西湖”,从而建立了一个直接的联系。这是因为在计算注意力分数时,每个单词的表示(查询)会与所有其他单词的表示(键)进行比较,从而直接捕捉到它们之间的相关性,无论它们在文本中的距离如何。然而,由于RNN在处理序
颠覆性突破 | 斯坦福推出“TTT新架构”,超越Transformer与Mamba,让模型{学会学习}!
解码器也是由多个相同的层堆叠而成,与编码器类似,但还包括额外的自注意力机制层,用于对编码器的输出进行进一步的上下文感知。如上图所示,在左边,我们观察到Mamba,当今最受欢迎的RNN之一,它的规模与强大的Transformer相似,显示出自2020年LSTM以来的巨大进步。然而,在右边,我们观察到。

注意力机制中三种掩码技术详解和Pytorch实现
在这篇文章中,我们将探索在注意力机制中使用的各种类型的掩码,并在PyTorch中实现它们。
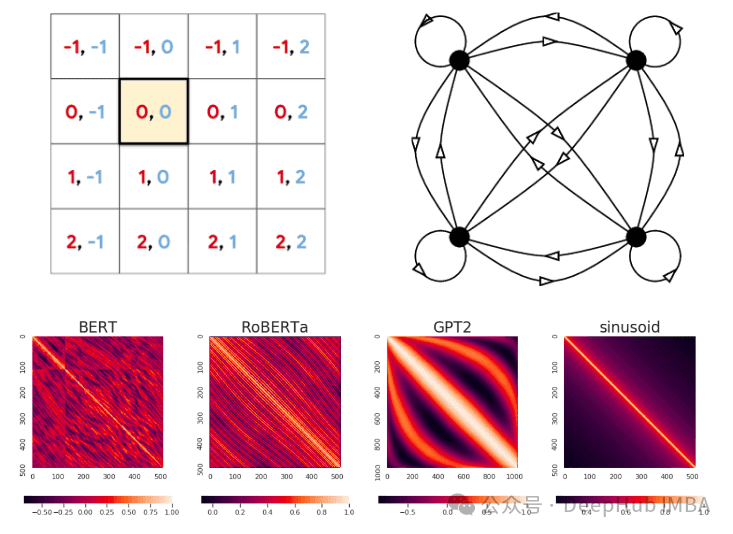
Transformer中高级位置编码的介绍和比较:Linear Rope、NTK、YaRN、CoPE
绝对和相对位置编码是最常见的两种位置编码方式,但是本文将要比较更高级的位置编码方法: 1、RoPE 位置编码及其变体 2、CoPE

Transformer 能代替图神经网络吗?
今天介绍的这篇论文叫“Understanding Transformer Reasoning Capabilities via Graph Algorithms”
Salesforce AI研究: 从奖励建模到在线RLHF工作流
该研究对RLHF的基础理论、偏好模型的构建以及迭代策略优化等内容进行了深入的讲解,展示了扎实的理论基础和实践经验。

Pixel Transformer:用像素代替补丁可以提升图像分类精度
本文将讨论Pixel Transformer的复杂性,创新方法,以及它对人工智能和计算机视觉未来的重要影响。
Transformer模型:人工智能技术发展的里程碑
Google在人工智能领域的贡献是不可小觑的,尤其是在Transformer模型的研究和发展中。Transformer模型最初由Vaswani等人在2017年的论文《Attention is All You Need》中提出。这一模型的核心思想是利用“自注意力(Self-Attention)”机制来
【机器学习】QLoRA:基于PEFT亲手微调你的第一个AI大模型
本文首先对量化和微调的原理进行剖析,接着以Qwen2-7B为例,基于QLoRA、PEFT一步一步带着大家微调自己的大模型,本文参考全网peft+qlora微调教程,一步一排坑,让大家在网络环境不允许的情况下,也能丝滑的开启大模型微调之旅。
关于开源大模型必须知道的 10 件事
本文将向你介绍使用开源大语言模型需要了解的 10 个关键点。阅读完本文后,你将能够在庞大的 AI 世界中找到方向,了解你需要做什么,以及完成这些任务所需的工具。
Tiny Time Mixers (TTM)轻量级时间序列基础模型:无需注意力机制,并且在零样本预测方面表现出色
TTM是一个轻量级的,基于mlp的基础TS模型(≤1M参数),在零样本预测方面表现出色,甚至优于较大的SOTA模型。



