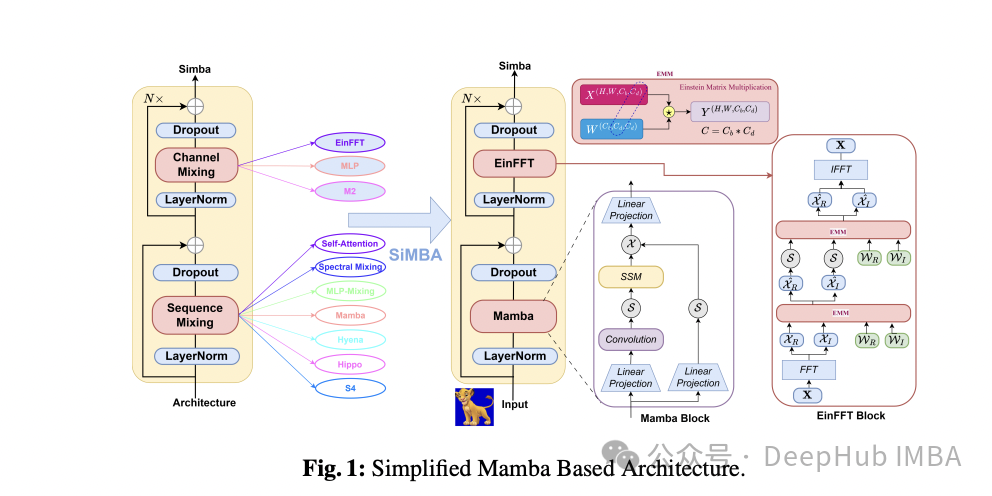
SiMBA:基于Mamba的跨图像和多元时间序列的预测模型
这是3月26日新发的的论文,微软的研究人员简化的基于mamba的体系结构,并且将其同时应用在图像和时间序列中并且取得了良好的成绩。
ICLR 2024 | Meta AI提出ViT寄存器结构,巧妙消除大型ViT中的伪影以提高性能
在这项工作中,作者对 DINOv2 模型特征图中的伪影进行了详尽的研究,并发现这种现象存在于多个现有的流行ViT模型中。作者提供了一种简单的检测伪影的方法,即通过测量token的特征范数来实现。通过研究这些token的局部位置和全局特征信息,作者发现,这些token对于模型性能损失存在一定的影响,并
【Transformer系列(1)】encoder(编码器)和decoder(解码器)
一文带你学会encoder-decoder框架

如何开始定制你自己的大型语言模型
2023年的大型语言模型领域经历了许多快速的发展和创新,发展出了更大的模型规模并且获得了更好的性能,那么我们普通用户是否可以定制我们需要的大型语言模型呢?
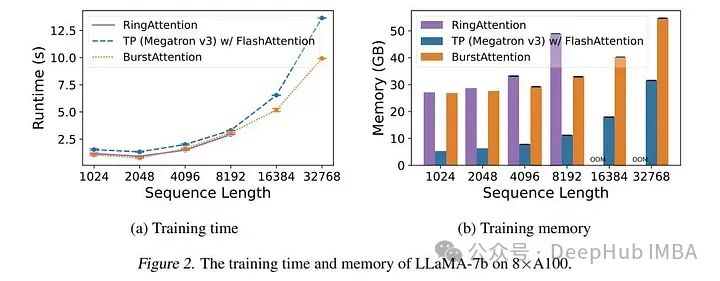
BurstAttention:可对非常长的序列进行高效的分布式注意力计算
而最新的研究BurstAttention可以将2者结合,作为RingAttention和FlashAttention之间的桥梁。
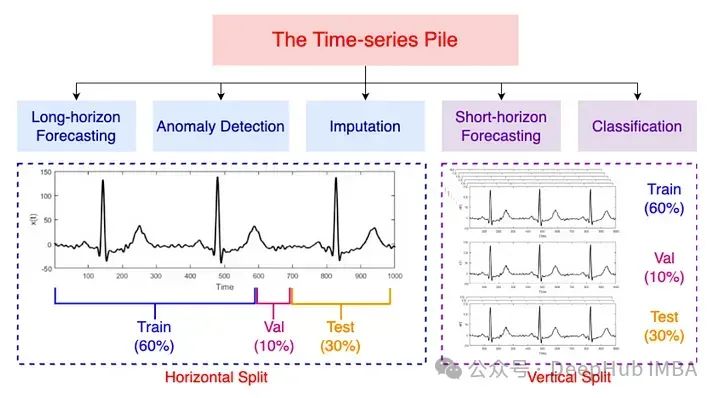
Moment:又一个开源的时间序列基础模型
根据作者的介绍,MOMENT则是第一个开源,大型预训练时间序列模型家族。
【论文笔记】Mamba:挑战Transformer地位的新架构
Mamba的论文笔记
AI论文速读 | TimeXer:让 Transformer能够利用外部变量进行时间序列预测
最近的研究已经展现了时间序列预测显着的性能。然而,由于现实世界应用的部分观察性质,仅仅关注感兴趣的目标,即所谓的内部变量(endogenous variables),通常不足以保证准确的预测。值得注意的是,一个系统通常被记录为多个变量,其中外部序列可以为内部变量提供有价值的外部信息。因此,与之前成熟
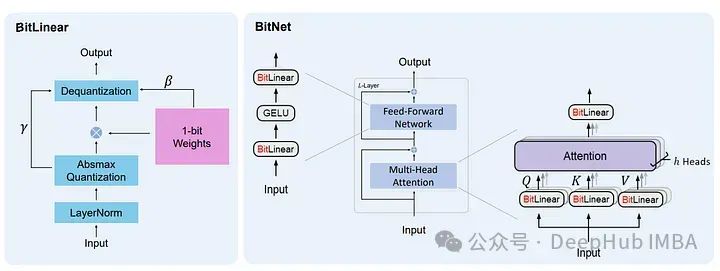
从16-bit 到 1.58-bit :大模型内存效率和准确性之间的最佳权衡
在本文中,我们将通过使用GPTQ对Mistral 7B、Llama 27b和Llama 13B进行8位、4位、3位和2位量化实验,还要介绍一个大模型的最新研究1.58 Bits,它只用 -1,0,1来保存权重
Nomic Embed:能够复现的SOTA开源嵌入模型
Nomic-embed-text是2月份刚发布的,并且是一个完全开源的英文文本嵌入模型,上下文长度为8192.该模型有137M个参数在现在可以算是非常小的模型了。
【人工智能学习】第十四课:理解自注意力机制和Transformer模型
自注意力机制(Self-Attention)是一种允许输入序列中的每个位置都与其他所有位置交互以计算表示的机制。它是Transformer架构的核心,被广泛应用于自然语言处理(NLP)和计算机视觉(CV)等领域。自注意力机制和Transformer架构为处理复杂的序列数据问题开辟了新的可能性。通过深
ChatGPT预训练的奥秘:大规模数据、Transformer架构与自回归学习【文末送书-31】
ChatGPT预训练的奥秘:大规模数据、Transformer架构与自回归学习【文末送书-31】近年来,人工智能领域取得了巨大的进展,其中自然语言处理(NLP)是备受瞩目的一部分。ChatGPT,作为GPT-3.5架构的代表之一,突显了大模型在处理自然语言任务方面的卓越能力。本文将深入探讨ChatG
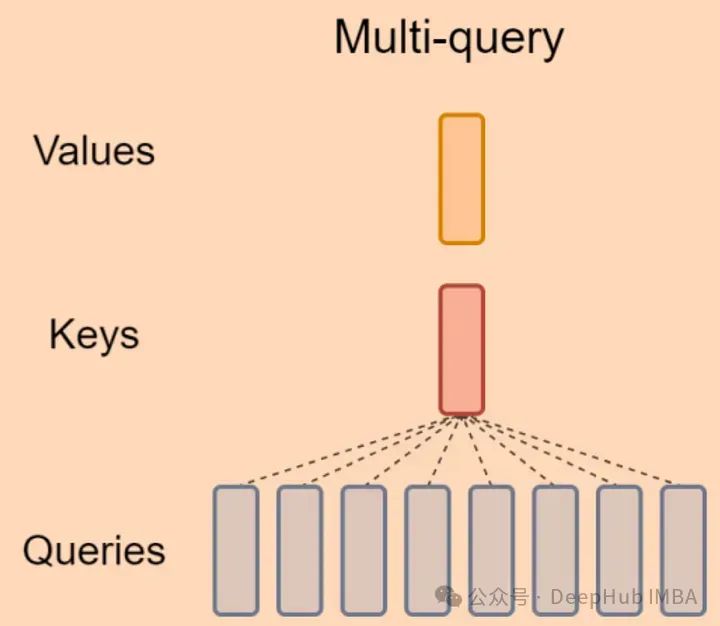
LLM 加速技巧:Muti Query Attention
MQA 是 19 年提出的一种新的 Attention 机制,其能够在保证模型效果的同时加快 decoder 生成 token 的速度。在大语言模型时代被广泛使用,很多LLM都采用了MQA,如Falcon、PaLM、StarCoder等。
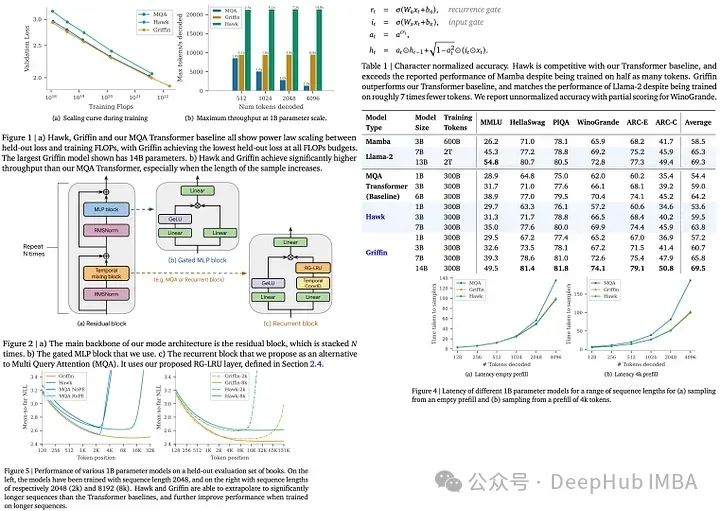
RNN又行了!DeepMind新发布的Griffin可以与同级别的LLM性能相当
Hawk和Griffin是DeepMind推出的新型循环神经网络(RNNs),2月刚刚发布在arxiv上。
一文回顾生成式AI的发展:GANs、GPT、自编码器、扩散模型和Transformer系列
回顾生成式AI的发展:GANs、GPT、自编码器、扩散模型和Transformer系列,涵盖了从文本生成和音乐创作,图像创建,视频制作,代码生成,甚至科学工作等各种任务。
【计算机视觉】Vision Transformer (ViT)详细解析
【计算机视觉】Vision Transformer (ViT)详细解析
Mamba详细介绍和RNN、Transformer的架构可视化对比
看完这篇文章,我希望你能对Mamba 和状态空间模型有一定的了解,最后我们以作者的发现为结尾:作者发现模型与相同尺寸的Transformer模型的性能相当,有时甚至超过了它们!作者:Maarten Grootendorst。
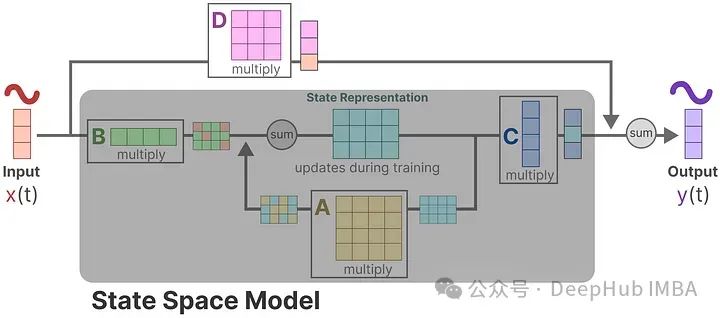
Mamba详细介绍和RNN、Transformer的架构可视化对比
在本篇文章中,通过将绘制RNN,transformer,和Mamba的架构图,并进行详细的对比,这样我们可以更详细的了解它们之间的区别。
(2022|CVPR,非自回归,掩蔽图像生成,迭代译码)MaskGIT:掩蔽生成式图像 Transformer
本文提出 MaskGIT,使用双向 Transformer 解码器进行图像生成。在训练期间,MaskGIT 通过关注所有方向上的标记来学习预测随机掩蔽的标记。在推理时,模型首先同时生成图像的所有标记,然后在先前生成的基础上迭代地细化图像。
【Transformer系列(3)】 《Attention Is All You Need》论文超详细解读(翻译+精读)
transformer开山之作《Attention Is All You Need》论文超详细解读(翻译+精读)



