
专栏:神经网络复现目录
注意力机制
注意力机制(Attention Mechanism)是一种人工智能技术,它可以让神经网络在处理序列数据时,专注于关键信息的部分,同时忽略不重要的部分。在自然语言处理、计算机视觉、语音识别等领域,注意力机制已经得到了广泛的应用。
注意力机制的主要思想是,在对序列数据进行处理时,通过给不同位置的输入信号分配不同的权重,使得模型更加关注重要的输入。例如,在处理一句话时,注意力机制可以根据每个单词的重要性来调整模型对每个单词的注意力。这种技术可以提高模型的性能,尤其是在处理长序列数据时。
在深度学习模型中,注意力机制通常是通过添加额外的网络层实现的,这些层可以学习到如何计算权重,并将这些权重应用于输入信号。常见的注意力机制包括自注意力机制(self-attention)、多头注意力机制(multi-head attention)等。
总之,注意力机制是一种非常有用的技术,它可以帮助神经网络更好地处理序列数据,提高模型的性能。
文章目录
自注意力
自注意力(Self-Attention)是一种深度学习中的注意力机制,最早在“Attention is All You Need”这篇论文中被提出,用于解决自然语言处理中的序列到序列的问题,例如机器翻译。
自注意力机制允许模型自动学习文本序列中不同位置之间的依赖关系,以便更好地理解序列中不同部分之间的关系。在自注意力中,输入序列中的每个元素都被表示为一个向量,这些向量可以被看作是查询(Query)、键(Key)和值(Value)的集合。
在自注意力中,每个查询都会与所有的键进行点积操作,以获取一个注意力权重,这个注意力权重表示了查询与每个键的相关性。然后,将这些注意力权重与值进行加权平均,得到一个加权后的向量表示,这个向量表示就是自注意力的输出。
自注意力机制的优点是可以处理长序列输入,因为它不需要像循环神经网络一样保留所有的历史信息。自注意力还可以学习到更复杂的关系,例如长程依赖关系,这对于一些任务来说非常重要,比如文本生成和语音识别。
下面是自注意力机制的公式:
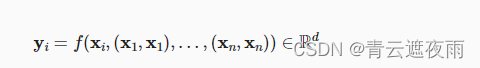
假设输入序列为
X
=
[
x
1
,
x
2
,
.
.
.
,
x
n
]
X=[x_1, x_2, ..., x_n]
X=[x1,x2,...,xn],其中
x
i
x_i
xi 表示输入序列中的第
i
i
i 个元素。每个输入向量
x
i
x_i
xi 可以被表示为一个
d
d
d 维向量。
首先,将每个输入向量
x
i
x_i
xi 映射到三个向量
q
i
,
k
i
,
v
i
q_i, k_i, v_i
qi,ki,vi,它们的维度均为
d
d
d。具体来说,对于每个
i
i
i,有:
q
i
=
W
q
x
i
q_i = W_q x_i
qi=Wqxi
k
i
=
W
k
x
i
k_i = W_k x_i
ki=Wkxi
v
i
=
W
v
x
i
v_i = W_v x_i
vi=Wvxi
其中
W
q
,
W
k
,
W
v
W_q, W_k, W_v
Wq,Wk,Wv 分别是三个可学习的权重矩阵。
然后,计算每个查询向量
q
i
q_i
qi 与所有键向量
k
j
k_j
kj 的点积,再经过一个 softmax 函数归一化得到注意力权重
α
i
,
j
\alpha_{i,j}
αi,j:
α
i
,
j
=
softmax
(
q
i
T
k
j
/
d
)
\alpha_{i,j}=\text{softmax}(q_i^T k_j/\sqrt{d})
αi,j=softmax(qiTkj/d)
其中
d
\sqrt{d}
d 是为了缓解点积操作可能带来的数值过大的问题。
最后,用注意力权重
α
i
,
j
\alpha_{i,j}
αi,j 对所有值向量
v
j
v_j
vj 进行加权求和,得到每个查询向量
q
i
q_i
qi 对应的输出向量
o
i
o_i
oi:
o
i
=
∑
j
=
1
n
α
i
,
j
v
j
o_i = \sum_{j=1}^{n} \alpha_{i,j} v_j
oi=∑j=1nαi,jvj
自注意力的输出就是所有查询向量
q
i
q_i
qi 对应的输出向量
o
i
o_i
oi 的集合,可以表示为一个矩阵
O
=
[
o
1
,
o
2
,
.
.
.
,
o
n
]
O=[o_1, o_2, ..., o_n]
O=[o1,o2,...,on]。
import torch
import torch.nn as nn
classSelfAttention(nn.Module):def__init__(self, input_dim, num_heads):super(SelfAttention, self).__init__()
self.num_heads = num_heads
self.q_linear = nn.Linear(input_dim, input_dim)
self.k_linear = nn.Linear(input_dim, input_dim)
self.v_linear = nn.Linear(input_dim, input_dim)
self.output_linear = nn.Linear(input_dim, input_dim)defforward(self, x):# x shape: batch_size x seq_len x input_dim
batch_size, seq_len, input_dim = x.size()# Project the input vectors to queries, keys, and values
queries = self.q_linear(x).view(batch_size, seq_len, self.num_heads, input_dim // self.num_heads).transpose(1,2)
keys = self.k_linear(x).view(batch_size, seq_len, self.num_heads, input_dim // self.num_heads).transpose(1,2)
values = self.v_linear(x).view(batch_size, seq_len, self.num_heads, input_dim // self.num_heads).transpose(1,2)# Compute the dot product of queries and keys
dot_product = torch.matmul(queries, keys.transpose(-2,-1))/(input_dim // self.num_heads)**0.5# Apply the softmax function to obtain attention weights
attention_weights = torch.softmax(dot_product, dim=-1)# Compute the weighted sum of values
weighted_sum = torch.matmul(attention_weights, values)# Reshape the output and apply a linear transformation
weighted_sum = weighted_sum.transpose(1,2).contiguous().view(batch_size, seq_len, input_dim)
output = self.output_linear(weighted_sum)return output
首先,我们定义了一个名为 SelfAttention 的 PyTorch 模型,该模型包括四个线性层:q_linear、k_linear、v_linear 和 output_linear。这四个线性层分别将输入向量
x
x
x 映射到
q
q
q、
k
k
k、
v
v
v 向量和输出向量。
在 forward 方法中,我们首先将输入向量
x
x
x 的形状解释为 (batch_size, seq_len, input_dim),其中 batch_size 表示批量大小,seq_len 表示序列长度,input_dim 表示输入向量的维度。
然后,我们将输入向量
x
x
x 分别传递到 q_linear、k_linear 和 v_linear 线性层中,并将它们的形状转换为 (batch_size, seq_len, num_heads, input_dim // num_heads)。这里,num_heads 表示要使用的注意力头数,我们将输入向量
x
x
x 在
d
d
d 维度上划分为 num_heads 个子向量,并为每个子向量计算一个注意力权重。这样,每个子向量的维度就变成了 input_dim // num_heads。
接着,我们将 queries、keys 和 values 转换形状之后,我们需要将 queries、keys 和 values 在 num_heads 维度上进行转置,这样可以方便我们将它们的形状变成 (batch_size * num_heads, seq_len, input_dim // num_heads),便于后续计算。
接下来,我们计算 queries 和 keys 的点积,并将结果除以
d
model
\sqrt{d_\text{model}}
dmodel。这里,
d
model
d_\text{model}
dmodel 表示输入向量
x
x
x 的维度,即 input_dim。我们除以
d
model
\sqrt{d_\text{model}}
dmodel 是为了避免点积过大或过小的问题。
然后,我们将点积结果 dot_product 进行 softmax 操作,得到注意力权重 attention_weights。这里,我们对最后一个维度进行 softmax,即对每个子向量计算一个注意力权重。
接下来,我们将注意力权重 attention_weights 和 values 进行加权求和,得到加权向量 weighted_sum。
最后,我们将加权向量 weighted_sum 的形状变回 (batch_size, seq_len, input_dim),然后将其传递到 output_linear 线性层中进行变换,得到最终的输出向量 output。
总的来说,这段代码实现了一个带有多头自注意力机制的自注意力层,该层将输入向量
x
x
x 映射到输出向量
y
y
y,并对输入向量
x
x
x 中的每个子向量计算一个注意力权重,以便对不同的子向量进行不同的加权。这样,我们可以更好地理解输入向量中的不同信息,并将不同的信息分配给不同的子向量。同时,多头自注意力机制可以提高模型的表示能力,并使模型更容易捕捉长距离依赖关系。
位置编码
为什么使用位置编码
在transformer模型中,输入的是一排排的句子,对于人类来说可以很容易的看出句子中每个单词的顺序,即位置信息,例如:
(1)绝对位置信息。a1是第一个token,a2是第二个token…
(2)相对位置信息。a2在a1的后面一位,a4在a2的后面两位…
(3)不同位置间的距离。a1和a3差两个位置,a1和a4差三个位置…
但是这对于机器来说却是一件很困难的事情,transformer中的self-attention能够学习到句子中每个单词之间的相关性,关注其中重要的信息,但是却无法学习到每个单词的位置信息,所以说我们需要在模型中另外添加token的位置信息。
Transformer模型抛弃了RNN、CNN作为序列学习的基本模型。我们知道,循环神经网络本身就是一种顺序结构,天生就包含了词在序列中的位置信息。当抛弃循环神经网络结构,完全采用Attention取而代之,这些词序信息就会丢失,模型就没有办法知道每个词在句子中的相对和绝对的位置信息。因此,有必要把词序信号加到词向量上帮助模型学习这些信息,位置编码(Positional Encoding)就是用来解决这种问题的方法。
位置编码(Positional Encoding)是一种用词的位置信息对序列中的每个词进行二次表示的方法,让输入数据携带位置信息,是模型能够找出位置特点。正如前文所述,Transformer模型本身不具备像RNN那样的学习词序信息的能力,需要主动将词序信息喂给模型。那么,模型原先的输入是不含词序信息的词向量,位置编码需要将词序信息和词向量结合起来形成一种新的表示输入给模型,这样模型就具备了学习词序信息的能力。
位置编码的计算
假设输入表示
X
∈
R
n
×
d
X\in R^{n \times d}
X∈Rn×d包含一个序列中n个词元的d维嵌入表示。位置编码使用相同形状的位置嵌入矩阵
P
∈
R
n
×
d
P\in R^{n\times d}
P∈Rn×d输出
X
+
P
X+P
X+P,矩阵第
i
i
i行表示一个词元的位置编码:
Pos
(
i
,
2
j
)
=
sin
(
i
1000
0
2
j
/
d
model
)
,
Pos
(
i
,
2
j
+
1
)
=
cos
(
i
1000
0
2
j
/
d
model
)
,
\begin{aligned} \text{Pos}(i, 2j) &= \sin\left(\frac{i}{10000^{2j/d_{\text{model}}}}\right), \\ \text{Pos}(i, 2j+1) &= \cos\left(\frac{i}{10000^{2j/d_{\text{model}}}}\right), \end{aligned}
Pos(i,2j)Pos(i,2j+1)=sin(100002j/dmodeli),=cos(100002j/dmodeli),
位置编码的实现
#@saveclassPositionalEncoding(nn.Block):"""位置编码"""def__init__(self, num_hiddens, dropout, max_len=1000):super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(dropout)# 创建一个足够长的P
self.P = np.zeros((1, max_len, num_hiddens))
X = np.arange(max_len).reshape(-1,1)/ np.power(10000, np.arange(0, num_hiddens,2)/ num_hiddens)
self.P[:,:,0::2]= np.sin(X)
self.P[:,:,1::2]= np.cos(X)defforward(self, X):
X = X + self.P[:,:X.shape[1],:].as_in_ctx(X.ctx)return self.dropout(X)
绝对位置编码
你可能想知道,正余弦组合怎么能代表一个位置/顺序?
其实很简单,假设你想用二进制格式表示一个数字: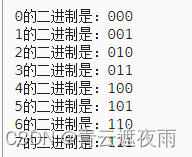
第
i
位置上
2
i
个数据交替一次。
第i位置上2^i 个数据交替一次。
第i位置上2i个数据交替一次。
下图使用正弦函数编码,句子长度为50(纵坐标),编码向量维数128(横坐标)。可以看到交替频率从左到右逐渐减慢。从下图可以看出,每一行是一个词元的位置编码,我们可以明显看出,第一个单词和最后一个单词的位置信息完全不同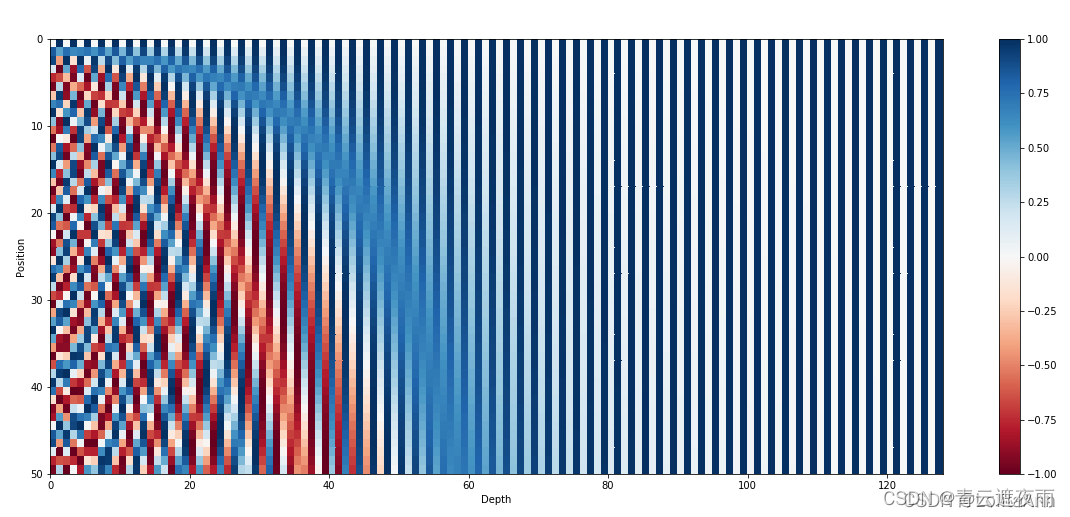
相对位置信息
除了捕获绝对位置信息之外,上述的位置编码还允许模型学习得到输入序列中相对位置信息。 这是因为对于任何确定的位置偏移
a
a
a,位置
i
+
a
i+a
i+a处的位置编码可以线性投影位置
i
i
i处的位置编码来表示。
这种投影的数学解释是,令
w
i
=
1
/
1000
0
2
j
/
d
w_i=1/10000^{2j/d}
wi=1/100002j/d, 对于任何确定的位置偏移
a
a
a,中的任何一对
(
p
i
,
2
j
,
p
i
,
2
j
+
1
)
(p_{i,2j},p_{i,2j+1})
(pi,2j,pi,2j+1)都可以线性投影到
(
p
i
+
a
,
2
j
,
p
i
+
a
,
2
j
+
1
)
(p_{i+a,2j},p_{i+a,2j+1})
(pi+a,2j,pi+a,2j+1) :
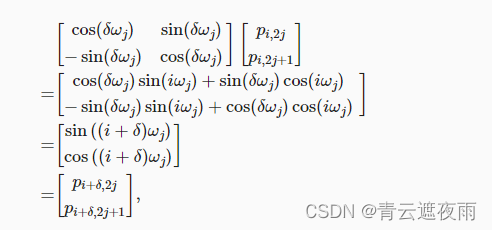
Tansformer架构
模型
Transformer 是一种基于自注意力机制的神经网络模型,用于处理序列到序列(Sequence-to-Sequence)的任务,如机器翻译、文本摘要等。它由 Google 提出,被认为是目前在自然语言处理领域中最先进的模型之一。
Transformer 模型中最重要的组成部分是自注意力机制,它能够捕捉输入序列中不同位置之间的关系,从而在处理长序列时提高模型的性能。另外,Transformer 还采用了残差连接和层归一化等技术,使得模型训练更加稳定和高效。
Transformer 模型主要包含以下几个部分:
输入嵌入层:将输入序列中的单词映射到一个连续的向量空间中,从而方便后续的处理。
位置编码层:为了考虑序列中不同位置之间的相对位置信息,需要对输入序列中的每个位置进行编码,得到一个位置编码向量。
自注意力层:对输入序列中的每个位置进行自注意力计算,从而捕捉不同位置之间的依赖关系。
前馈网络层:对每个位置的自注意力输出向量进行一个简单的前馈网络处理,从而增强模型的非线性能力。
输出层:将最后一层的输出向量进行线性变换,并使用 softmax 函数得到每个输出单词的概率分布。
在训练过程中,Transformer 模型使用了注意力机制和掩码机制来避免对未来信息的泄漏,并且采用了交叉熵损失函数来评估模型的性能。在推断过程中,Transformer 模型使用了束搜索(Beam Search)算法来生成最优的输出序列。
总之,Transformer 模型在序列到序列任务中表现出色,具有良好的可扩展性和适用性,成为了自然语言处理领域的重要研究方向之一。
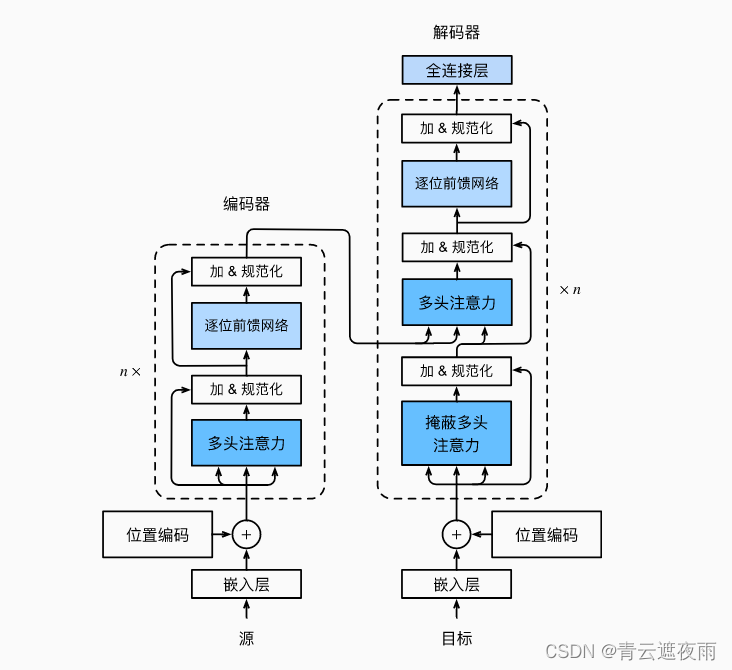
图中概述了Transformer的架构。从宏观角度来看,Transformer的编码器是由多个相同的层叠加而成的,每个层都有两个子层(子层表示为
s
u
b
l
a
y
e
r
sublayer
sublayer)。第一个子层是多头自注意力(multi-head self-attention)汇聚;第二个子层是基于位置的前馈网络(positionwise feed-forward network)。具体来说,在计算编码器的自注意力时,查询、键和值都来自前一个编码器层的输出。每个子层都采用了残差连接(residual connection)。
Transformer解码器也是由多个相同的层叠加而成的,并且层中使用了残差连接和层规范化。除了编码器中描述的两个子层之外,解码器还在这两个子层之间插入了第三个子层,称为编码器-解码器注意力(encoder-decoder attention)层。在编码器-解码器注意力中,查询来自前一个解码器层的输出,而键和值来自整个编码器的输出。在解码器自注意力中,查询、键和值都来自上一个解码器层的输出。但是,解码器中的每个位置只能考虑该位置之前的所有位置。这种掩蔽(masked)注意力保留了自回归(auto-regressive)属性,确保预测仅依赖于已生成的输出词元。
基于位置的前馈网络
首先我们实现下图部分: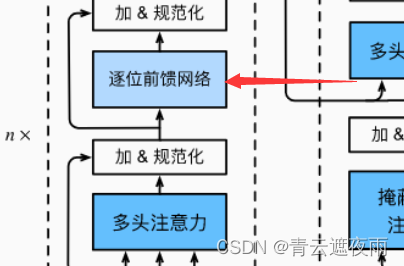
基于位置的前馈网络对序列中的所有位置的表示进行变换时使用的是同一个多层感知机(MLP),这就是称前馈网络是基于位置的(positionwise)的原因。在下面的实现中,输入X的形状(批量大小,时间步数或序列长度,隐单元数或特征维度)将被一个两层的感知机转换成形状为(批量大小,时间步数,ffn_num_outputs)的输出张量,即改变的是最后一个维度。
#@saveclassPositionWiseFFN(nn.Module):"""基于位置的前馈网络"""def__init__(self, ffn_num_input, ffn_num_hiddens, ffn_num_outputs,**kwargs):super(PositionWiseFFN, self).__init__(**kwargs)
self.dense1 = nn.Linear(ffn_num_input, ffn_num_hiddens)
self.relu = nn.ReLU()
self.dense2 = nn.Linear(ffn_num_hiddens, ffn_num_outputs)defforward(self, X):return self.dense2(self.relu(self.dense1(X)))
下面的例子显示,改变张量的最里层维度的尺寸,会改变成基于位置的前馈网络的输出尺寸。因为用同一个多层感知机对所有位置上的输入进行变换,所以当所有这些位置的输入相同时,它们的输出也是相同的。
ffn = PositionWiseFFN(4,4,8)
ffn.eval()
ffn(torch.ones((2,3,4)))[0]

残差连接和层规范化
现在让我们关注图中的加法和规范化(add&norm)组件。正如在本节开头所述,这是由残差连接和紧随其后的层规范化组成的。两者都是构建有效的深度架构的关键。
层规范化(Layer Normalization)是一种神经网络中常用的归一化方法,其目的是提高神经网络的训练效率和性能。与批量归一化(Batch Normalization)不同,层规范化是对单个样本进行归一化,而不是对一批样本进行归一化。
具体来说,对于一个具有
d
d
d个特征的输入
x
=
(
x
1
,
x
2
,
.
.
.
,
x
d
)
x=(x_1,x_2,...,x_d)
x=(x1,x2,...,xd),层规范化对每个特征进行归一化处理,使得每个特征的均值为0,标准差为1,即:
x
^
i
=
x
i
−
μ
σ
2
+
ϵ
\hat{x}_i = \frac{x_i - \mu}{\sqrt{\sigma^2+\epsilon}}
x^i=σ2+ϵxi−μ
其中,
μ
\mu
μ是
x
i
x_i
xi的均值,
σ
2
\sigma^2
σ2是
x
i
x_i
xi的方差,
ϵ
\epsilon
ϵ是一个很小的常数(通常取
1
0
−
5
10^{-5}
10−5),用于避免除以0的情况。然后,层规范化会将每个特征进行缩放和平移:
y
i
=
γ
x
^
i
+
β
y_i = \gamma \hat{x}_i + \beta
yi=γx^i+β
其中,
γ
\gamma
γ和
β
\beta
β是可学习的参数,用于缩放和平移每个特征。这样,层规范化可以让每个特征都有相同的缩放和平移,从而提高模型的泛化性能。
尽管批量规范化在计算机视觉中被广泛应用,但在自然语言处理任务中(输入通常是变长序列)批量规范化通常不如层规范化的效果好。
以下代码对比不同维度的层规范化和批量规范化的效果。
ln = nn.LayerNorm(2)
bn = nn.BatchNorm1d(2)
X = torch.tensor([[1,2],[2,3]], dtype=torch.float32)# 在训练模式下计算X的均值和方差print('layer norm:', ln(X),'\nbatch norm:', bn(X))

现在可以使用残差连接和层规范化来实现AddNorm类。暂退法也被作为正则化方法使用。即实现下图部分: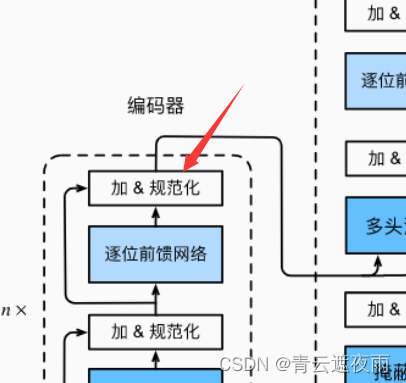
#@saveclassAddNorm(nn.Module):"""残差连接后进行层规范化"""def__init__(self, normalized_shape, dropout,**kwargs):super(AddNorm, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
self.ln = nn.LayerNorm(normalized_shape)defforward(self, X, Y):return self.ln(self.dropout(Y)+ X)
多头注意力
实现如下部分: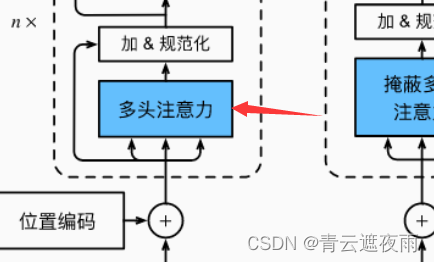
此部分代码已经解释过了,详情见:https://blog.csdn.net/qq_51957239/article/details/129732592?spm=1001.2014.3001.5502
deftranspose_qkv(X, num_heads):"""Transposition for parallel computation of multiple attention heads.
Defined in :numref:`sec_multihead-attention`"""# Shape of input `X`:# (`batch_size`, no. of queries or key-value pairs, `num_hiddens`).# Shape of output `X`:# (`batch_size`, no. of queries or key-value pairs, `num_heads`,# `num_hiddens` / `num_heads`)
X = X.reshape(X.shape[0], X.shape[1], num_heads,-1)# Shape of output `X`:# (`batch_size`, `num_heads`, no. of queries or key-value pairs,# `num_hiddens` / `num_heads`)
X = X.permute(0,2,1,3)# Shape of `output`:# (`batch_size` * `num_heads`, no. of queries or key-value pairs,# `num_hiddens` / `num_heads`)return X.reshape(-1, X.shape[2], X.shape[3])deftranspose_output(X, num_heads):"""Reverse the operation of `transpose_qkv`.
Defined in :numref:`sec_multihead-attention`"""
X = X.reshape(-1, num_heads, X.shape[1], X.shape[2])
X = X.permute(0,2,1,3)return X.reshape(X.shape[0], X.shape[1],-1)
classMultiHeadAttention(nn.Module):"""Multi-head attention.
Defined in :numref:`sec_multihead-attention`"""def__init__(self, key_size, query_size, value_size, num_hiddens,
num_heads, dropout, bias=False,**kwargs):super(MultiHeadAttention, self).__init__(**kwargs)
self.num_heads = num_heads
self.attention = d2l.DotProductAttention(dropout)
self.W_q = nn.Linear(query_size, num_hiddens, bias=bias)
self.W_k = nn.Linear(key_size, num_hiddens, bias=bias)
self.W_v = nn.Linear(value_size, num_hiddens, bias=bias)
self.W_o = nn.Linear(num_hiddens, num_hiddens, bias=bias)defforward(self, queries, keys, values, valid_lens):# Shape of `queries`, `keys`, or `values`:# (`batch_size`, no. of queries or key-value pairs, `num_hiddens`)# Shape of `valid_lens`:# (`batch_size`,) or (`batch_size`, no. of queries)# After transposing, shape of output `queries`, `keys`, or `values`:# (`batch_size` * `num_heads`, no. of queries or key-value pairs,# `num_hiddens` / `num_heads`)
queries = transpose_qkv(self.W_q(queries), self.num_heads)
keys = transpose_qkv(self.W_k(keys), self.num_heads)
values = transpose_qkv(self.W_v(values), self.num_heads)if valid_lens isnotNone:# On axis 0, copy the first item (scalar or vector) for# `num_heads` times, then copy the next item, and so on
valid_lens = torch.repeat_interleave(
valid_lens, repeats=self.num_heads, dim=0)# Shape of `output`: (`batch_size` * `num_heads`, no. of queries,# `num_hiddens` / `num_heads`)
output = self.attention(queries, keys, values, valid_lens)# Shape of `output_concat`:# (`batch_size`, no. of queries, `num_hiddens`)
output_concat = transpose_output(output, self.num_heads)return self.W_o(output_concat)
编码器
编码器块
实现如下部分: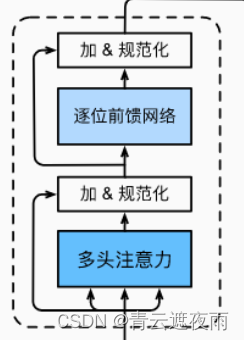
#@saveclassEncoderBlock(nn.Module):"""Transformer编码器块"""def__init__(self, key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
dropout, use_bias=False,**kwargs):super(EncoderBlock, self).__init__(**kwargs)
self.attention = d2l.MultiHeadAttention(
key_size, query_size, value_size, num_hiddens, num_heads, dropout,
use_bias)
self.addnorm1 = AddNorm(norm_shape, dropout)
self.ffn = PositionWiseFFN(
ffn_num_input, ffn_num_hiddens, num_hiddens)
self.addnorm2 = AddNorm(norm_shape, dropout)defforward(self, X, valid_lens):
Y = self.addnorm1(X, self.attention(X, X, X, valid_lens))#自注意力return self.addnorm2(Y, self.ffn(Y))
这段代码定义了一个Transformer编码器块的类EncoderBlock。在__init__函数中,它定义了以下几个子层:
self.attention:一个多头注意力层,使用输入作为查询、键和值。它将输入作为三个参数传递给d2l.MultiHeadAttention,并使用valid_lens(一个1D张量,其中的每个元素表示相应序列的有效长度)来遮蔽无效的填充项。
self.addnorm1:一个层规范化层,用于将输入与多头注意力的输出进行加和。
self.ffn:一个位置逐元素前馈神经网络(Position-wise Feed-Forward Network),用于处理上一层的输出。
self.addnorm2:另一个层规范化层,用于将位置逐元素前馈神经网络的输出与上一层的输出进行加和。
在forward函数中,输入X和有效长度valid_lens传递给多头注意力层进行处理,输出结果通过层规范化层和位置逐元素前馈神经网络层进行加和和处理。最终,该函数返回位置逐元素前馈神经网络层输出的结果。
编码器
实现如下部分: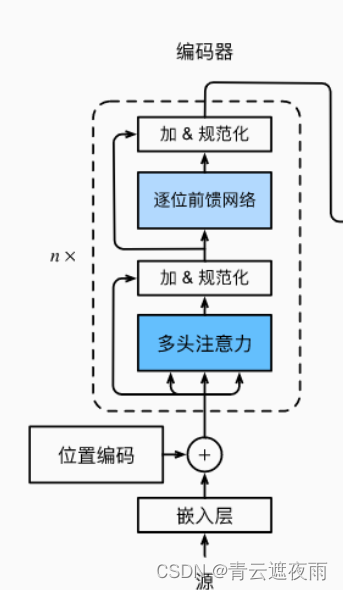
#@saveclassTransformerEncoder(d2l.Encoder):"""Transformer编码器"""def__init__(self, vocab_size, key_size, query_size, value_size,
num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, num_layers, dropout, use_bias=False,**kwargs):super(TransformerEncoder, self).__init__(**kwargs)
self.num_hiddens = num_hiddens
self.embedding = nn.Embedding(vocab_size, num_hiddens)
self.pos_encoding = PositionalEncoding(num_hiddens, dropout)
self.blks = nn.Sequential()for i inrange(num_layers):
self.blks.add_module("block"+str(i),
EncoderBlock(key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, dropout, use_bias))defforward(self, X, valid_lens,*args):# 因为位置编码值在-1和1之间,# 因此嵌入值乘以嵌入维度的平方根进行缩放,# 然后再与位置编码相加。
X = self.pos_encoding(self.embedding(X)* math.sqrt(self.num_hiddens))
self.attention_weights =[None]*len(self.blks)for i, blk inenumerate(self.blks):
X = blk(X, valid_lens)
self.attention_weights[
i]= blk.attention.attention.attention_weights
return X
具体来说,TransformerEncoder类继承了d2l.Encoder类,其中定义了一个词嵌入层和多个EncoderBlock组成的顺序层。每个EncoderBlock由多头注意力层和位置前馈网络两部分组成,用于对输入进行处理。
在forward函数中,输入先经过嵌入层进行词向量编码,然后再乘以嵌入维度的平方根进行缩放,最后再加上位置编码。位置编码通过PositionalEncoding类实现,用于对序列中的每个位置进行编码,帮助模型学习序列中元素的相对位置关系。
接着,输入通过多个EncoderBlock进行处理,每个EncoderBlock的输出作为下一个EncoderBlock的输入。在每个EncoderBlock中,输入先经过多头注意力层进行自注意力计算,得到注意力权重矩阵,然后通过残差连接和层规范化处理后再输入到位置前馈网络中进行处理。最终,该函数返回最后一个EncoderBlock的输出作为整个编码器的输出。
注意,在每个EncoderBlock中,多头注意力层的注意力权重会被记录在self.attention_weights列表中,可以用于可视化和调试。
Transformer编码器输出的形状是(批量大小,时间步数目,num_hiddens)
解码器
解码器块
实现如下部分:
classDecoderBlock(nn.Module):"""解码器中第i个块"""def__init__(self, key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
dropout, i,**kwargs):super(DecoderBlock, self).__init__(**kwargs)
self.i = i
self.attention1 = d2l.MultiHeadAttention(
key_size, query_size, value_size, num_hiddens, num_heads, dropout)
self.addnorm1 = AddNorm(norm_shape, dropout)
self.attention2 = d2l.MultiHeadAttention(
key_size, query_size, value_size, num_hiddens, num_heads, dropout)
self.addnorm2 = AddNorm(norm_shape, dropout)
self.ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens,
num_hiddens)
self.addnorm3 = AddNorm(norm_shape, dropout)defforward(self, X, state):
enc_outputs, enc_valid_lens = state[0], state[1]# 训练阶段,输出序列的所有词元都在同一时间处理,# 因此state[2][self.i]初始化为None。# 预测阶段,输出序列是通过词元一个接着一个解码的,# 因此state[2][self.i]包含着直到当前时间步第i个块解码的输出表示if state[2][self.i]isNone:
key_values = X
else:
key_values = torch.cat((state[2][self.i], X), axis=1)
state[2][self.i]= key_values
if self.training:
batch_size, num_steps, _ = X.shape
# dec_valid_lens的开头:(batch_size,num_steps),# 其中每一行是[1,2,...,num_steps]
dec_valid_lens = torch.arange(1, num_steps +1, device=X.device).repeat(batch_size,1)else:
dec_valid_lens =None# 自注意力
X2 = self.attention1(X, key_values, key_values, dec_valid_lens)
Y = self.addnorm1(X, X2)# 编码器-解码器注意力。# enc_outputs的开头:(batch_size,num_steps,num_hiddens)
Y2 = self.attention2(Y, enc_outputs, enc_outputs, enc_valid_lens)
Z = self.addnorm2(Y, Y2)return self.addnorm3(Z, self.ffn(Z)), state
这是一个解码器中的一个块。解码器中的每个块接收解码器输入(来自编码器的输出或之前块的输出)和当前状态(来自解码器之前的块的输出或来自编码器的输出)作为输入,并输出当前块的输出和更新后的状态。
该块的结构如下:
首先,将当前块的输入与状态中存储的历史输出拼接在一起,形成编码器-解码器关注的键和值。在训练期间,所有输出序列的标记都在同一时间处理,因此状态中的历史输出初始化为None;在推理期间,输出序列是逐个标记解码的,因此状态中的历史输出包含直到当前时间步骤为止的所有历史输出。
接下来,使用多头自注意力对输入进行处理。
将自注意力的输出与输入相加,并进行 Layer Normalization。
使用编码器-解码器注意力对结果进行处理。这是由编码器输出和当前块的自注意力输出构成的“键值对”进行计算的。
将编码器-解码器注意力的输出与自注意力的输出相加,并进行 Layer Normalization。
最后,使用一个前馈神经网络对结果进行处理,并再次执行加和规范化操作。输出和更新后的状态被返回。
解码器
实现如下部分: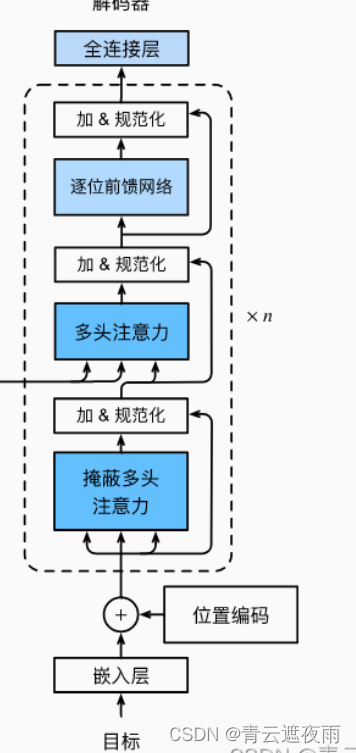
classTransformerDecoder(d2l.AttentionDecoder):def__init__(self, vocab_size, key_size, query_size, value_size,
num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, num_layers, dropout,**kwargs):super(TransformerDecoder, self).__init__(**kwargs)
self.num_hiddens = num_hiddens
self.num_layers = num_layers
self.embedding = nn.Embedding(vocab_size, num_hiddens)
self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout)
self.blks = nn.Sequential()for i inrange(num_layers):
self.blks.add_module("block"+str(i),
DecoderBlock(key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, dropout, i))
self.dense = nn.Linear(num_hiddens, vocab_size)definit_state(self, enc_outputs, enc_valid_lens,*args):return[enc_outputs, enc_valid_lens,[None]* self.num_layers]defforward(self, X, state):
X = self.pos_encoding(self.embedding(X)* math.sqrt(self.num_hiddens))
self._attention_weights =[[None]*len(self.blks)for _ inrange(2)]for i, blk inenumerate(self.blks):
X, state = blk(X, state)# 解码器自注意力权重
self._attention_weights[0][
i]= blk.attention1.attention.attention_weights
# “编码器-解码器”自注意力权重
self._attention_weights[1][
i]= blk.attention2.attention.attention_weights
return self.dense(X), state
@propertydefattention_weights(self):return self._attention_weights
以下是各个部分的具体解释:
构造函数 init()
vocab_size: 词汇表大小,即词汇表中不同单词的数量。
key_size, query_size, value_size: Transformer 模型中的键、查询和值的维度大小。
num_hiddens: 隐藏单元的维度大小。
norm_shape: 归一化层的形状。
ffn_num_input, ffn_num_hiddens: feedforward 层的输入和隐藏层维度大小。
num_heads: 多头注意力机制中的头数。
num_layers: 解码器中的 Transformer 层的数量。
dropout: Dropout 层的概率。
**kwargs: 其他参数。
init_state() 函数:用于初始化解码器状态,返回一个列表,其中第一个元素是编码器输出,第二个元素是编码器有效长度,第三个元素是一个列表,其中包含解码器每一层的状态信息。
forward() 函数:该函数接受输入 X 和 state,并输出解码器输出和解码器状态。其中,X 是解码器输入,state 包含了解码器的状态信息。函数首先将输入 X 经过嵌入层和位置编码层,得到位置嵌入表示 X。然后,对于解码器中的每一层,将 X 和 state 输入到 Transformer 解码器块中进行处理,得到解码器的输出 X 和新的状态信息。在处理过程中,记录了解码器自注意力权重和“编码器-解码器”自注意力权重,分别保存在 _attention_weights 列表的第一个和第二个子列表中。最后,将 X 输入到全连接层中,得到解码器的输出结果。
attention_weights() 函数:该函数返回 _attention_weights 列表。该列表保存了每一层解码器的自注意力权重和“编码器-解码器”自注意力权重。
总体而言,这段代码定义了一个 Transformer 解码器类,并提供了初始化状态、前向传播和获取注意力权重的函数。
实战:机器翻译
数据集
#@save
d2l.DATA_HUB['fra-eng']=(d2l.DATA_URL +'fra-eng.zip','94646ad1522d915e7b0f9296181140edcf86a4f5')#@savedefread_data_nmt():"""载入“英语-法语”数据集"""
data_dir = d2l.download_extract('fra-eng')withopen(os.path.join(data_dir,'fra.txt'),'r',
encoding='utf-8')as f:return f.read()
raw_text = read_data_nmt()print(raw_text[:75])
数据预处理
#@savedefpreprocess_nmt(text):"""预处理“英语-法语”数据集"""defno_space(char, prev_char):return char inset(',.!?')and prev_char !=' '# 使用空格替换不间断空格# 使用小写字母替换大写字母
text = text.replace('\u202f',' ').replace('\xa0',' ').lower()# 在单词和标点符号之间插入空格
out =[' '+ char if i >0and no_space(char, text[i -1])else char
for i, char inenumerate(text)]return''.join(out)
text = preprocess_nmt(raw_text)print(text[:80])
#@savedeftokenize_nmt(text, num_examples=None):"""词元化“英语-法语”数据数据集"""
source, target =[],[]for i, line inenumerate(text.split('\n')):if num_examples and i > num_examples:break
parts = line.split('\t')iflen(parts)==2:
source.append(parts[0].split(' '))
target.append(parts[1].split(' '))return source, target
source, target = tokenize_nmt(text)
source[:]
#@savedefshow_list_len_pair_hist(legend, xlabel, ylabel, xlist, ylist):"""绘制列表长度对的直方图"""
d2l.set_figsize()
_, _, patches = d2l.plt.hist([[len(l)for l in xlist],[len(l)for l in ylist]])
d2l.plt.xlabel(xlabel)
d2l.plt.ylabel(ylabel)for patch in patches[1].patches:
patch.set_hatch('/')
d2l.plt.legend(legend)
show_list_len_pair_hist(['source','target'],'# tokens per sequence','count', source, target);
import collections
classVocab:"""Vocabulary for text."""def__init__(self, tokens=None, min_freq=0, reserved_tokens=None):"""Defined in :numref:`sec_text_preprocessing`"""if tokens isNone:
tokens =[]if reserved_tokens isNone:
reserved_tokens =[]# Sort according to frequencies
counter = count_corpus(tokens)
self._token_freqs =sorted(counter.items(), key=lambda x: x[1],
reverse=True)# The index for the unknown token is 0
self.idx_to_token =['<unk>']+ reserved_tokens
self.token_to_idx ={token: idx
for idx, token inenumerate(self.idx_to_token)}for token, freq in self._token_freqs:if freq < min_freq:breakif token notin self.token_to_idx:
self.idx_to_token.append(token)
self.token_to_idx[token]=len(self.idx_to_token)-1def__len__(self):returnlen(self.idx_to_token)def__getitem__(self, tokens):ifnotisinstance(tokens,(list,tuple)):return self.token_to_idx.get(tokens, self.unk)return[self.__getitem__(token)for token in tokens]defto_tokens(self, indices):ifnotisinstance(indices,(list,tuple)):return self.idx_to_token[indices]return[self.idx_to_token[index]for index in indices]@propertydefunk(self):# Index for the unknown tokenreturn0@propertydeftoken_freqs(self):# Index for the unknown tokenreturn self._token_freqs
defcount_corpus(tokens):"""Count token frequencies.
Defined in :numref:`sec_text_preprocessing`"""# Here `tokens` is a 1D list or 2D listiflen(tokens)==0orisinstance(tokens[0],list):# Flatten a list of token lists into a list of tokens
tokens =[token for line in tokens for token in line]return collections.Counter(tokens)
#@savedeftruncate_pad(line, num_steps, padding_token):"""截断或填充文本序列"""iflen(line)> num_steps:return line[:num_steps]# 截断return line +[padding_token]*(num_steps -len(line))# 填充
truncate_pad(src_vocab[source[0]],10, src_vocab['<pad>'])
#@savedefbuild_array_nmt(lines, vocab, num_steps):"""将机器翻译的文本序列转换成小批量"""
lines =[vocab[l]for l in lines]#token to id
lines =[l +[vocab['<eos>']]for l in lines]# 加上eos代表结束
array = torch.tensor([truncate_pad(
l, num_steps, vocab['<pad>'])for l in lines])# 转换为数组
valid_len =(array != vocab['<pad>']).type(torch.int32).sum(1)#有效长度return array, valid_len
#@savefrom torch.utils import data
defload_array(data_arrays, batch_size, is_train=True):"""Construct a PyTorch data iterator.
Defined in :numref:`sec_linear_concise`"""
dataset = data.TensorDataset(*data_arrays)return data.DataLoader(dataset, batch_size, shuffle=is_train)defload_data_nmt(batch_size, num_steps, num_examples=600):"""返回翻译数据集的迭代器和词表"""
text = preprocess_nmt(read_data_nmt())
source, target = tokenize_nmt(text, num_examples)
src_vocab = Vocab(source, min_freq=2,
reserved_tokens=['<pad>','<bos>','<eos>'])
tgt_vocab = Vocab(target, min_freq=2,
reserved_tokens=['<pad>','<bos>','<eos>'])
src_array, src_valid_len = build_array_nmt(source, src_vocab, num_steps)
tgt_array, tgt_valid_len = build_array_nmt(target, tgt_vocab, num_steps)
data_arrays =(src_array, src_valid_len, tgt_array, tgt_valid_len)
data_iter = load_array(data_arrays, batch_size)return data_iter, src_vocab, tgt_vocab
模型定义
classEncoderDecoder(nn.Module):"""The base class for the encoder-decoder architecture.
Defined in :numref:`sec_encoder-decoder`"""def__init__(self, encoder, decoder,**kwargs):super(EncoderDecoder, self).__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
defforward(self, enc_X, dec_X,*args):
enc_outputs = self.encoder(enc_X,*args)
dec_state = self.decoder.init_state(enc_outputs,*args)return self.decoder(dec_X, dec_state)
encoder = TransformerEncoder(len(src_vocab), key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
num_layers, dropout)
decoder = TransformerDecoder(len(tgt_vocab), key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
num_layers, dropout)
net = EncoderDecoder(encoder, decoder)
超参数设定
num_hiddens, num_layers, dropout, batch_size, num_steps =32,2,0.1,64,10
lr, num_epochs, device =0.005,200, d2l.try_gpu()
ffn_num_input, ffn_num_hiddens, num_heads =32,64,4
key_size, query_size, value_size =32,32,32
norm_shape =[32]
train_iter, src_vocab, tgt_vocab = load_data_nmt(batch_size, num_steps)
训练
deftrain_seq2seq(net, data_iter, lr, num_epochs, tgt_vocab, device):"""Train a model for sequence to sequence.
Defined in :numref:`sec_seq2seq_decoder`"""defxavier_init_weights(m):iftype(m)== nn.Linear:
nn.init.xavier_uniform_(m.weight)iftype(m)== nn.GRU:for param in m._flat_weights_names:if"weight"in param:
nn.init.xavier_uniform_(m._parameters[param])
net.apply(xavier_init_weights)
net.to(device)
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
loss = MaskedSoftmaxCELoss()
net.train()
animator = d2l.Animator(xlabel='epoch', ylabel='loss',
xlim=[10, num_epochs])for epoch inrange(num_epochs):
timer = d2l.Timer()
metric = d2l.Accumulator(2)# Sum of training loss, no. of tokensfor batch in data_iter:
optimizer.zero_grad()
X, X_valid_len, Y, Y_valid_len =[x.to(device)for x in batch]
bos = torch.tensor([tgt_vocab['<bos>']]* Y.shape[0],
device=device).reshape(-1,1)
dec_input = d2l.concat([bos, Y[:,:-1]],1)# Teacher forcing
Y_hat, _ = net(X, dec_input, X_valid_len)
l = loss(Y_hat, Y, Y_valid_len)
l.sum().backward()# Make the loss scalar for `backward`
d2l.grad_clipping(net,1)
num_tokens = Y_valid_len.sum()
optimizer.step()with torch.no_grad():
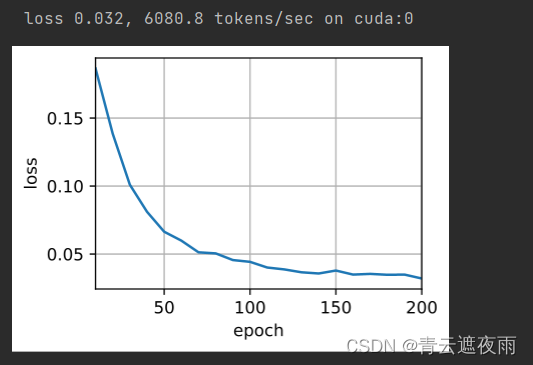
metric.add(l.sum(), num_tokens)if(epoch +1)%10==0:
animator.add(epoch +1,(metric[0]/ metric[1],))print(f'loss {metric[0]/ metric[1]:.3f}, {metric[1]/ timer.stop():.1f} 'f'tokens/sec on {str(device)}')
train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)
预测
defpredict_seq2seq(net, src_sentence, src_vocab, tgt_vocab, num_steps,
device, save_attention_weights=False):"""Predict for sequence to sequence.
Defined in :numref:`sec_seq2seq_training`"""# Set `net` to eval mode for inference
net.eval()
src_tokens = src_vocab[src_sentence.lower().split(' ')]+[
src_vocab['<eos>']]
enc_valid_len = torch.tensor([len(src_tokens)], device=device)
src_tokens = d2l.truncate_pad(src_tokens, num_steps, src_vocab['<pad>'])# Add the batch axis
enc_X = torch.unsqueeze(
torch.tensor(src_tokens, dtype=torch.long, device=device), dim=0)
enc_outputs = net.encoder(enc_X, enc_valid_len)
dec_state = net.decoder.init_state(enc_outputs, enc_valid_len)# Add the batch axis
dec_X = torch.unsqueeze(torch.tensor([tgt_vocab['<bos>']], dtype=torch.long, device=device), dim=0)
output_seq, attention_weight_seq =[],[]for _ inrange(num_steps):
Y, dec_state = net.decoder(dec_X, dec_state)# We use the token with the highest prediction likelihood as the input# of the decoder at the next time step
dec_X = Y.argmax(dim=2)
pred = dec_X.squeeze(dim=0).type(torch.int32).item()# Save attention weights (to be covered later)if save_attention_weights:
attention_weight_seq.append(net.decoder.attention_weights)# Once the end-of-sequence token is predicted, the generation of the# output sequence is completeif pred == tgt_vocab['<eos>']:break
output_seq.append(pred)return' '.join(tgt_vocab.to_tokens(output_seq)), attention_weight_seq
engs =['go .',"i lost .",'he\'s calm .','i\'m home .']
fras =['va !','j\'ai perdu .','il est calme .','je suis chez moi .']for eng, fra inzip(engs, fras):
translation, dec_attention_weight_seq = d2l.predict_seq2seq(
net, eng, src_vocab, tgt_vocab, num_steps, device,True)print(f'{eng} => {translation}, ',f'bleu {d2l.bleu(translation, fra, k=2):.3f}')
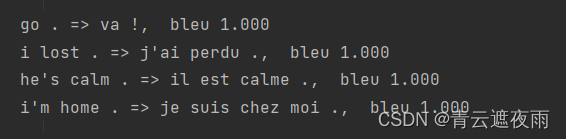
结果可以看到机器翻译的效果非常好。
注意力可视化
d2l.show_heatmaps(
enc_attention_weights.cpu(), xlabel='Key positions',
ylabel='Query positions', titles=['Head %d'% i for i inrange(1,5)],
figsize=(7,3.5))

可以看出模型对于一个序列的前面几个单词的注意力较大
尽管Transformer架构是为了序列到序列的学习而提出的,但Transformer编码器或Transformer解码器通常被单独用于不同的深度学习任务中。
版权归原作者 青云遮夜雨 所有, 如有侵权,请联系我们删除。