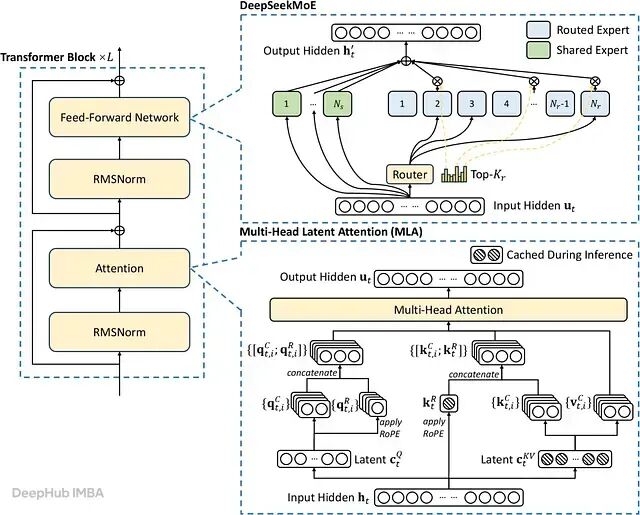
注意力架构变迁总结:稀疏、线性、SSM、混合架构如何摆脱 O(L²) 的代价
本文将介绍四条路线的原理、经过验证的基准测试数据,以及各自目前的生产落地情况。
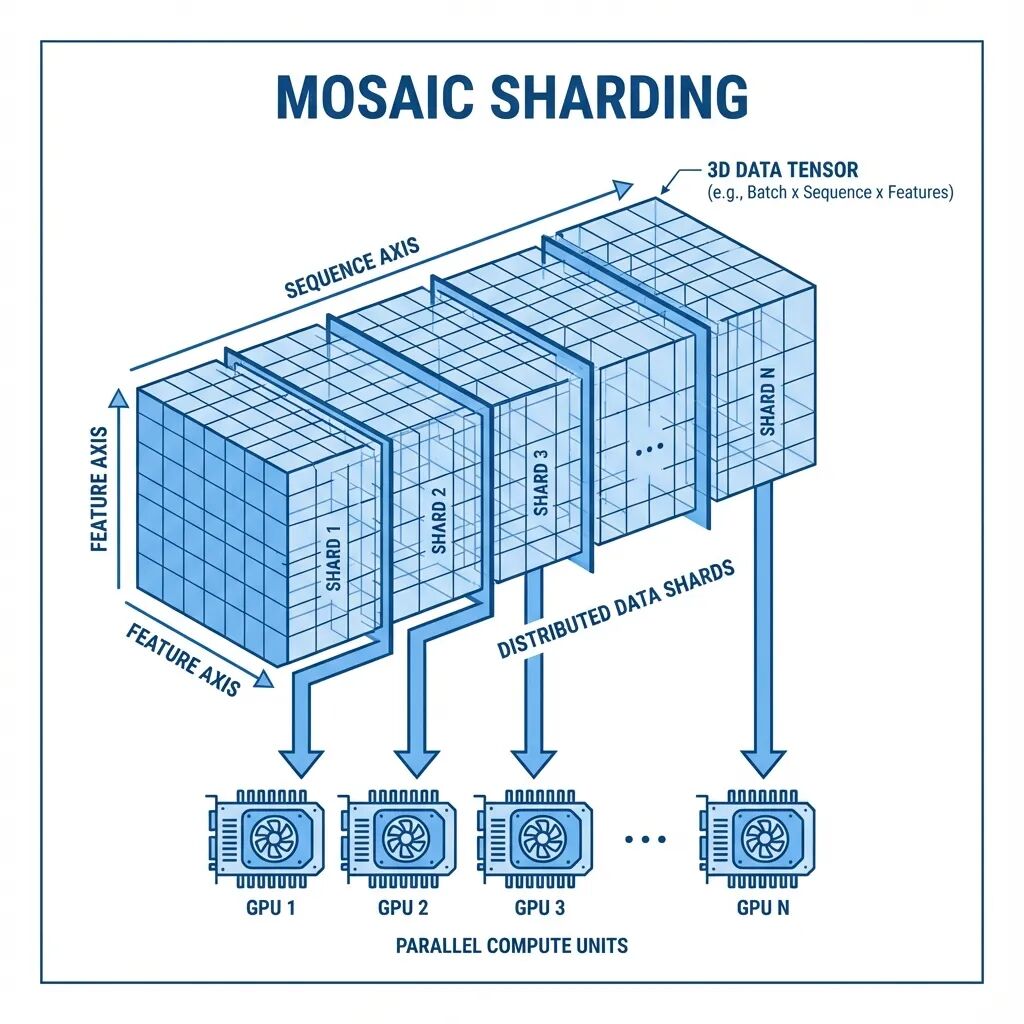
Mosaic:面向超长序列的多GPU注意力分片方案
本文从一个具体问题出发,介绍Mosaic这套多轴注意力分片方案的设计思路。
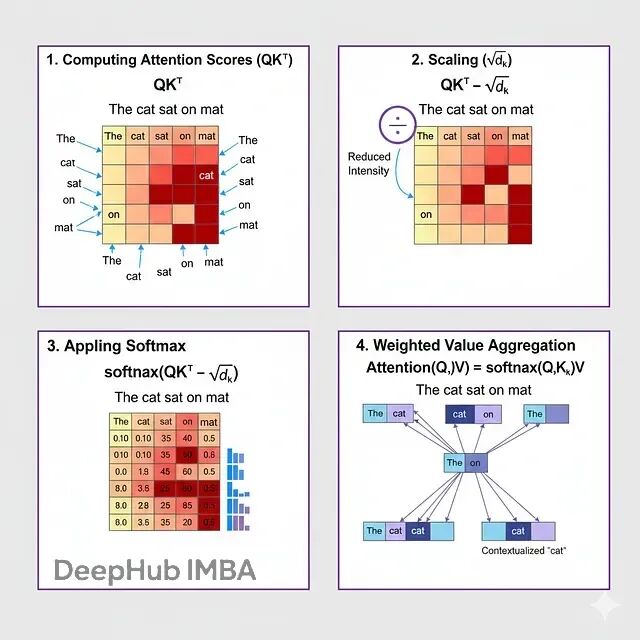
深入BERT内核:用数学解密掩码语言模型的工作原理
这篇文章会把MLM的数学机制拆开来逐一讲解。从一个被遮住的句子开始,经过注意力计算、概率分布、梯度下降,看看这些数学操作到底怎么让BERT达到接近人类的语言理解能力。搞懂这些数学原理,对于想要调优BERT或者设计类似模型的人来说很关键。

mmBERT:307M参数覆盖1800+语言,3万亿tokens训练
mmBERT是一个纯编码器架构的语言模型,在1800多种语言、3万亿tokens的文本上完成了预训练。
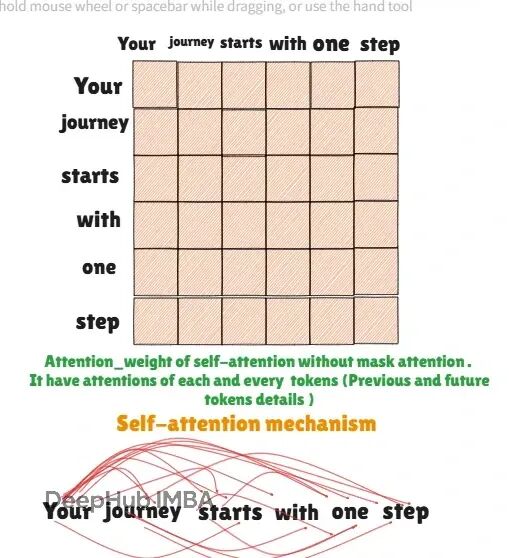
Transformer自回归关键技术:掩码注意力原理与PyTorch完整实现
掩码注意力(Causal Attention)是生成式模型的核心技术,它传统自注意力机制有根本的不同,掩码注意力限制模型只能关注当前位置之前的tokens,确保了自回归生成的因果性。
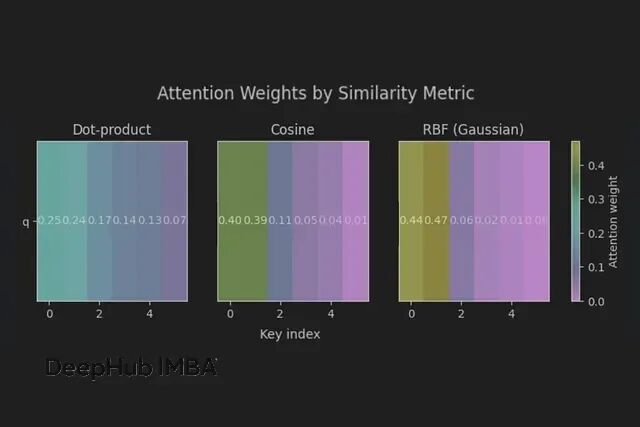
从另一个视角看Transformer:注意力机制就是可微分的k-NN算法
注意力就是一个带温控的概率邻居平均算法。温度设对了(1/sqrt(d)),邻域选对了(相似度+掩码),剩下的就是工程实现了。
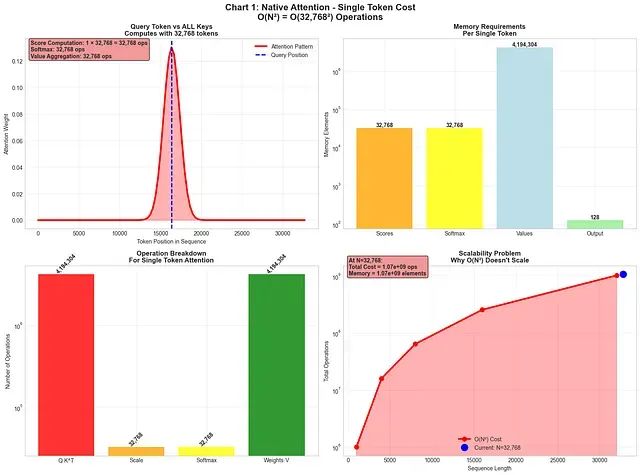
NSA稀疏注意力深度解析:DeepSeek如何将Transformer复杂度从O(N²)降至线性,实现9倍训练加速
本文将深入分析NSA的架构设计,通过详细的示例、可视化展示和数学推导,构建对其工作机制的全面理解,从高层策略到底层硬件实现均有涉及。
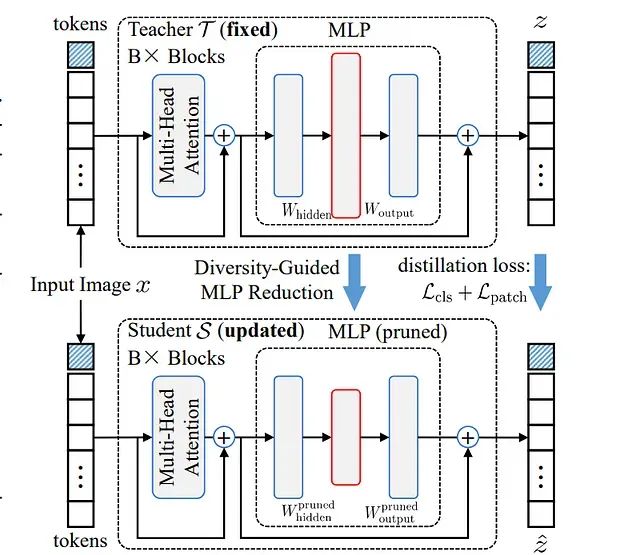
DGMR压缩技术:让大规模视觉Transformer模型体积减半而性能不减
DGMR采用基于Gram-Schmidt的剪枝策略,系统性地移除MLP层中的冗余神经元,同时通过精心设计的策略确保剩余权重的多样性,从而在知识蒸馏过程中实现高效的性能恢复。
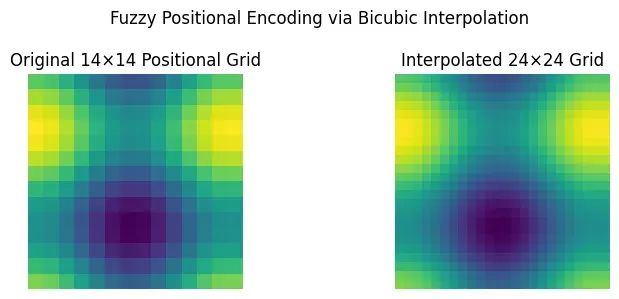
ViTAR:模糊位置编码让视觉Transformer适配任意分辨率图像
ViTAR代表了视觉Transformer技术的重要进步,特别是在处理多样化和高分辨率图像数据的应用场景中表现出显著优势。

基于Transformer架构的时间序列数据去噪技术研究
本文将详细探讨一种基于Transformer架构的时间序列去噪模型的构建过程及其应用价值。

MiTS与PoTS:面向连续值时间序列的极简Transformer架构
本文详细阐述了使原始Transformer架构能够高效处理连续值时间序列数据所需的最小化结构调整方案。
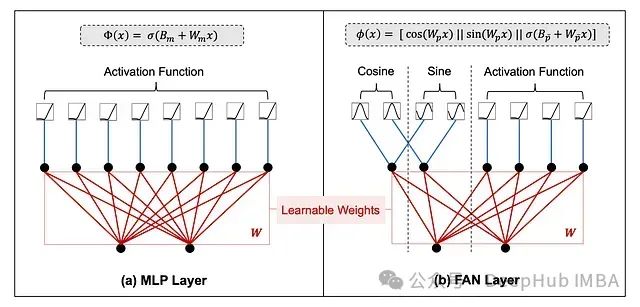
FANformer:融合傅里叶分析网络的大语言模型基础架构
FANformer通过将傅里叶分析网络(Fourier Analysis Network, FAN)整合到Transformer的注意力机制中,形成了一种创新的模型结构。

LLM模型添加自定义Token代码示例:为Llama 3.2模型添加思考与回答标记
本文将介绍如何为大型语言模型(LLM)添加自定义token并进行训练,使模型能够有效地利用这些新增token。

STAR: 利用时空注意力机制和动态频率损失的视频超分辨率增强框架
STAR (Spatial-Temporal Augmentation with Text-to-Video Models) 提出了一种创新的视频超分辨率解决方案,针对现有模型中存在的过度平滑和时间一致性不足等问题进行了系统性改进。
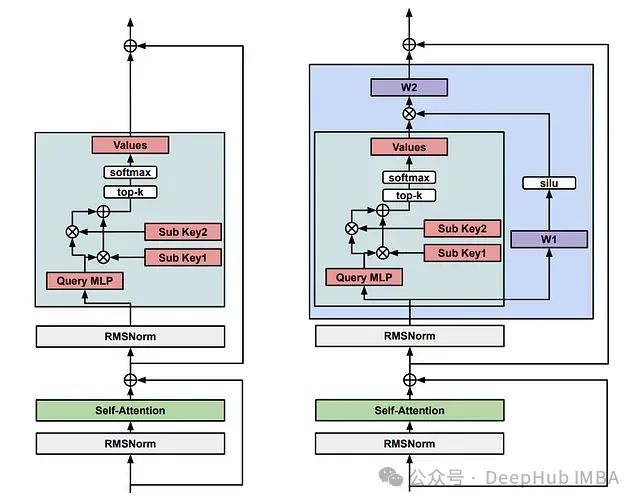
记忆层增强的 Transformer 架构:通过可训练键值存储提升 LLM 性能的创新方法
Meta 研究团队通过开发**记忆层**技术,成功实现了对现有大语言模型的性能提升。该技术通过替换一个或多个 Transformer 层中的前馈网络(FFN)来实现功能。
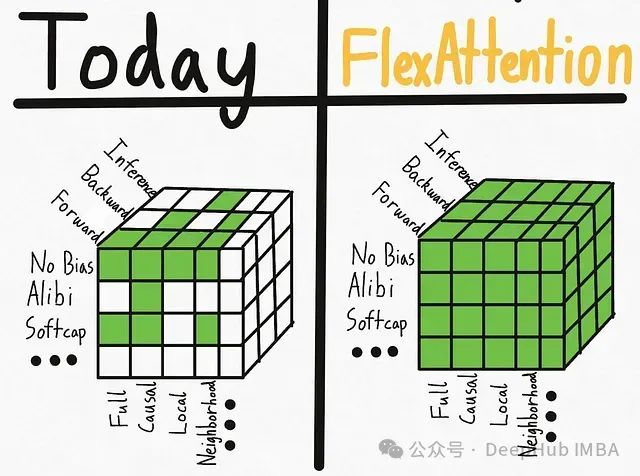
PyTorch FlexAttention技术实践:基于BlockMask实现因果注意力与变长序列处理
本文介绍了如何利用torch 2.5及以上版本中新引入的FlexAttention和BlockMask功能来实现因果注意力机制与填充输入的处理。
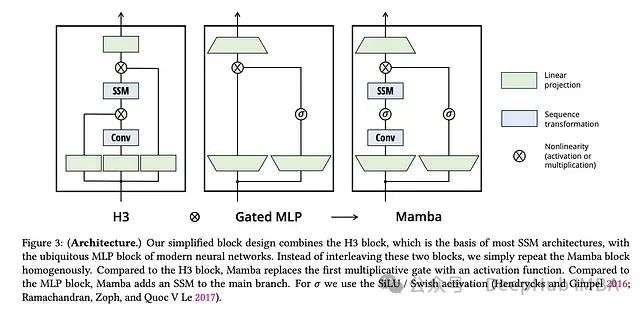
线性化注意力综述:突破Softmax二次复杂度瓶颈的高效计算方案
大型语言模型在各个领域都展现出了卓越的性能,但其核心组件之一——softmax注意力机制在计算资源消耗方面存在显著局限性。本文将深入探讨如何通过替代方案实现线性时间复杂度,从而突破这一计算瓶颈。
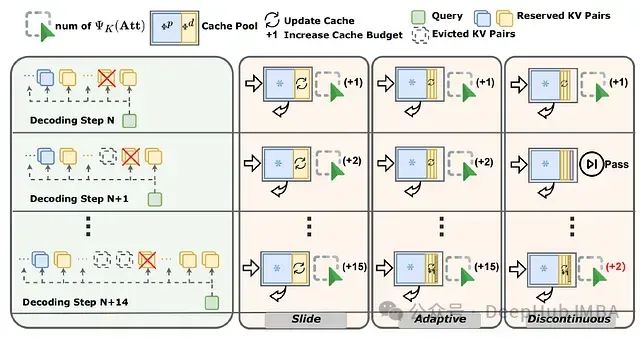
SCOPE:面向大语言模型长序列生成的双阶段KV缓存优化框架
SCOPE框架通过分离预填充与解码阶段的KV缓存优化策略,实现了高效的缓存管理。该框架保留预填充阶段的关键KV缓存信息,并通过滑动窗口、自适应调整和不连续更新等策略,优化解码阶段的重要特征选取,显著提升了长语言模型长序列生成的性能。
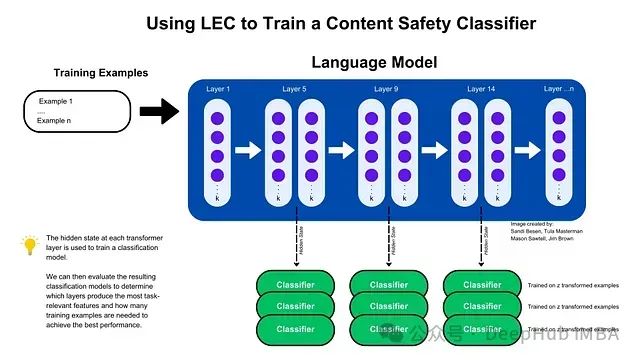
LEC: 基于Transformer中间层隐藏状态的高效特征提取与内容安全分类方法
通过利用Transformer中间层的隐藏状态,研究提出了层增强分类(LEC)技术,该技术能够以极少的训练样本和参数实现高效的内容安全和提示注入攻击分类,显著提升了模型的性能,并验证了其跨架构和领域的泛化能力。



