7.卷积和Transformer结合的ViT
前面两节课我们讲了Swin Transformer的结构,以及其中的细节部分,进行了实现,其中由Swin Block 以及 Patch Merging等等,上节课讲了 SW-MSA的shift和mask,对于shift之后,其中window中需要的保留,不需要的去掉,用到了boardcasting等
Swin-Transformer 详解
用动画深入解释Swin-Transformer
TimeGPT:时间序列预测的第一个基础模型
在本文中,我们将探索TimeGPT背后的体系结构以及如何训练模型。然后,我们将其应用于预测项目中,以评估其与其他最先进的方法(如N-BEATS, N-HiTS和PatchTST)的性能。
人工智能各领域跨界能手——Transformer
导读:Transformer源自于AI自然语言处理任务;在计算机视觉领域,近年来Transformer逐渐替代CNN成为一个热门的研究方向。此外,Transformer在文本、语音、视频等多模态领域也在崭露头角。本文对Transformer从诞生到逐渐壮大为AI各领域主流模型的发展过程以及目前研究进
Huggingface Transformers Deberta-v3-base安装踩坑记录
huggingface deberta-v3-base下载踩坑记录
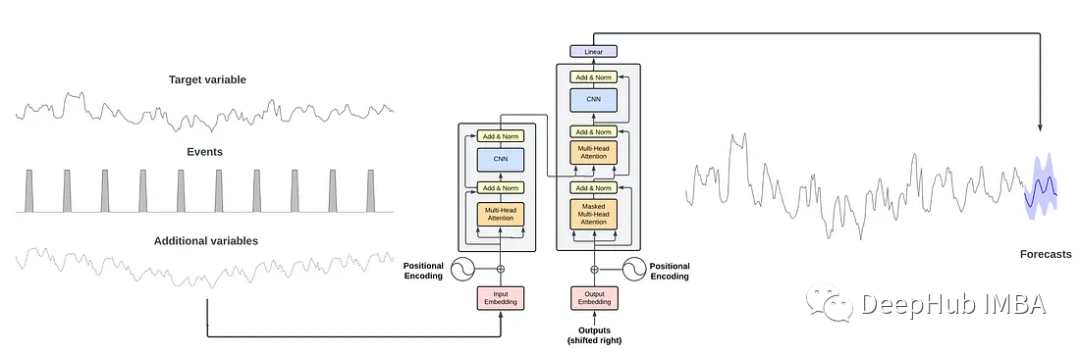
使用 Temporal Fusion Transformer 进行时间序列预测
Temporal Fusion Transformer(TFT)是一个基于注意力的深度神经网络,它优化了性能和可解释性,顶层架构如下图所示。TFT架构的优点如下:能够使用丰富的特征:TFT支持三种不同类型的特征:外生类别/静态变量,也称为时不变特征;具有已知输入到未来的时态数据,仅到目前已知的时态数
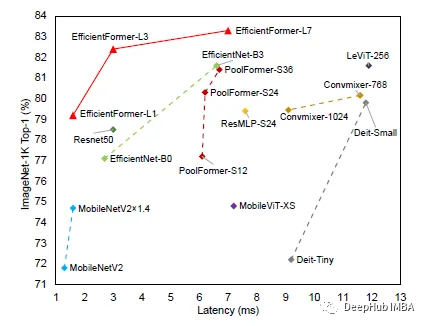
EfficientFormer:高效低延迟的Vision Transformers
我们都知道Transformers相对于CNN的架构效率并不高,这导致在一些边缘设备进行推理时延迟会很高,所以这次介绍的论文EfficientFormer号称在准确率不降低的同时可以达到MobileNet的推理速度。

使用QLoRA对Llama 2进行微调的详细笔记
本文是一个良好的开端,因为可以把我们在这里学到的大部分东西应用到微调任何LLM的任务中。
Swin-Transformer 实战代码与讲解(快速上手)
Swin Transformer是2021年微软研究院发表在ICCV上的一篇文章,并且已经获得ICCV 2021 best paper的荣誉称号。它可以作为计算机视觉的通用backbone,并且在很多视觉底层任务中取得了Sota的水准。
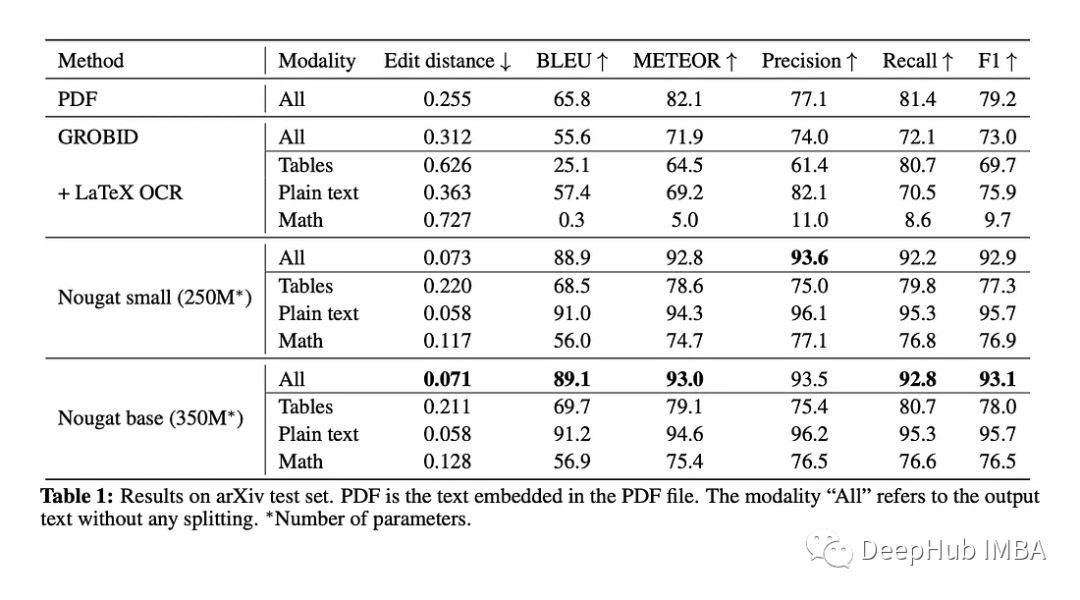
Nougat:一种用于科学文档OCR的Transformer 模型
Nougat是一种VIT模型。它的目标是将这些文件转换为标记语言,以便更容易访问和机器可读。
timm使用swin-transformer
swin-transformer
【深度学习】Transformer,Self-Attention,Multi-Head Attention
必读文章:论文名:Attention Is All You Need。
使用 Transformer 和 Amazon OpenSearch Service 构建基于列的语义搜索引擎
在数据湖中,对于数据清理和注释、架构匹配、数据发现和跨多个数据来源进行分析等许多操作,查找相似的列有着重要的应用。如果不能从多个不同的来源准确查找和分析数据,就会严重拉低效率,不论是数据科学家、医学研究人员、学者,还是金融和政府分析师,所有人都会深受其害。传统解决方案涉及到使用词汇关键字搜索或正则表
【代码笔记】Transformer代码详细解读
Transformer代码详细解读
锂电池寿命预测 | Pytorch实现基于Transformer 的锂电池寿命预测(NASA数据集)
锂电池寿命预测 | Pytorch实现基于Transformer 的锂电池寿命预测(NASA数据集)
在YOLOv5中添加Swin-Transformer模块
提供了一个在YOLOv5代码中添加SwinTransformer相应模块的代码仓库,并对使用方法进行了简单介绍。
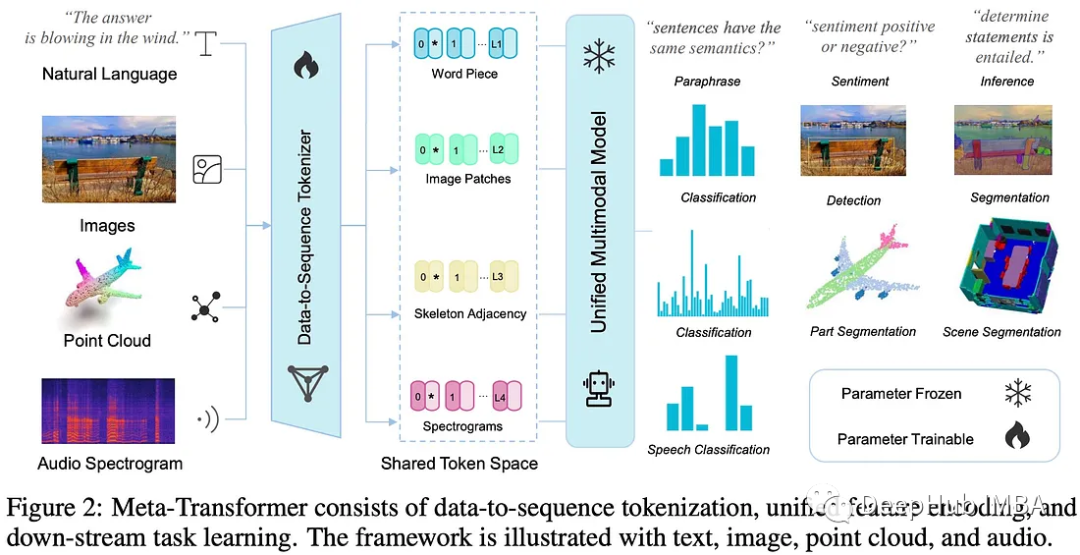
Meta-Transformer 多模态学习的统一框架
Meta-Transformer是一个用于多模态学习的新框架,用来处理和关联来自多种模态的信息
YOLOv5+Swin Transformer
YOLOv5+swin tansformer里遇到的报错
Vision Transformer 模型详解
关于Vision Transformer模型的详解 ,末尾附原论文下载链接以及pytorch代码。
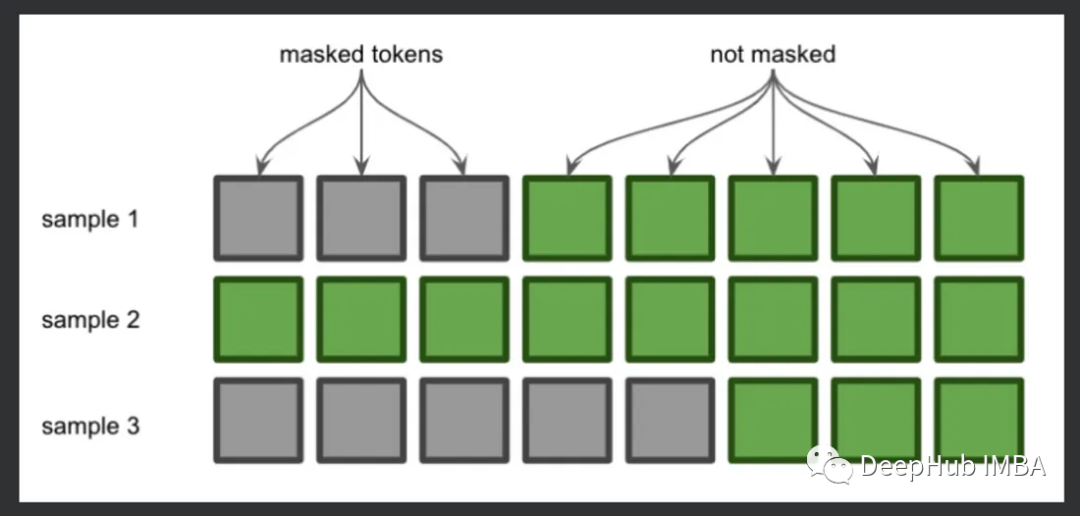
注意力机制中的掩码详解
本文将详细介绍掩码的原理和机制。



