一文弄懂 Transformer模型(详解)
Transformer自注意力机制是一种在自然语言处理(NLP)领域中广泛使用的机制,特别是在Transformer模型中,这种机制允许模型在处理序列数据时,能够捕捉到序列内部不同位置之间的相互关系。1、查询(Query)、键(Key)、值(Value):自注意力机制将输入序列中的每个元素视为一个查
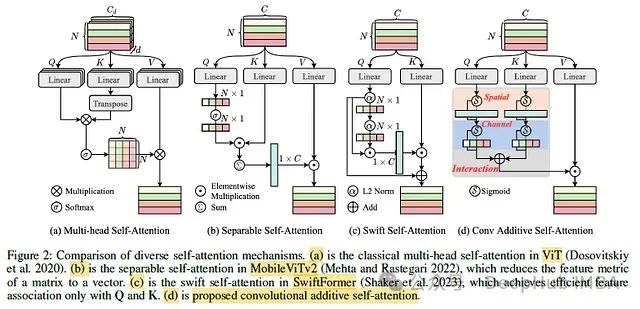
CAS-ViT:用于高效移动应用的卷积加法自注意力视觉Transformer
这是8月份再arxiv上发布的新论文,我们下面一起来介绍这篇论文的重要贡献
[医疗 AI ] 3D TransUNet:通过 Vision Transformer 推进医学图像分割
医学图像分割在推进医疗保健系统的疾病诊断和治疗计划中起着至关重要的作用。U 形架构,俗称 U-Net,已被证明在各种医学图像分割任务中非常成功。然而,U-Net 基于卷积的操作本身限制了其有效建模远程依赖关系的能力。为了解决这些限制,研究人员转向了以其全局自我注意机制而闻名的 Transformer
【爆火】TransUNet:融合Transformer与U-Net的医学图像分割神器!
在医学图像分割领域,传统的U-Net模型已经取得了显著成果。然而,随着Transformer在计算机视觉领域的崛起,将其与U-Net结合的TransUNet模型成为了新的热门。TransUNet是一种融合了Transformer和U-Net结构的深度学习模型,旨在提高医学图像分割的精度。它结合了Tr
Conformer:用于语音识别的卷积增强Transformer
Transformer模型善于捕捉基于内容的全局交互,而CNN则能有效地利用局部特征。在这项工作中,通过研究如何将卷积神经网络和Transformer结合起来,以参数有效的方式对音频序列的局部和全局依赖关系进行建模,从而达到两全面性。为此,提出了用于语音识别的卷积增强Transformer,命名为C
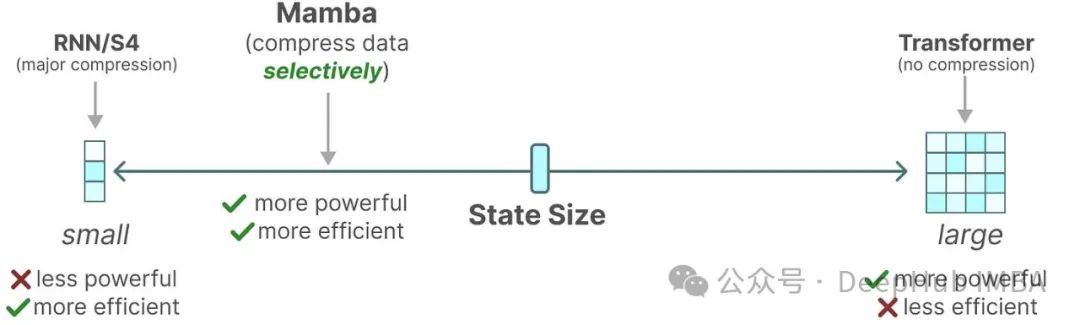
Transformer、RNN和SSM的相似性探究:揭示看似不相关的LLM架构之间的联系
通过探索看似不相关的大语言模型(LLM)架构之间的潜在联系,我们可能为促进不同模型间的思想交流和提高整体效率开辟新的途径。
ViT论文详解
ViT是谷歌团队在2021年3月发表的一篇论文,论文全称是《AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE》一张图片分成16x16大小的区域:使用Transformer进行按比例的图像识别。ViT是V
Transformer模型解析(附案例应用代码)
自注意力机制是Transformer模型的核心,它允许模型在编码每个单词时同时关注序列中的其他单词,从而捕捉到单词之间的依赖关系。位置编码的生成使用了正弦和余弦函数的不同频率,以确保编码在不同维度上具有不同的模式,从而使模型能够区分不同位置的单词。这样,每个头可以学习到序列的不同方面,最终的输出是所
利用 VAE、GAN 和 Transformer 释放生成式 AI
生成式人工智能是人工智能和创造力交叉的一个令人兴奋的领域,它通过使机器能够生成新的原创内容,正在彻底改变各个行业。从生成逼真的图像和音乐作品,到创建逼真的文本和身临其境的虚拟环境,生成式人工智能正在推动机器所能实现的界限。在这篇博客中,我们将踏上探索生成式人工智能与VAE、GAN和Transform
Qwen-VL大模型LoRA微调、融合及部署
Qwen-VL大模型LoRA微调、融合及部署
详解视觉Transformers
从2017年在《Attention is All You Need》中首次提出以来,Transformer模型已经成为自然语言处理(NLP)领域的最新技术。在2021年,论文《An Image is Worth 16x16 Words》成功地将Transformer应用于计算机视觉任务。从那时起,基
LLaMA3技术报告解读
语言模型预训练。将一个大型多语言文本语料库转换为离散的标记,然后在由此产生的数据上预训练一个大型语言模型,以执行下一个标记的预测。在训练过程中使用了8K标记的上下文窗口,在15.6Ttoken上预训练了一个拥有405B参数的模型。在标准预训练之后,还会继续进行预训练,将支持的上下文窗口增加到128k
RWKV: 与Transformer和Mamba掰掰手腕的小家碧玉
开源项目RWKV是一个“具有 GPT 级别LLM性能的RNN,也可以像transformer并行训练。它主要是解决了Transformer的高成本。注意力机制是 Transformer 霸权背后的驱动力之一。
(Hugging Face)如何训练和评估 Transformer 模型(代码 + 实践)
这个函数在实例化时,它需要一个分词器(tokenzier)以便知道使用哪个填充用的 token,以及模型填充在输入的左侧或右侧。填充到该批次中最长序列的长度,而不是填充到整个数据集中最长序列的长度。最后一项我们需要做的是,当我们将元素一起进行批处理时,将所有 example 填充到最长的句子的长度。
7.2 Transformer:具有里程碑意义的新模型——自注意力模型
自此,不管是学术界,还是工业界均掀起了基于Transformer的预训练模型研究和应用的热潮,并且逐渐从NLP领域延伸到CV、语音等多项领域。Transformer模型是一个具有里程碑意义的模型,它的提出催生了众多基于Transformer网络结构的模型,特别是在2018年预训练模型BERT的提出,
CAS-ViT: 高效移动应用的卷积加性自注意Vision Transformer
Vision Transformer(ViTs)是一种在神经网络领域取得了革命性进展的模型,它通过标记混合器(token mixer)强大的全局上下文能力,实现了对图像分类、目标检测、实例分割和语义分割等多个视觉任务的高效处理。然而,在资源受限场景和移动设备等实时应用中,成对的标记亲和力(token
Transformer应用之情感分析 - Transformer教程
Transformer模型凭借其自注意力机制在情感分析中展现了强大的能力。本文详细介绍了Transformer模型的基本原理、数据预处理方法以及实际应用实例。无论是企业、研究人员还是政府组织,都能通过Transformer模型获取更深入的情感洞察。Transformer模型凭借其自注意力机制在情感分
从零入门AI for Science(AI+化学)#Datawhale夏令营
关于随机森林(想细致了解可以看一下下面这两位博主)是 Datawhale 2024 年 AI 夏令营第三期的学习活动,基于天池平台开展的实践学习有感兴趣的同学可去http://competition.sais.com.cn/competitionDetail/532233/format(赛事网址)了
江大白 | 视觉Transformer与Mamba的创新改进,完美融合(附论文及源码)
在本文中,作者引入了MambaVision,这是首个专门为视觉应用设计的Mamba-Transformer混合骨架。作者提出了重新设计Mamba公式的方法,以增强全局上下文表示的学习能力,并进行了混合设计集成模式的综合研究。
如何评判大模型的输出速度?首Token延迟和其余Token延迟有什么不同?
如果你使用商用大模型,或者使用开源大模型本地化部署,除了生成的质量之外,另外一个关键的指标就是生成token的速度。而且并不是简单的每秒生成多少个token,而是拆成了两个阶段: 1. prefill:预填充,并行处理输入的 tokens。 2. decoding:解码,逐个生成下一个 toke



