14篇最新Transformer热门论文!涵盖注意力机制、架构改进、适用性扩展等
实验表明,M2在非因果BERT风格语言建模、ViT风格图像分类和因果GPT风格语言建模中表现出色,与BERT-base和BERT-large在GLUE质量上相匹配,参数最多减少27%,在ImageNet上精度提高,同时在The PILE的预训练困惑中以360M参数匹配GPT风格的Transforme
从《2024 年人工智能指数报告》可以看出什么?AI的现状和可见的未来?
近日,斯坦福大学以人为本AI研究所(Stanford HAI)发布了《2024 年人工智能指数报告》(Artificial Intelligence Index Report 2024)。据Stanford HAI 官方介绍道:“这是我们迄今为止最全面的报告,而且是在人工智能对社会的影响从未如此明显
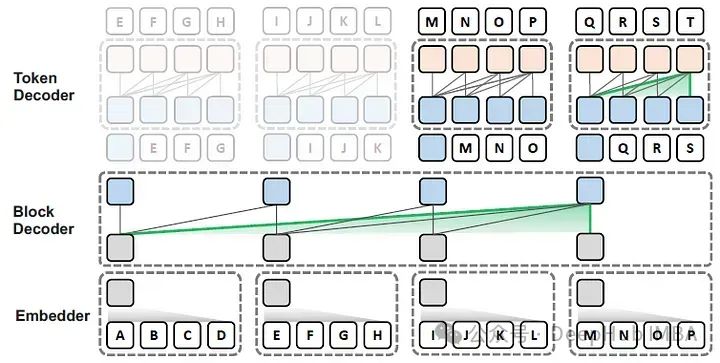
Block Transformer:通过全局到局部的语言建模加速LLM推理
在这篇论文中,作者提出了Block Transformer架构,该架构通过在较低层次之间的粗糙块(每个块代表多个令牌)的自注意力来模拟全局依赖性,并在较高层次的每个局部块内解码细粒度的令牌,
8类CNN-Transformer混合架构魔改方案盘点,附23个配套模型&代码
为进一步提高模型的性能,我们将。目前,它已经成为我们研究视觉任务、发文章离不开的模型。针对CNN+transformer组合方向的研究也成为了当下计算机视觉领域研究中的大热主题。CNN-Transformer架构凭借众所周知的优势,在视觉任务上取得了令人瞩目的效果,它不仅可以提高模型在多种计算机视觉
模型被投毒攻击,如今有了新的安全手段,还被AI顶刊接收
诚实节点则会收到奖励。:FLock 的实验结果也指出,在恶意节点占比较多的时候(即 \eta 增大时),较大的惩罚力度也会造成部分诚实节点的存活时间缩短(因为每一轮的提议者和投票者是随机选取的)。基于 PoS 和《The Resistance》的启发,FLock 提出了一个新颖的基于区块链的 FL
【海思Hi3516CV610】是面向新一代视频编解码标准、网络安全和隐私保护、人工智能行业应用方面的IPC SoC
海思Hi3516CV610是面向新一代视频编解码标准、网络安全和隐私保护、人工智能行业应用方面的IPC SoC
人工智能(二)-Transformer模型
上篇文章以对话模式为例讲了目前人工智能的整体架构,但是大模型依然有很多细节问题,这里作者讲一讲目前的Transformers模型原理。

长序列中Transformers的高级注意力机制总结
本文的重点是深入研究长序列种应用的高级注意力机制的数学复杂性和理论基础
AI大模型系列之三:Swin Transformer 最强CV图解(深度好文)
SwinTransformer是一种为视觉领域设计的分层Transformer结构。它的两大特性是滑动窗口和分层表示。滑动窗口在局部不重叠的窗口中计算自注意力,并允许跨窗口连接。分层结构允许模型适配不同尺度的图片,并且计算复杂度与图像大小呈线性关系。Swin Transformer借鉴了CNN的分层
人工智能---什么是Transformer?
Transformer是一种强大的神经网络架构,最初由Google的研究人员在论文《Attention is All You Need》中提出,用于自然语言处理任务,特别是在机器翻译方面取得了巨大成功。Transformer的核心思想是完全基于自注意力机制(self-attention mechan
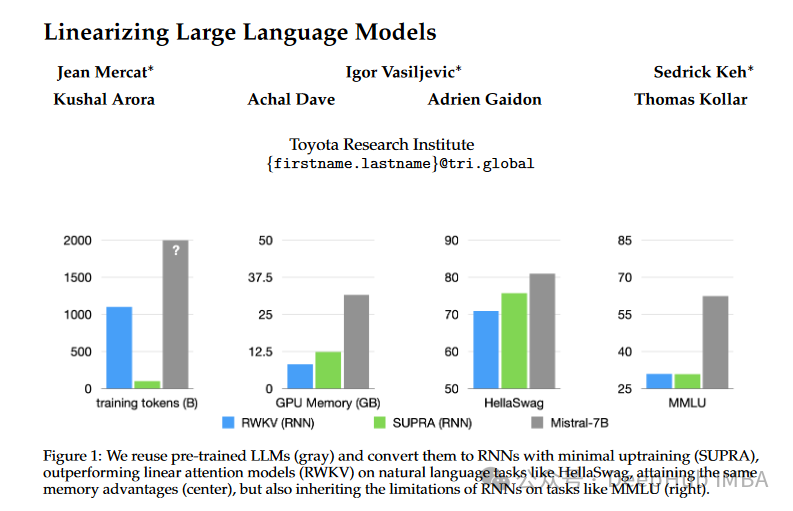
SUPRA:无须额外训练,将Transformer变为高效RNN,推理速度倍增
SUPRA方法旨在将预训练的大型语言模型(LLMs)转化为RNNs,具体步骤包括替换softmax归一化为GroupNorm,使用一个小型MLP投影queries和keys。
本地部署Llama3 8b用Ollama和open-webui
设置模型 Settings > Models > Pull a model from Ollama.com。, 由于笔记本GPU的限制只能部署8b 的 llama3, 4.7GB。问题: 鸡兔同笼,鸡有100只,鸡足比兔足多80只,鸡兔分别有多少只?自由女神像每天一动不动,她真的自由么?下载完成后,
Linux快速部署大语言模型LLaMa3,Web可视化j交互(Ollama+Open Web UI)
本文介绍了大规模语言模型的相关概念,并介绍了使用开源工具Ollama部署LLaMa3大模型、使用Open WebUI搭建前端Web交互界面的方法和流程。
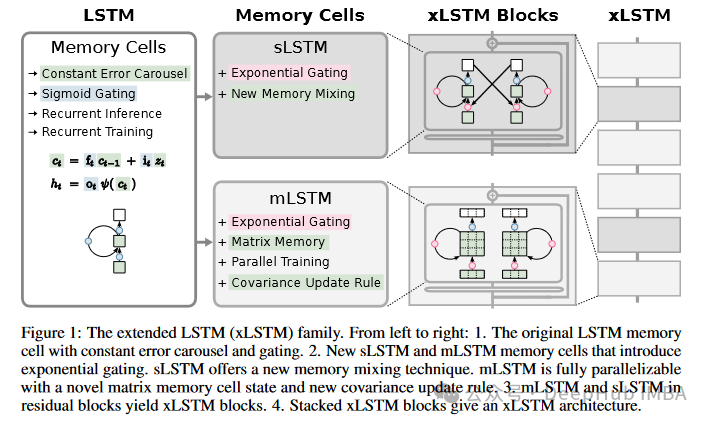
深入解析xLSTM:LSTM架构的演进及PyTorch代码实现详解
xLSTM的新闻大家可能前几天都已经看过了,原作者提出更强的xLSTM,可以将LSTM扩展到数十亿参数规模,我们今天就来将其与原始的lstm进行一个详细的对比,然后再使用Pytorch实现一个简单的xLSTM。
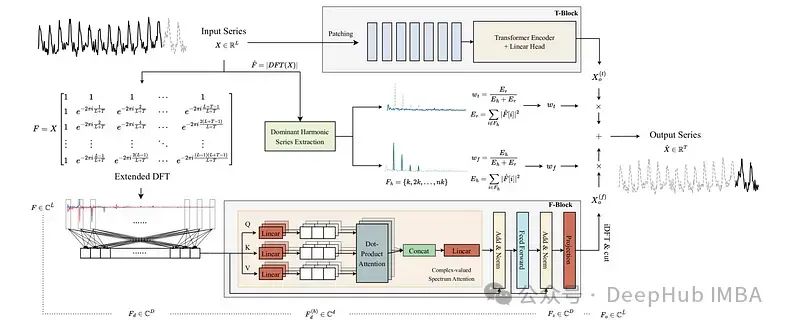
ATFNet:长时间序列预测的自适应时频集成网络
ATFNet是一个深度学习模型,它结合了时间域和频域模块来捕获时间序列数据中的依赖关系。这是4月发布在arxiv上的论文,还包含了源代码。

Transformers 加速的一些常用技巧
我们今天来总结以下一些常用的加速策略
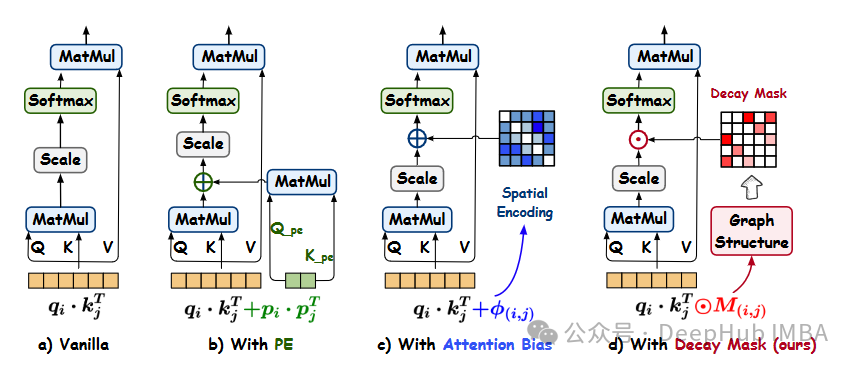
Gradformer: 通过图结构归纳偏差提升自注意力机制的图Transformer
Gradformer通过引入带有可学习约束的指数衰减掩码,为图Transformer提供了一种新的方法,有效地捕捉了图结构中的本地和全局信息。
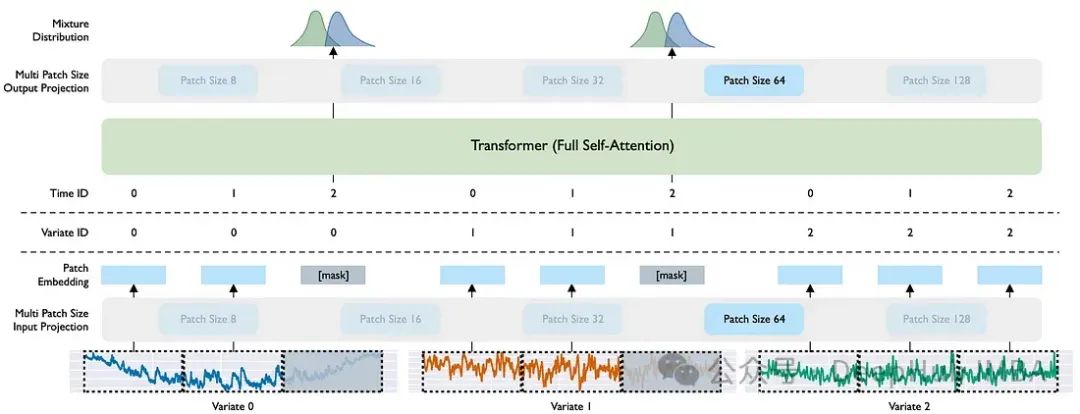
Moirai:Salesforce的时间序列预测基础模型
在本文中,我们将探索用于时间序列预测的 Salesforce 新发布的基础模型 Moirai。最后我们还对比Moirai 与其他两个基础模型之间的差异
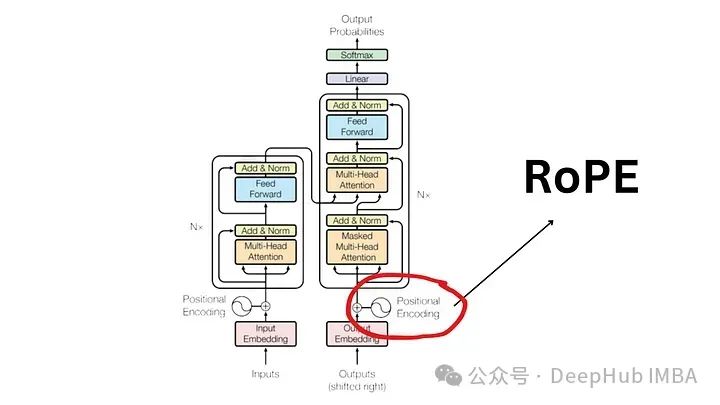
大语言模型中常用的旋转位置编码RoPE详解:为什么它比绝对或相对位置编码更好?
旋转位置嵌入是最先进的 NLP 位置嵌入技术。大多数流行的大型语言模型(如 Llama、Llama2、PaLM 和 CodeGen)已经在使用它。在本文中,我们将深入探讨什么是旋转位置编码,以及它们如何巧妙地融合绝对位置嵌入和相对位置嵌入的优点。
经典文献阅读之--Swin Transformer
Transfomer最近几年已经霸榜了各个领域,之前我们在《》这篇博客中对DETR这个系列进行了梳理,但是想着既然写了图像处理领域的方法介绍,正好也按照这个顺序来对另一个非常著名的Swin Transformer框架。框架相较于传统Transformer精度和速度比CNN稍差,Swin Transf



