
7.卷积和Transformer结合的ViT
一、回顾与简介
前面两节课我们讲了Swin Transformer的结构,以及其中的细节部分,进行了实现,其中由Swin Block 以及 Patch Merging等等,上节课讲了 SW-MSA的shift和mask,对于shift之后,其中window中需要的保留,不需要的去掉,用到了boardcasting等等。
这节课我们考虑卷积和Transformer如何结合,我们首先看一下conv是如何计算的,如果输入是5×5,卷积核是3×3,进行一个滑窗之后,最终输出是3×3的特征图
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jMZHI9DA-1678713307018)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230311213828594.png)]](https://img-blog.csdnimg.cn/e2de4c75033f407496eb6fcba1174800.png)
那我们看一下细节,如何实现
1×1的卷积可以对通道数进行修改,比如我们现在是4×4×3的图像,用1×1卷积核计算完,如果out_channels为4,那么输出的结果就是4×4×4的特征图
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nFo94gJJ-1678713307019)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230312111033144.png)]](https://img-blog.csdnimg.cn/855d705e69e242abba65e962f58574d8.png)
如果是4×4大小,3通道的图像,输出要求 图像大小不变,通道数变为4,Transformer有QKV三个映射,分别映射到embedd_dim的维度,通过进行QK’再乘以V![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mOOjKKfT-1678713307019)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230312111313275.png)]](https://img-blog.csdnimg.cn/9fd2224251b141b28c6bbf0c53f6ffd0.png)
可以看出Transformer与CNN有点像,需要注意的是:
1.conv是利用滑窗来算,Attn是计算当前tensor中每一个位置对其他位置的关系,但是他们两个又可以同时完成一个状态,对输入的tensor求一个表征,并还可以给它改变一个维度
比如我们输入的尺寸没变,输入的通道数从3变为了4,Conv和Transformer都可以做到的
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Rj3vSC1G-1678713307019)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230312111921153.png)]](https://img-blog.csdnimg.cn/8babc3e7b2b24ebbb60ee1bc97b4e0cb.png)
如果我们将它们内部实现封起来,当作黑盒来看,它们完成的事情是类似的,只不过它们具体的计算方式不一样:
conv是一个相对于固定的窗口在输入的tensor上进行滑动的操作,乘以的是固定的conv kernel,我们可以叫做相对local的状态,算的是局部的信息;而Transformer谁都可以看,它看到的是gloab全局的信息,这就是它俩的区别。我可以单独用gloab的信息或者local的信息,但也有一种可能性是我们将它俩结合,目前conv是比Transformer计算量更小的,如果需要更小模型的场景上conv是更work的。![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IixG15OQ-1678713307020)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230312113209943.png)]](https://img-blog.csdnimg.cn/63117d112c6f422cb87b2a638b4cb8df.png)
今天讲的 MobileViT 就使用了下图的这样一种的结构,其中使用了Transformer,红线是Residual map path,我们要做的就是Conv+Transformer
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Sow0WWKx-1678713307020)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230312114106289.png)]](https://img-blog.csdnimg.cn/79ca655ebb564420a0b6f9c987045d96.png)
整体结构中,前面有一部分是传统的Conv层,中间有一部分是Transformer层,其中起了MV2 Block和MViT Block,MV2 Block对应的MobileNetV2的一个block的结构,类似Resnet block的结构,MViT Block等会儿我们会讲。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VkcPjxtP-1678713307020)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230312114627328.png)]](https://img-blog.csdnimg.cn/54d2dfba11bf47b0aae037e442a60954.png)
通常我们会将前面的输入层叫做 Stem层(输入,3×3的卷积核,再加pooling)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LDOGHOLL-1678713307020)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230312115321660.png)]](https://img-blog.csdnimg.cn/8a314d334d114b1fadb2c69e2949c950.png)
最后在Global Pool之后叫 head层
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LZgIezbp-1678713307020)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230312115326583.png)]](https://img-blog.csdnimg.cn/8af2e1f6fa00403ca6b17825ce896403.png)
在中间就是block层,看一下核心模块MV2 Block的网络结构,当Stride=1 或者 2的时候,架构是不一样的,其中用的激活函数是Silu函数在左侧显示,而Silu与Gelu的对比在右侧,蓝色线是Gelu,它们在计算时指数有一点点不一样。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QyyjX4KB-1678713307020)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230312195707806.png)]](https://img-blog.csdnimg.cn/dc7a281acbdc4895884ae55a20c7a385.png)
我们可以看到Block通常接一个1×1的卷积,是为了调整tensor的通道数,而DConv是加了Group Conv,为了减少计算量,之后加BN和Silu,最后加1×1的卷积和BN是为了调回来,最后Add进行残差——这就是一个MV2 Block的一个架构。
MobileVit就是将其中MV2 Block中一些模块替换为ViT Block
二、论文
首先看Xl ,它是H×W×d,它是经过1×1卷积之后得到的tensor,经过一个flatten(non-overlapping)的切分后,得到了XU ,其中用到了Inter-patch relationship,这就是本篇论文的核心,得到经过Transformer的XG 之后,又做了point-wise convlution 以及 concatenation operation 还有N×N的卷积
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iGxFcNiM-1678713307021)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230312200451608.png)]](https://img-blog.csdnimg.cn/8d0a327447a64114a0ad9d20b7e188ec.png)
读完文字后,脑子中可能还有点模糊,我们需要拿图像来更加直观和清晰地展现网络结构,上面3×3和1×1的卷积对应的就是第一段的内容,它对tensor无非就是做一些shape变换操作,之后还需要做一些操作才能进入Transformer,我们Transformer原则上是不改变tensor的尺度的,输出之后应该还是某一个tensor,我们再做后续的部分1×1的Conv等等
最关键的部分是画蓝色块的部分,比如卷积过后 H× W× d这么一个tensor,怎么样输入到Transformer中去?
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kIYqCKs6-1678713307021)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230312201528936.png)]](https://img-blog.csdnimg.cn/86dfa61026b542eaafaad58e50427141.png)
具体来讲,最左边的输出是Conv后的结果,我们需要进行Patch Partition操作,这里其实可以叫做window操作,在H× W× d的这样一个尺寸上切出小window出来,比如我们切出9个window,A B C 到I,经过上一节课的学习,我们知道如果是Swin的话我们就在window上自注意力的计算,而MobileViT做的不一样
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xqf89Ihb-1678713307021)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230312203432834.png)]](https://img-blog.csdnimg.cn/eae1a733514548b78dbece7d6aa6aef6.png)
在Transformer做的操作是将 H× W× d 输入进行flatten拉直,比如我们可以将A扯平,变为1×d,可以将每个patch展开成为中间这样
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-L0JxzLS7-1678713307021)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230312203410879.png)]](https://img-blog.csdnimg.cn/ce55c1cd817f4850a680221f5bbd8297.png)
其中会将A B C到 I的第一个token取出来,送到Transformer中去,当然Transformer不改变维度,第一个做完继续做第二个token,再送到Transformer中进行计算。
从整体看,我们假如是2×2的窗口,我们第一个取每个窗口中第一个元素,来算Self-attention;之后再算第二个位置的,如果是2×2的窗口,一共做4次,如果是3×3的窗口,那就做9次,但是MobileViT是固定2×2的窗口
这么做的目的是:为了看到全局的信息,还要减少计算量,和空洞卷积类似
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Wmq1EqNg-1678713307021)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230312203740758.png)]](https://img-blog.csdnimg.cn/0fb09d41e3c346128576c2a98b4400dc.png)
三、代码实现
3.1 Swin完善
上一届对Swin Transformer的 WindowAttention的MSA,SW-MSA,SwinBlock进行了代码
今天我们对Swin Stage以及整个Swin 的Class代码进行编写
# CLass 7classSwinStage(nn.Module):def__init__(self, dim, input_resolution, depth, num_heads, window_size, patch_merging =None):super().__init__()
self.blocks = nn.ModuleList()for i inrange(depth):
self.blocks.append(
SwinBlock(dim= dim,
input_reslution=input_resolution,
num_heads= num_heads,
window_size = window_size,
shift_size=0if(i %2==0)else window_size//2))if patch_merging isNone:# 最后一个 stage不做patch_merging
self.patch_merging = Indentity()else:
self.patch_merging = PatchMerging(input_resolution=input_resolution,dim = dim)defforward(self, x):for block in self.blocks:
x = block(x)
x = self.patch_merging(x)return x
Swin块:
# CLass 7classSwin(nn.Module):def__init__(self,
image_size=224,
patch_size=4,
in_channels=4,
embed_dim=96,
window_size=7,
num_heads=[3,6,12,24],
depths=[2,2,6,2],
num_classes=1000):super().__init__()
self.num_classes = num_classes
self.depths = depths
self.num_heads = num_heads
self.embed_dim = embed_dim
self.num_stages =len(depths)
self.num_features =int(self.embed_dim *2**(self.num_stages-1))
self.patch_resolution =[image_size // patch_size , image_size // patch_size]
self.patch_embedding = PatchEmbedding(patch_size=patch_size, embed_dim= embed_dim)
self.stages =nn.ModuleList()for idx,(depth,num_heads)inenumerate(zip(self.depths, self.num_heads)):
stage = SwinStage(dim=int(self.embed_dim *2**idx),
input_resolution=(self.patch_resolution[0]//(2** idx),
self.patch_resolution[0]//(2** idx)),
depth = depth,
num_heads = num_heads,
window_size = window_size,
patch_merging= PatchMerging if(idx < self.num_stages-1)elseNone)
self.stages.append(stage)
self.norm = nn.LayerNorm(self.num_features)
self.avgpool = nn.AdaptiveAvgPool1d(1)
self.fc = nn.Linear(self.num_features,self.num_classes)defforward(self, x):
x = self.patch_embedding(x)for stage in self.stages:
x = stage(x)
x = self.norm(x)
x = x.permute(0,2,1)# [B, embed_dim, num_windows]
x = self.avgpool(x)# [B, embed_dim, 1]
x = x.flatten(1)
x = self.fc(x)return x
最终main函数就将之前的整合进入 SwinStage中了
defmain():
t = torch.randn([4,3,224,224])# patch_embedding = PatchEmbedding(patch_size=4, embed_dim=96)# swin_block_w_msa = SwinBlock(dim=96, input_reslution=[56,56], num_heads=4, window_size=7,shift_size=0)# swin_block_sw_msa = SwinBlock(dim=96, input_reslution=[56,56], num_heads=4, window_size=7,shift_size=7//2)## patch_merging = PatchMerging(input_resolution=[56,56], dim=96)## print('image shape = [4, 3, 224, 224]')# out = patch_embedding(t) #[4, 56, 56, 96]# print('patch_embedding out shape= ',out.shape)# out = swin_block_w_msa(out)# out = swin_block_sw_msa(out)# print('swinBlock out shape= ',out.shape)# out = patch_merging(out)# print('patch_merging out shape= ',out.shape)
model = Swin()print(model)
out = model(t)print(out.shape)
输出结果如下
模型结构
Swin((patch_embedding): PatchEmbedding((patch_embed): Conv2d(3,96, kernel_size=(4,4), stride=(4,4))(norm): LayerNorm((96,), eps=1e-05, elementwise_affine=True))(stages): ModuleList((0): SwinStage((blocks): ModuleList((0): SwinBlock((attn_norm): LayerNorm((96,), eps=1e-05, elementwise_affine=True)(attn): WindowAttention((softmax): Softmax(dim=-1)(qkv): Linear(in_features=96, out_features=288, bias=True)(proj): Linear(in_features=96, out_features=96, bias=True))(mlp_norm): LayerNorm((96,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=96, out_features=384, bias=True)(fc2): Linear(in_features=384, out_features=96, bias=True)(act): GELU(approximate='none')(dropout): Dropout(p=0.0, inplace=False)))(1): SwinBlock((attn_norm): LayerNorm((96,), eps=1e-05, elementwise_affine=True)(attn): WindowAttention((softmax): Softmax(dim=-1)(qkv): Linear(in_features=96, out_features=288, bias=True)(proj): Linear(in_features=96, out_features=96, bias=True))(mlp_norm): LayerNorm((96,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=96, out_features=384, bias=True)(fc2): Linear(in_features=384, out_features=96, bias=True)(act): GELU(approximate='none')(dropout): Dropout(p=0.0, inplace=False))))(patch_merging): PatchMerging((reduction): Linear(in_features=384, out_features=192, bias=True)(norm): LayerNorm((384,), eps=1e-05, elementwise_affine=True)))(1): SwinStage((blocks): ModuleList((0): SwinBlock((attn_norm): LayerNorm((192,), eps=1e-05, elementwise_affine=True)(attn): WindowAttention((softmax): Softmax(dim=-1)(qkv): Linear(in_features=192, out_features=576, bias=True)(proj): Linear(in_features=192, out_features=192, bias=True))(mlp_norm): LayerNorm((192,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=192, out_features=768, bias=True)(fc2): Linear(in_features=768, out_features=192, bias=True)(act): GELU(approximate='none')(dropout): Dropout(p=0.0, inplace=False)))(1): SwinBlock((attn_norm): LayerNorm((192,), eps=1e-05, elementwise_affine=True)(attn): WindowAttention((softmax): Softmax(dim=-1)(qkv): Linear(in_features=192, out_features=576, bias=True)(proj): Linear(in_features=192, out_features=192, bias=True))(mlp_norm): LayerNorm((192,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=192, out_features=768, bias=True)(fc2): Linear(in_features=768, out_features=192, bias=True)(act): GELU(approximate='none')(dropout): Dropout(p=0.0, inplace=False))))(patch_merging): PatchMerging((reduction): Linear(in_features=768, out_features=384, bias=True)(norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)))(2): SwinStage((blocks): ModuleList((0): SwinBlock((attn_norm): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(attn): WindowAttention((softmax): Softmax(dim=-1)(qkv): Linear(in_features=384, out_features=1152, bias=True)(proj): Linear(in_features=384, out_features=384, bias=True))(mlp_norm): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=384, out_features=1536, bias=True)(fc2): Linear(in_features=1536, out_features=384, bias=True)(act): GELU(approximate='none')(dropout): Dropout(p=0.0, inplace=False)))(1): SwinBlock((attn_norm): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(attn): WindowAttention((softmax): Softmax(dim=-1)(qkv): Linear(in_features=384, out_features=1152, bias=True)(proj): Linear(in_features=384, out_features=384, bias=True))(mlp_norm): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=384, out_features=1536, bias=True)(fc2): Linear(in_features=1536, out_features=384, bias=True)(act): GELU(approximate='none')(dropout): Dropout(p=0.0, inplace=False)))(2): SwinBlock((attn_norm): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(attn): WindowAttention((softmax): Softmax(dim=-1)(qkv): Linear(in_features=384, out_features=1152, bias=True)(proj): Linear(in_features=384, out_features=384, bias=True))(mlp_norm): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=384, out_features=1536, bias=True)(fc2): Linear(in_features=1536, out_features=384, bias=True)(act): GELU(approximate='none')(dropout): Dropout(p=0.0, inplace=False)))(3): SwinBlock((attn_norm): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(attn): WindowAttention((softmax): Softmax(dim=-1)(qkv): Linear(in_features=384, out_features=1152, bias=True)(proj): Linear(in_features=384, out_features=384, bias=True))(mlp_norm): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=384, out_features=1536, bias=True)(fc2): Linear(in_features=1536, out_features=384, bias=True)(act): GELU(approximate='none')(dropout): Dropout(p=0.0, inplace=False)))(4): SwinBlock((attn_norm): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(attn): WindowAttention((softmax): Softmax(dim=-1)(qkv): Linear(in_features=384, out_features=1152, bias=True)(proj): Linear(in_features=384, out_features=384, bias=True))(mlp_norm): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=384, out_features=1536, bias=True)(fc2): Linear(in_features=1536, out_features=384, bias=True)(act): GELU(approximate='none')(dropout): Dropout(p=0.0, inplace=False)))(5): SwinBlock((attn_norm): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(attn): WindowAttention((softmax): Softmax(dim=-1)(qkv): Linear(in_features=384, out_features=1152, bias=True)(proj): Linear(in_features=384, out_features=384, bias=True))(mlp_norm): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=384, out_features=1536, bias=True)(fc2): Linear(in_features=1536, out_features=384, bias=True)(act): GELU(approximate='none')(dropout): Dropout(p=0.0, inplace=False))))(patch_merging): PatchMerging((reduction): Linear(in_features=1536, out_features=768, bias=True)(norm): LayerNorm((1536,), eps=1e-05, elementwise_affine=True)))(3): SwinStage((blocks): ModuleList((0): SwinBlock((attn_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(attn): WindowAttention((softmax): Softmax(dim=-1)(qkv): Linear(in_features=768, out_features=2304, bias=True)(proj): Linear(in_features=768, out_features=768, bias=True))(mlp_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=768, out_features=3072, bias=True)(fc2): Linear(in_features=3072, out_features=768, bias=True)(act): GELU(approximate='none')(dropout): Dropout(p=0.0, inplace=False)))(1): SwinBlock((attn_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(attn): WindowAttention((softmax): Softmax(dim=-1)(qkv): Linear(in_features=768, out_features=2304, bias=True)(proj): Linear(in_features=768, out_features=768, bias=True))(mlp_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=768, out_features=3072, bias=True)(fc2): Linear(in_features=3072, out_features=768, bias=True)(act): GELU(approximate='none')(dropout): Dropout(p=0.0, inplace=False))))(patch_merging): Indentity()))(norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(avgpool): AdaptiveAvgPool1d(output_size=1)(fc): Linear(in_features=768, out_features=1000, bias=True))
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DX11tzfw-1678713307022)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230312212834626.png)]](https://img-blog.csdnimg.cn/62487beaf6bd4757b7f240da2263d5fe.png)
3.2 数据加载
那我们正常情况需要从数据集中加载数据,那数据如何取呢?
首先看一下python的 for 循环在做什么
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zYeLn6cb-1678713307022)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230312213031925.png)]](https://img-blog.csdnimg.cn/ac517b24bdd5456ba39613453cca379f.png)
比如我想for循环遍历,那我应该怎么写MyInterable方法呢?
my_iterable = MyInterable()for d in my_iterable:print(d)
我们需要实现getitem类,来返回__getitem__对象,然后__getitem__中通过next方法来取值,如果想手动选择索引,在MyInterable中实现__getitem__方法
Dataset返回的是单个的样本,而Dataloader是返回一个batch的数据
查看下图,我们走一遍流程,for循环可以从dataloader中取数据,那它本质上调用了__iter__()方法,它其中其实就是调用了DataLoaderIter中__iter__()方法,其中有一个__next__()方法来取数据,next中又调用了fetch,fetch又从Sampler拿到indices,再去fetch data,之后再从Dataset中__getitem__()来数据。从 Dataset中取到的数据是list,需要通过collate_fn()帮我们把list变为tensor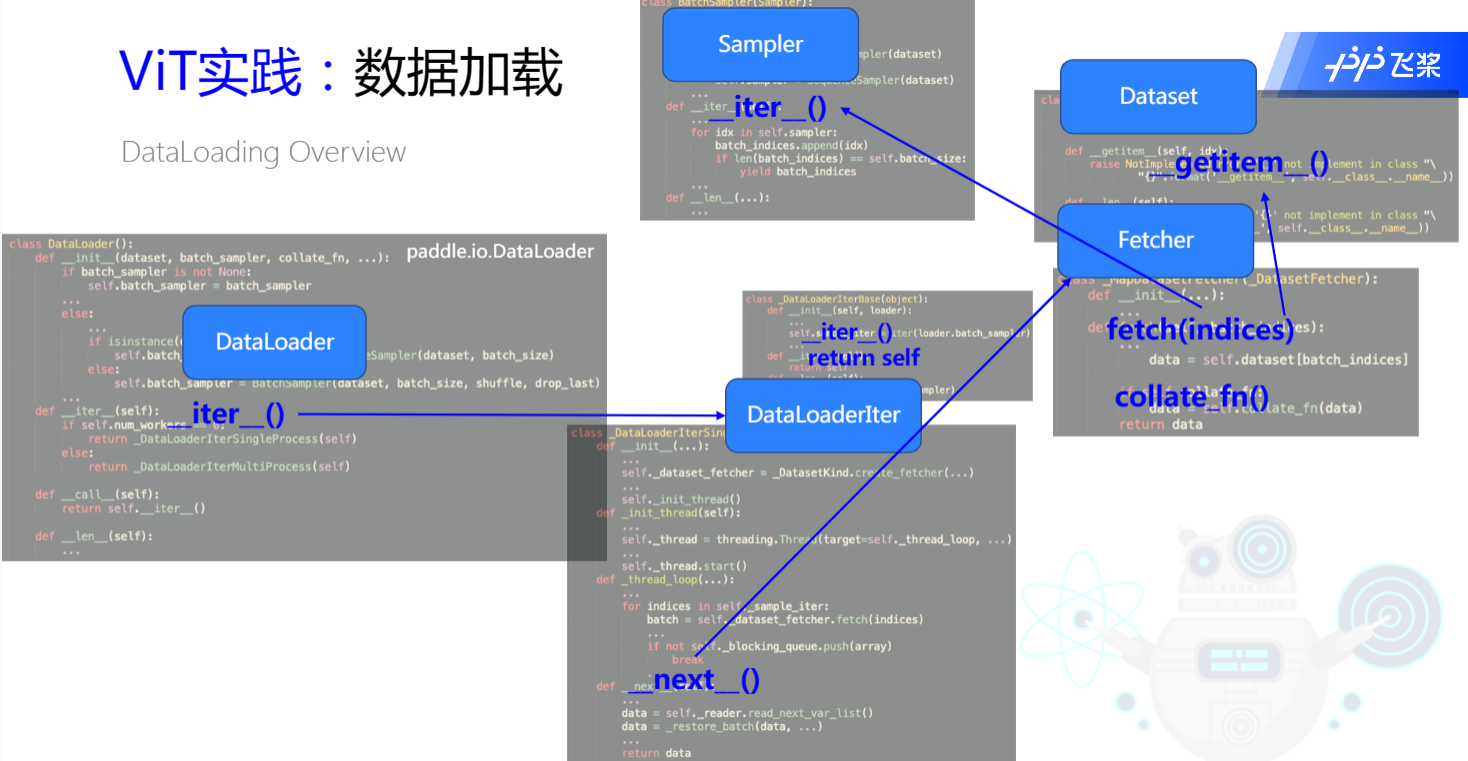
版权归原作者 Jorko的浪漫宇宙 所有, 如有侵权,请联系我们删除。