
Transformer目前大火,作为一个合格的算法搬运工自然要跟上潮流,本文基于tensorflow2框架,构建transformer模型,并将其用于多变量的风电功率负荷预测。 实验结果表明,相比与传统的LSTM,该方法精度更高,缺点也很明显,该方法需要更多的数据训练效果才能超过传统方法,而且占用很高的gpu资源(测试阶段,一次性输入所有测试集数据直接会OOM,需要分批输入),cpu就更慢了。
今天是2023年的第一天,首先总结一下2022的收获:

接着进入正题
1 Transformer网络结构
原始的transformer网络是用来的处理文本翻译这样的任务,输入=输出(输出是另一种形式的输出),所以原始的网络是先编码再解码的结构,数据进入网络进行编码器,得到隐含特征,然后利用解码器,将其还原成另外一种表达。而我们进行风电功率预测,由于我们的输入与输出不是同一个东西,所以我在网络中去掉了解码器,直接将编码器的输出作为提取的特征,然后接一个全连接层作为输出层,输出功率值。具体理解包括:输入层→编码器→输出层。
1.1 输入输出层
本文采用的数据形式如图1所示,数据含有6个特征,采用滚动序列建模的方法,生成输入数据与输出数据。具体为:设定输入时间步m与输出时间步n,然后取第1到m时刻的所有数据作为输入,取第m+1到第m+n时刻的实际发电功率作为输出,作为第一个样本;然后取第2到m+1时刻的所有数据作为输入,取第m+2到第m+n+1时刻的实际发电功率作为输出,作为第二个样本。。。依次类推,通过这种滚动的方法获得输入输出数据。当m取10,n取3时,则输入层的维度为[None,10,6],输出层的维度为[None,3],模型训练好后,只需要输入过去10个时刻的所有数据,就能预测得到未来3个时刻的发电功率预测值。
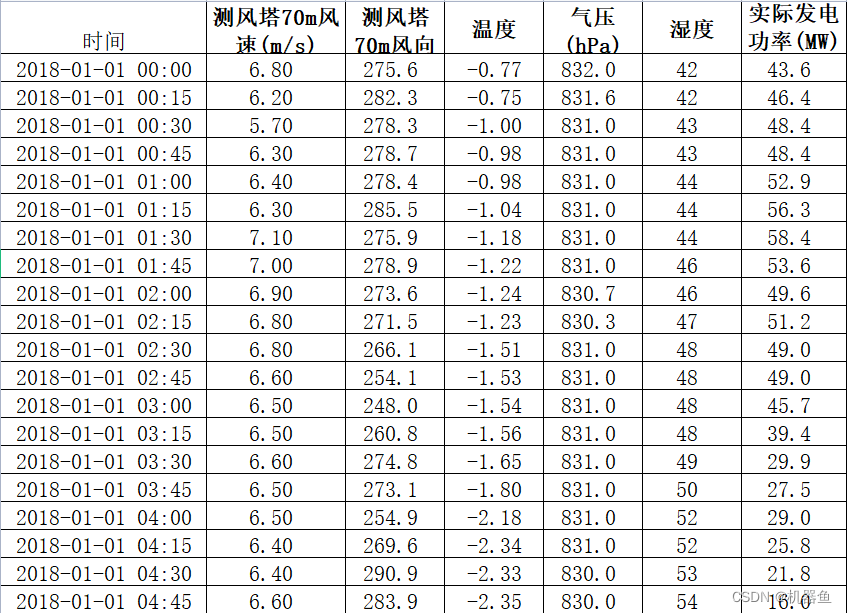
图1 数据结构
1.2 编码器
1.2.1 嵌入层
嵌入层实际上只是一个简单的全连接层,将原本维度变换到d_model,其目的有两个:1)对原始数据进行特征变换,原始只有6个特征,假设这些特征之间是有联系的,采用一个全连接层可以让特征之间进行交互,起到变换特征的作用;2)其次的是增加网络复杂度,为了后续使用多头自注意力机制,多头的数量必须与能被特征整除,打个比方,假如原始的6个特征变换到64个,然后就能用1、2、4、8、16、32、64头数,可选择性较高,如果只是6的话,就只能设置1、2、3,采用更多的头数可以增加网络复杂度,如果风电数据有几万条,网络过于简单无法有效的学习到这么长的序列的特征。
在程序中我将d_model设成16,则经过嵌入层之后的数据为:
d_model=16
embedding = tf.keras.layers.Dense(d_model)
x=np.random.rand(64,10,6)#64是batchsize 10是输入时间步 6是6个特征
y=embedding (x) #y的shape变成 64,10,16
1.2.2 位置编码
Transformer使用的是正余弦位置编码。位置编码通过使用不同频率的正弦、余弦函数生成,然后和对应的位置的输入向量(嵌入层的输出数据)相加,位置向量维度必须和词向量的维度一致

def get_angles(pos, i, d_model):
# 这里的i等价与公式中的2i和2i+1
angle_rates = 1 / np.power(10000, (2 * (i//2)) / np.float32(d_model))
return pos * angle_rates
def positional_encoding(maximum_position_encoding, d_model):
angle_rads = get_angles(np.arange(maximum_position_encoding)[:, np.newaxis], np.arange(d_model)[np.newaxis, :],d_model)
# apply sin to even indices in the array; 2i
angle_rads[:, 0::2] = np.sin(angle_rads[:, 0::2])
# apply cos to odd indices in the array; 2i+1
angle_rads[:, 1::2] = np.cos(angle_rads[:, 1::2])
pos_encoding = angle_rads[np.newaxis, ...]
return tf.cast(pos_encoding, dtype=tf.float32)
x=np.random.rand(64,10,16)
pos_enc=positional_encoding(5000, 16)
x +=pos_enc[:,x.shape[1],:] #x的shape还是[64,10,16]
1.2.3 self-attention自注意力机制
自注意力网络上很多解释,这里我们简单的理解一下计算步骤:通过嵌入层与位置编码后,我们的数据是64 x 10 x 16 其中64表示batchsize 10表示时间步 16为特征维度。如果我们想要获得第i个样本的input-1(每一个样本含10个input,每个input的维度是16)的输出,那么我们进行如下几步:
1、构建3个全连接层,每个维度都是d_model,输入input-1,分别得到3个变量,即Q、K、V,可以将QKV就理解成input-1的另一种表达;
1、利用input-1的Q,分别乘上input-1、input-2、....、input-16的K',此时我们获得了16个score。这个score,这就是相较于input-1、input-2、....、input-16,input-1的重要程度。
这里你会很奇怪为啥score就是input-1相较于其他input的重要程度。我的理解是:Q乘K'是点积。啥时点积?点积就是余弦相似度的分子,QK'近似等于余弦相似度,如果两个变量越相似,QK‘就越大;可推,如果一个变量最重要,那他可以近似代替其他变量,那他与其他变量的点积就会很大。(也可以理解成相关性,一样的推理)
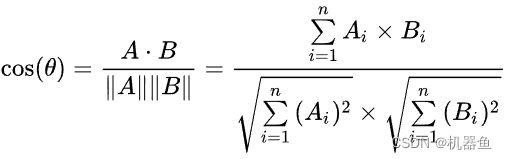
2、然后对这些score取softmax,归一化重要程度。
3、然后将这个重要程度乘上input-1、input-2、....、input-16的值向量,求和。
4、此时我们获得了input-1的输出。
1.2.4 多头注意力
多头注意力,可以理解为我们每个头只计算部分特征,比如第一个头只计算input-1到input-4,第二个头计算input-5到input-8,16个特征就是4个头。
1.2.5 编码器
编码器就是输入经嵌入层+位置编码+多头注意力层+多头注意力层+多头注意力层+...+多头注意力层,得到输出特征,然后输入一个全连接层,就能得到我们的输出
def scaled_dot_product_attention(q, k, v, mask):
"""Calculate the attention weights.
q, k, v must have matching leading dimensions.
k, v must have matching penultimate dimension, i.e.: seq_len_k = seq_len_v.
The mask has different shapes depending on its type(padding or look ahead)
but it must be broadcastable for addition.
Args:
q: query shape == (..., seq_len_q, depth)
k: key shape == (..., seq_len_k, depth)
v: value shape == (..., seq_len_v, depth_v)
mask: Float tensor with shape broadcastable to (..., seq_len_q, seq_len_k). Defaults to None.
Returns:
output, attention_weights
"""
matmul_qk = tf.matmul(q, k, transpose_b=True) # (..., seq_len_q, seq_len_k)
# scale matmul_qk
dk = tf.cast(tf.shape(k)[-1], tf.float32) ## 64
scaled_attention_logits = matmul_qk / tf.math.sqrt(dk)
# add the mask to the scaled tensor.
if mask is not None:
scaled_attention_logits = scaled_attention_logits + (mask * -1e9)
# softmax is normalized on the last axis (seq_len_k) so that the scores
# add up to 1.
attention_weights = tf.nn.softmax(scaled_attention_logits, axis=-1) # (..., seq_len_q, seq_len_k)
output = tf.matmul(attention_weights, v) # (..., seq_len_q, depth_v)
return output, attention_weights
class MultiHeadAttention(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.d_model = d_model
assert d_model % self.num_heads == 0# d_model self.num_heads 要能够整除
self.depth = d_model // self.num_heads
self.wq = tf.keras.layers.Dense(d_model)
self.wk = tf.keras.layers.Dense(d_model)
self.wv = tf.keras.layers.Dense(d_model)
self.dense = tf.keras.layers.Dense(d_model)
def split_heads(self, x, batch_size):
"""Split the last dimension into (num_heads, depth).
Transpose the result such that the shape is (batch_size, num_heads, seq_len, depth)
"""
x = tf.reshape(x, (batch_size, -1, self.num_heads, self.depth))
return tf.transpose(x, perm=[0, 2, 1, 3])
def call(self, v, k, q, mask):
batch_size = tf.shape(q)[0]
q = self.wq(q) # (batch_size, seq_len, d_model)
k = self.wk(k) # (batch_size, seq_len, d_model)
v = self.wv(v) # (batch_size, seq_len, d_model)
q = self.split_heads(q, batch_size) # (batch_size, num_heads, seq_len_q, depth)
k = self.split_heads(k, batch_size) # (batch_size, num_heads, seq_len_k, depth)
v = self.split_heads(v, batch_size) # (batch_size, num_heads, seq_len_v, depth)
# scaled_attention.shape == (batch_size, num_heads, seq_len_q, depth)
# attention_weights.shape == (batch_size, num_heads, seq_len_q, seq_len_k)
scaled_attention, attention_weights = scaled_dot_product_attention(q, k, v, mask)
scaled_attention = tf.transpose(scaled_attention, perm=[0, 2, 1, 3]) # (batch_size, seq_len_q, num_heads, depth)
concat_attention = tf.reshape(scaled_attention,
(batch_size, -1, self.d_model)) # (batch_size, seq_len_q, d_model)
output = self.dense(concat_attention) # (batch_size, seq_len_q, d_model)
return output, attention_weights
def point_wise_feed_forward_network(d_model, dff):
return tf.keras.Sequential([
tf.keras.layers.Dense(dff, activation='relu'), # (batch_size, seq_len, dff)
tf.keras.layers.Dense(d_model) # (batch_size, seq_len, d_model)
])
class EncoderLayer(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads, dff, rate=0.1):
super(EncoderLayer, self).__init__()
self.mha = MultiHeadAttention(d_model, num_heads)
self.ffn = point_wise_feed_forward_network(d_model, dff)
self.layernorm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = tf.keras.layers.Dropout(rate)
self.dropout2 = tf.keras.layers.Dropout(rate)
def call(self, x, training, mask):
attn_output, _ = self.mha(x, x, x, mask) # (batch_size, input_seq_len, d_model)
attn_output = self.dropout1(attn_output, training=training)
out1 = self.layernorm1(x + attn_output) # (batch_size, input_seq_len, d_model)
ffn_output = self.ffn(out1) # (batch_size, input_seq_len, d_model)
ffn_output = self.dropout2(ffn_output, training=training)
out2 = self.layernorm2(out1 + ffn_output) # (batch_size, input_seq_len, d_model)
return out2
class Encoder(tf.keras.layers.Layer):
def __init__(self, num_layers, d_model, num_heads, dff, input_vocab_size,
maximum_position_encoding, rate=0.1):
super(Encoder, self).__init__()
self.d_model = d_model
self.num_layers = num_layers
self.embedding = tf.keras.layers.Dense(d_model)
self.pos_encoding = positional_encoding(maximum_position_encoding, self.d_model)
self.enc_layers = [ EncoderLayer(d_model, num_heads, dff, rate) for _ in range(num_layers) ]
self.dropout = tf.keras.layers.Dropout(rate)
def call(self, x, training, mask):
seq_len = tf.shape(x)[1]
# adding embedding and position encoding.
x = self.embedding(x) # (batch_size, input_seq_len, d_model)
# print('------------------\n',seq_len)
# x=tf.tile(tf.expand_dims(x,2),self.d_model)
x *= tf.math.sqrt(tf.cast(self.d_model, tf.float32))
# print(x.shape)
x += self.pos_encoding[:, :seq_len, :]
x = self.dropout(x, training=training)
# print(x.shape)
# print(mask.shape)
for i in range(self.num_layers):
x = self.enc_layers[i](x, training, mask)
return x # (batch_size, input_seq_len, d_model)
2 实战
经过全面的分析,现在就可以训练网络了。
2.1 BP网
络
训练一个BP来做对比
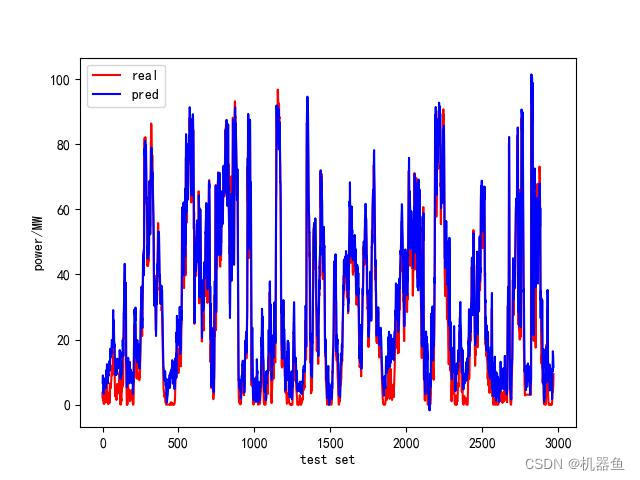
2.2 LSTM网络
训练一个LSTM来做对比

2.3 Transformer模型

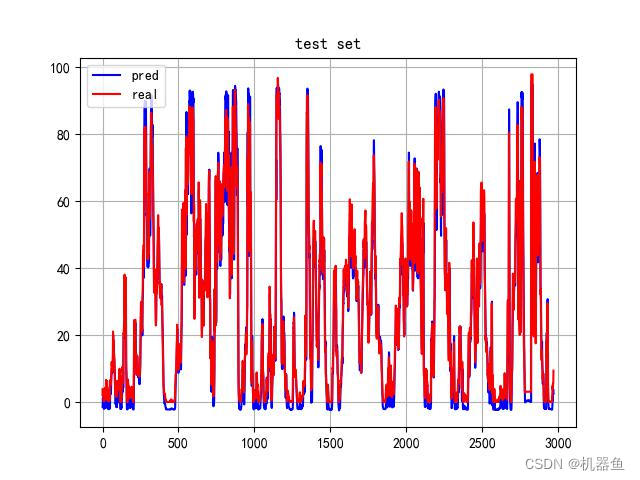
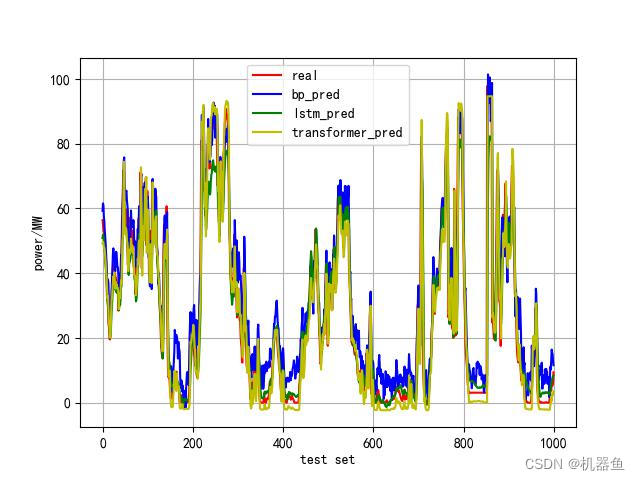
2.4 对比
就取1000个点来画图对比

3 代码
详细代码数据见评论区
本文转载自: https://blog.csdn.net/qq_41043389/article/details/128513767
版权归原作者 机器鱼 所有, 如有侵权,请联系我们删除。
版权归原作者 机器鱼 所有, 如有侵权,请联系我们删除。