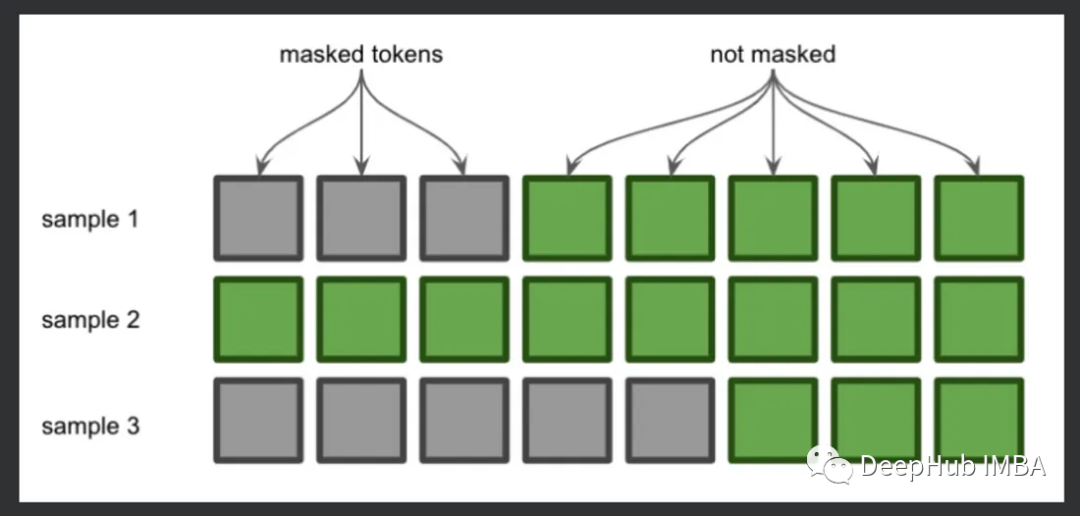
注意力机制中的掩码详解
本文将详细介绍掩码的原理和机制。
【Transformer开山之作】Attention is all you need原文解读
Attention Is All You NeedTransformer原文解读与细节复现在Transformer出现以前,深度学习的基础主流模型可分为卷积神经网络CNN、循环神经网络RNN、图对抗神经网络GAN。而Transformer的横空出世,吸引了越来越多的研究者的关注:Transforme
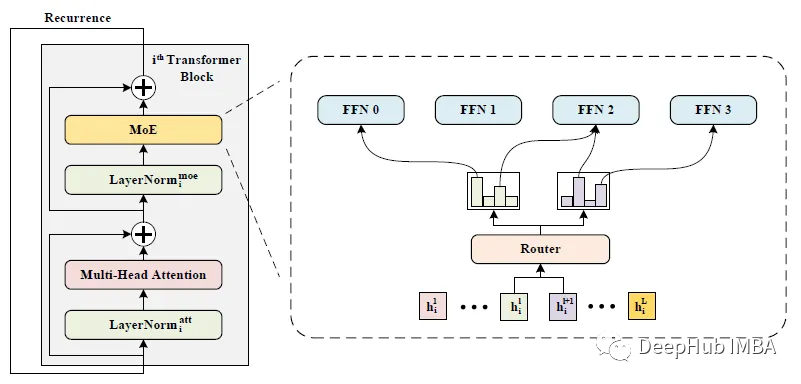
WideNet:让网络更宽而不是更深
这是新加坡国立大学在2022 aaai发布的一篇论文。WideNet是一种参数有效的框架,它的方向是更宽而不是更深。通过混合专家(MoE)代替前馈网络(FFN),使模型沿宽度缩放。使用单独LN用于转换各种语义表示,而不是共享权重。
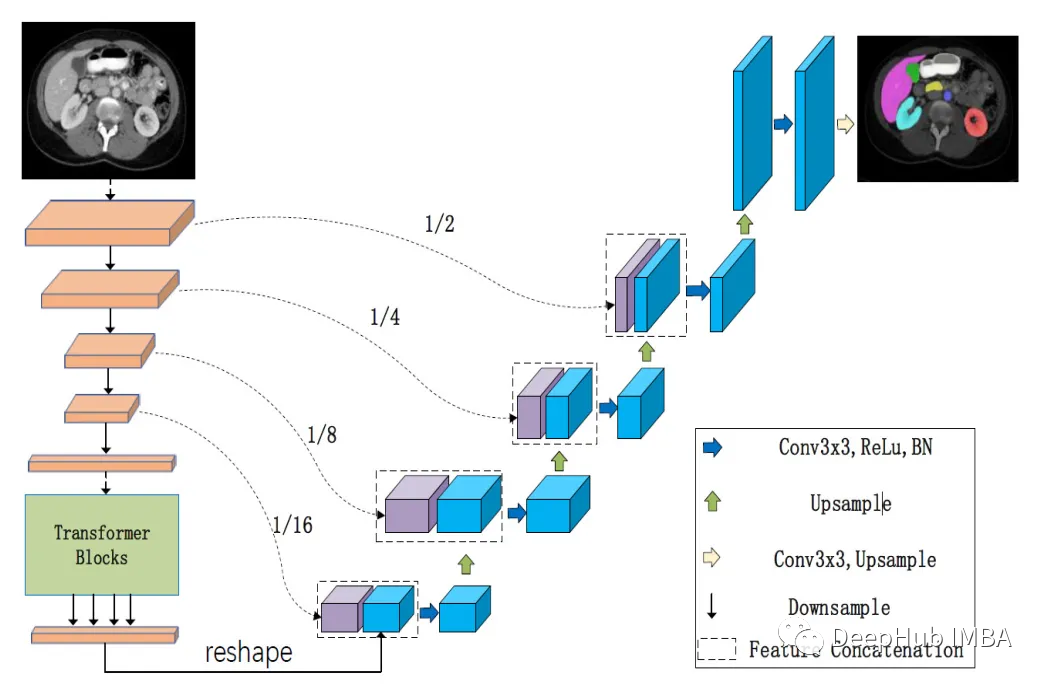
LeViT-UNet:transformer 编码器和CNN解码器的有效整合
levi - unet[2]是一种新的医学图像分割架构,它使用transformer 作为编码器,这使得它能够更有效地学习远程依赖关系。levi - unet[2]比传统的U-Nets更快,同时仍然实现了最先进的分割性能。
【人工智能与深度学习】注意力机制和Transformer
集合vectx1vectx1到vectxtvectxt通过编码器输入。使用自我注意和更多块,获得输出表示lbracevecthtextEncrbracei1tlbracevecthtextEncrbracei1t,该输出表示被馈送到解码器。在对其施加自注意力之后,进行交叉注意力。在此块中,查询
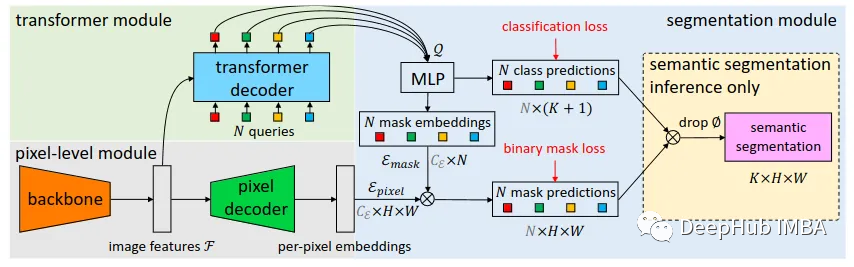
MaskFormer:将语义分割和实例分割作为同一任务进行训练
本文中将介绍Facebook AI Research在21年发布的一种超越这些限制的实例分割方法MaskFormer。

图解transformer中的自注意力机制
本文将将介绍注意力的概念从何而来,它是如何工作的以及它的简单的实现。
Transformer详解(李沐大神文字版,干货满满!)
使用图和文字记录下了李沐大神的Transformer论文逐段精度视频,方便大家后续快速复习。
学习笔记:基于Transformer的时间序列预测模型
基于Transformer的时间序列预测
[自注意力神经网络]Segment Anything(SAM)论文阅读
SAM网络学习笔记
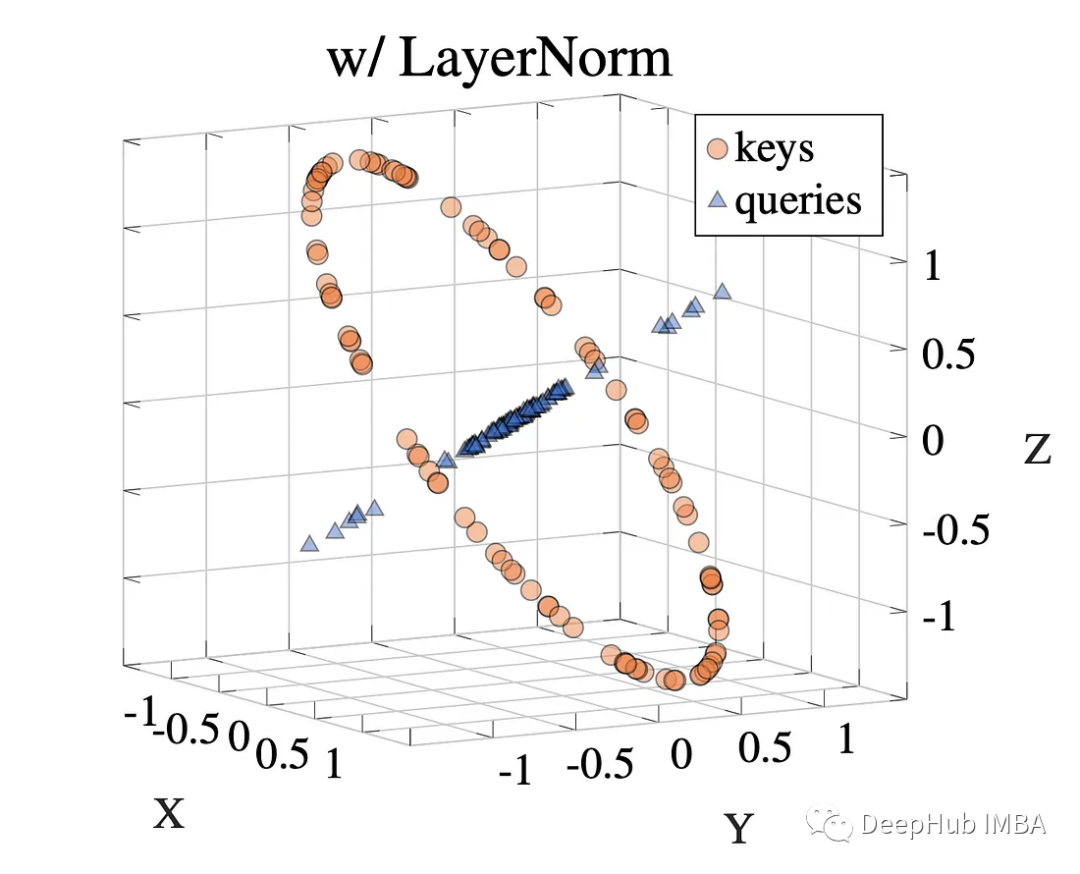
LayerNorm 在 Transformers 中对注意力的作用研究
LayerNorm 一直是 Transformer 架构的重要组成部分。如果问大多人为什么要 LayerNorm,一般的回答是:使用 LayerNorm 来归一化前向传播的激活和反向传播的梯度。
什么是注意力机制及其应用(self attention)?
注意力机制是自深度学习快速发展后广泛应用于自然语言处理、统计学习、图像检测、语音识别等领域的核心技术,例如将注意力机制与RNN结合进行图像分类,将注意力机制运用在自然语言处理中提高翻译精度,注意力机制本质上说就是实现信息处理资源的高效分配,例如先关注场景中的一些重点,剩下的不重要的场景可能会被暂时性
Transformer简介
transformer模型简介,包括编码器(encoder)、解码器(decoder)、训练以及模型训练中的tips。
Swin Transformer之相对位置编码详解
Swin Transformer中非常核心之一即为相对位置编码,在此我将试图将其掰开了揉碎了进行讲解,尽可能以比较形象的方式进行理解。
类ChatGPT逐行代码解读(1/2):从零起步实现Transformer、ChatGLM-6B
transformer强大到什么程度呢,基本是17年之后绝大部分有影响力模型的基础架构都基于的transformer(比如,有200来个,包括且不限于基于decode的GPT、基于encode的BERT、基于encode-decode的T5等等)通过博客内的这篇文章《》,我们已经详细了解了trans
图像融合、Transformer、扩散模型
包大人说:“图像融合遇见Transformer,还是Transformer遇见图像融合?哪个更为贴切?”元芳回答:‘’都合适。‘’
涨点技巧:注意力机制---Yolov5/Yolov7引入BoTNet Transformer、MHSA
BoTNet同时使用卷积和自注意力机制,即在ResNet的最后3个bottleneck blocks中使用全局多头自注意力(MHSA)替换3 × 3空间卷积;MHSA作为注意力机制加入yolov5/yolov7也取得了涨点
Transformer中的Q/K/V理解
详细解释了Transformer中的Q/K/V矩阵的作用和意义。
Informer:比Transformer更有效的长时间序列预测
目录AAAI 2021最佳论文:比Transformer更有效的长时间序列预测BackgroundWhy attentionMethods:the details of InformerSolve_Challenge_1:最基本的一个思路就是降低Attention的计算量,仅计算一些非常重要的或者说
Transformer模型入门详解及代码实现
本文对Transformer模型的基本原理做了入门级的介绍,意在为读者描述整体思路,而并非拘泥于细微处的原理剖析,并附上了基于PYTORCH实现的Transformer模型代码及详细讲解。



