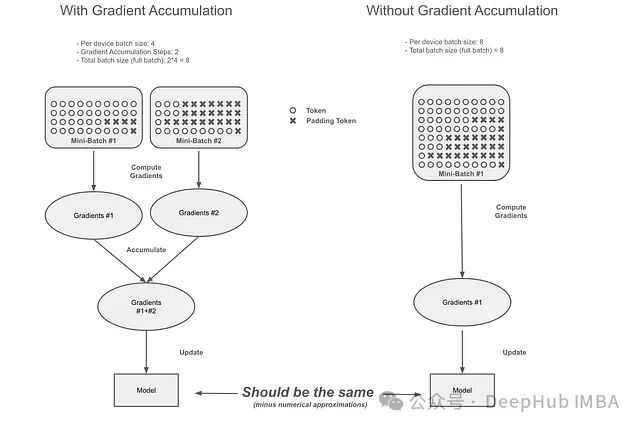
梯度累积的隐藏陷阱:Transformer库中梯度累积机制的缺陷与修正
本文将从以下几个方面展开讨论:首先阐述梯度累积的基本原理,通过实例说明问题的具体表现和错误累积过程;其次分析不同训练场景下该问题的影响程度;最后评估Unsloth提出并已被Hugging Face在Transformers框架中实现的修正方案的有效性。
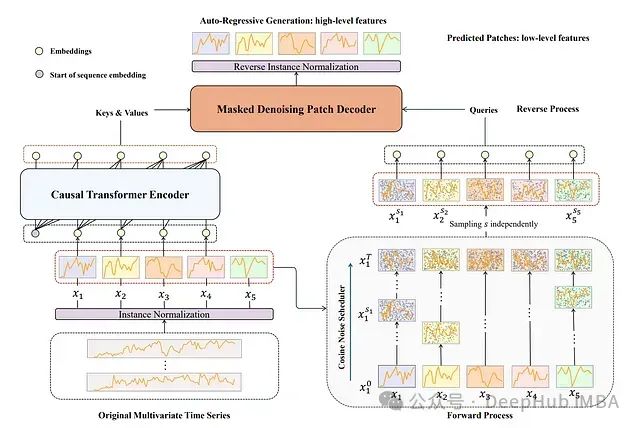
TimeDART:基于扩散自回归Transformer 的自监督时间序列预测方法
TimeDART是一种专为**时间序列预测**设计的自**监督学习**方法。它的核心思想是通过从时间序列历史数据中学习模式来改进未来数据点的预测。
【AI学习】Mamba学习(二):线性注意力
Softmax 注意力的问题是,Softmax是非线性的函数,如果没有 Softmax,那么就是三个矩阵 (query・key)・value 连乘 ,而矩阵乘法满足结合率,可以调整为调整为 query・(key・value)。 (query・key)得到是n✖n的矩阵,(key・value)得到的是
【AI大模型】深入Transformer架构:输入和输出部分的实现与解析
因为在Transformer的编码器结构中, 并没有针对词汇位置信息的处理,因此需要在Embedding层后加入位置编码器,将词汇位置不同可能会产生不同语义的信息加入到词嵌入张量中, 以弥补位置信息的缺失.
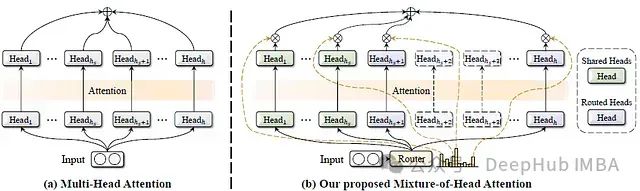
MoH:融合混合专家机制的高效多头注意力模型及其在视觉语言任务中的应用
这篇论文提出了一种名为混合头注意力(Mixture-of-Head attention, MoH)的新架构,旨在提高注意力机制的效率,同时保持或超越先前的准确性水平。
Vit transformer中class token作用
因为transformer输入为一系列的patch embedding,输出也是同样长的序列patch feature,但是最后要总结为一个类别的判断,简单方法可以用avg pool,把所有的patch feature都考虑算出image feature。其中训练的时候,class token的em
Liquid AI与液态神经网络:超越Transformer的大模型架构探索
自2017年谷歌发表了开创性的论文《Attention Is All You Need》以来,基于Transformer架构的模型迅速成为深度学习领域的主流选择。然而,随着技术的发展,挑战Transformer主导地位的呼声也逐渐高涨。最近,由麻省理工学院(MIT)计算机科学与人工智能实验室(CSA
【AI大模型】深入Transformer架构:解码器部分的实现与解析
由N个解码器层堆叠而成每个解码器层由三个子层连接结构组成第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接第二个子层连接结构包括一个多头注意力子层和规范化层以及一个残差连接第三个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接说明:解码器层中的各个部分,如,多头注意力机
医学图像分割,Transformer+UNet的14种融合方法
在此框架内,Cross Transformer 模块采用可扩展采样来计算两种模态之间的结构关系,从而重塑一种模态的结构信息,以与 Swin Transformer 同一局部窗口内两种模态的相应结构保持一致。在编码器中,输入的MRI扫描X∈RC×H×W×D,具有C个通道(模态),H×W的空间分辨率和D
【AI小项目4】用Pytorch从头实现Transformer(详细注解)
阅读Transformer论文并用Pytorch从头实现了简单的Transformer模型

三种Transformer模型中的注意力机制介绍及Pytorch实现:从自注意力到因果自注意力
本文深入探讨Transformer模型中三种关键的注意力机制:自注意力、交叉注意力和因果自注意力。我们不仅会讨论理论概念,还将使用Python和PyTorch从零开始实现这些注意力机制。
LYT-Net——轻量级YUV Transformer 网络低光照条件图像修复
低光照图像增强(LLIE)是计算机视觉(CV)领域的一个重要且具有挑战性的任务。在低光照条件下捕获图像会显著降低其质量,导致细节和对比度的丧失。这种退化不仅会导致主观上不愉快的视觉体验,还会影响许多CV系统的性能。LLIE的目标是在提高可见度和对比度的同时,恢复暗环境中固有的各种失真。低光照条件指的
【AI大模型】深入Transformer架构:编码器部分的实现与解析(下)
在Transformer中前馈全连接层就是具有两层线性层的全连接网络。前馈全连接层的作用是考虑注意力机制可能对复杂过程的拟合程度不够, 通过增加两层网络来增强模型的能力.
基于CKKS的非交互式安全Transformer推理实现
随着ChatGPT的普及,安全transformer推理已经成为一个突出了研究主题。已有的解决方法通常是交互式的,涉及到客户端和服务端之间大量的通信负载和交互轮次。本文提出NEXUS,这是第一个用于安全transformer推理的非交互式协议,其中客户端仅需要提交一个加密输入,然后等待来自服务器的加
3D生成技术再创新高:VAST发布Tripo 2.0,提升AI 3D生成新高度
随着《黑神话·悟空》的爆火,3D游戏背后的AI 3D生成技术也逐渐受到更多的关注。虽然3D大模型的热度相较于语言模型和视频生成技术稍逊一筹,但全球的3D大模型玩家们却从未放慢脚步。无论是a16z支持的Yellow,还是李飞飞创立的World Labs,3D大模型的迭代速度一直在稳步前进。近日,国内3
【AI大模型】深入Transformer架构:编码器部分的实现与解析(上)
编码器部分:* 由N个编码器层堆叠而成 * 每个编码器层由两个子层连接结构组成 * 第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接 * 第二个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接掩代表遮掩,码就是我们张量中的数值,它的尺寸不定,里面一般只有1和0的元素,
浅谈人工智能与大模型
随着科技的飞速发展,人工智能(Artificial Intelligence,简称AI)已经成为了我们生活中不可或缺的一部分。人工智能是指通过计算机程序或机器来模拟、扩展和增强人类的智能行为。而大模型通常是指那些规模庞大、参数众多的机器学习模型,它们能够处理复杂任务,并在学习过程中表现出卓越的性能。
AI:292-将CSWinTransformer集成到YOLOv8中 | 改进与应用分析
YOLOv8 是 YOLO(You Only Look Once)系列的最新版本,继承了 YOLO 系列的优良传统,致力于实现快速且准确的目标检测。YOLOv8 在网络架构、特征提取和检测精度等方面进行了优化,进一步提高了检测性能。然而,随着目标检测需求的不断增长,进一步提升 YOLOv8 的性能仍
30_Swin-Transformer网络结构详解
https://www.bilibili.com/video/BV1pL4y1v7jC/?spm_id_from=333.999.0.0&vd_source=7dace3632125a1ef7fd32c285eb2fbac
[开源] 基于transformer的时间序列预测模型python代码
分享一下基于transformer的时间序列预测模型python代码,给大家,记得点赞哦更多时间序列预测代码:时间序列预测算法全集合--深度学习



