transformer.js(一):这个前端大模型运行框架的可运行环境、使用方式、代码示例以及适合与不适合的场景
Transformer.js 是一个基于 JavaScript 的前端机器学习框架,专注于在浏览器中运行 Transformer 模型。它利用现代 Web 技术(如 WebAssembly 和 WebGPU)提供硬件加速,帮助开发者在前端环境中高效加载和推理深度学习模型,而无需依赖后端服务器。核心优
sliding window attention
同时,这种方式并不是意味着当前token只能获取到前window_size个token的信息,因为当前token前面的window_size个token也都是能够获取到前面的信息的,因此只要网络达到一定的深度,这样的sliding window attention是可行的,并不会损失太多信息。sli
前端大模型入门:Transformer.js 和 Xenova-引领浏览器端的机器学习变革
通过学会Transformer.js 和 Xenova系列模型,学会如何在网页中运行大模型吧
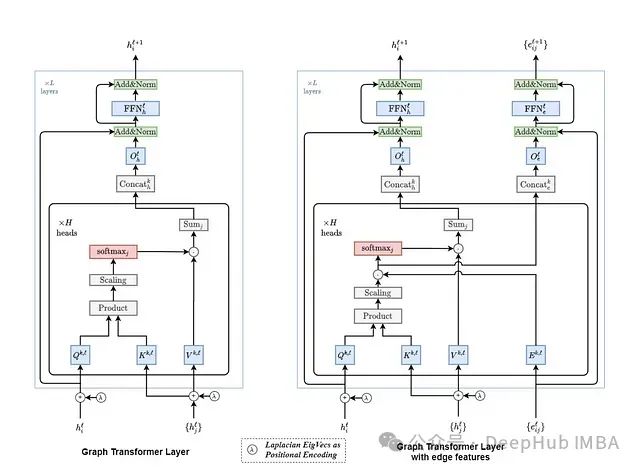
深入解析图神经网络:Graph Transformer的算法基础与工程实践
本文不仅是对Graph Transformer技术的深入解析,更是一份从理论到实践的完整技术指南,为那些希望在图神经网络领域深入发展的技术人员提供了宝贵的学习资源。
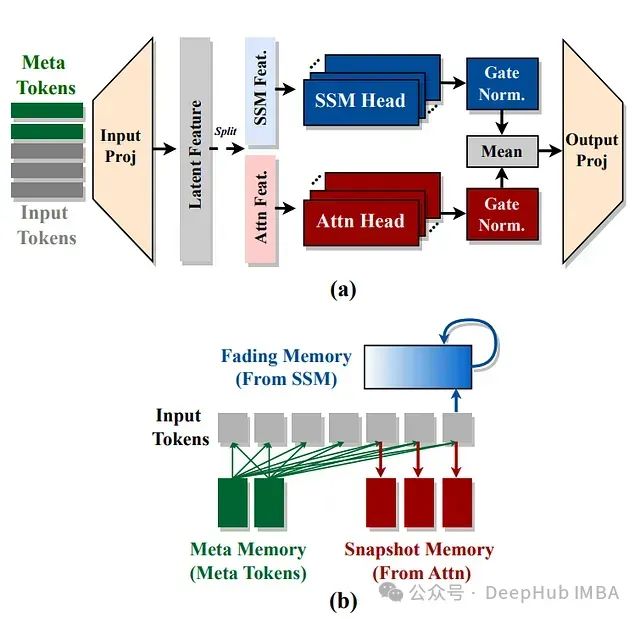
Hymba: 结合注意力头和SSM头的创新型语言模型方案
NVIDIA提出了Hymba架构,通过在同一层中结合注意力头和SSM头,以实现两种架构优势的互补。
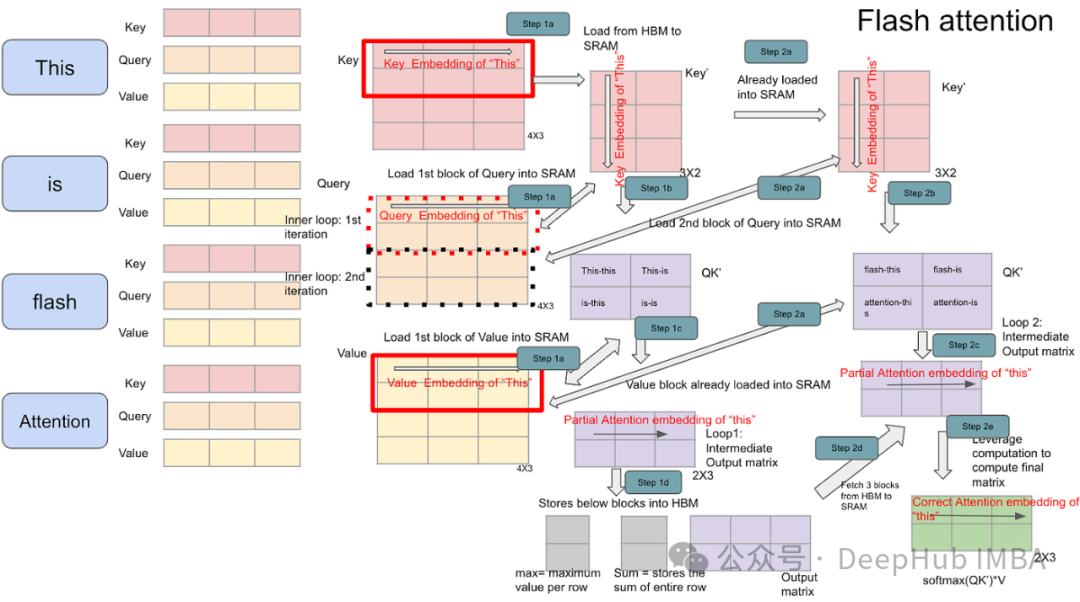
Transformer模型变长序列优化:解析PyTorch上的FlashAttention2与xFormers
本文将进一步探讨变长输入序列这一挑战——这是真实世界数据(如文档、代码、时间序列等)的固有特征。
顶会新热门:小波变换×Transformer,效率翻倍的AI图像去噪神奇组合
小波变换与Transformer的结合主要探讨如何利用小波变换的多尺度特性来增强Transformer在处理信号和图像数据时的表现。具体来说,小波变换能够有效提取信号中的局部特征,并在时间和频率域上提供信息,这对于处理复杂的信号(如图像和音频)非常有用。结合小波变换的Transformer可以在保持
OPT 大语言模型(Large Language Model)结构
大语言模型follow GPT的做法,其基本组成结构是Decoder-only的Transformer block,多个Transformer Block堆叠在一起;不同数量、不同Head、不同隐藏层维度构成了不同参数量的大模型(也即模型跟着的后缀,比如,6.7B);预训练模型参数的数据类型(大模型
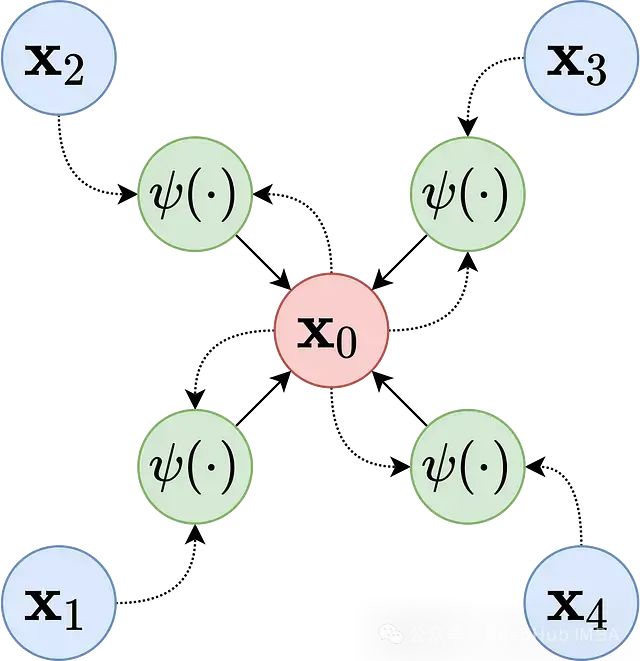
图神经网络在欺诈检测与蛋白质功能预测中的应用概述
本文将深入探讨GNNs在欺诈检测和生物信息学领域的应用机制与技术原理。
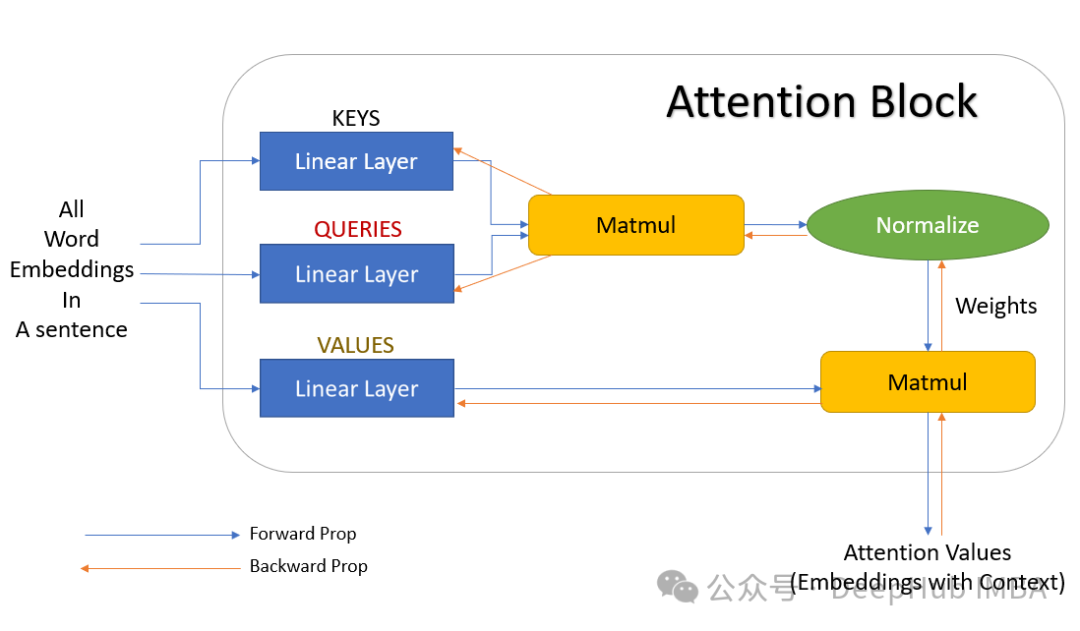
优化注意力层提升 Transformer 模型效率:通过改进注意力机制降低机器学习成本
本文将深入探讨在 PyTorch 生态系统中优化注意力层的多种技术路径,并将重点聚焦于那些在降低计算成本的同时能够保持注意力层精度的创新方法。
【AI大模型】ELMo模型介绍:深度理解语言模型的嵌入艺术
ELMo是2018年3月由华盛顿大学提出的一种预训练模型.ELMo的全称是Embeddings from Language Models.ELMo模型的提出源于论文。
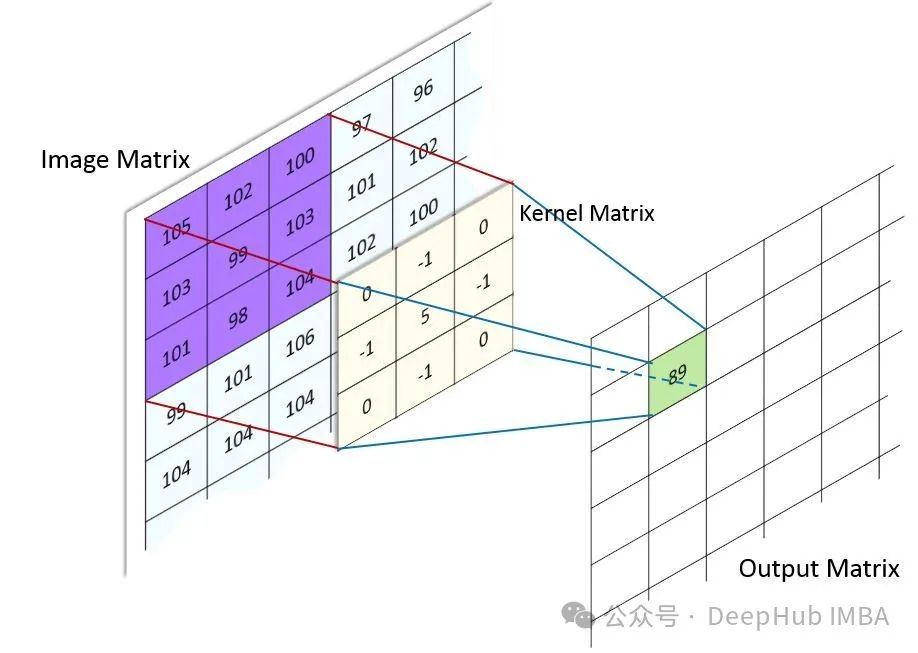
为什么卷积现在不火了:CNN研究热度降温的深层原因分析
纵观近年的顶会论文和研究热点,我们不得不承认一个现实:CNN相关的研究论文正在减少,曾经的"主角"似乎正逐渐淡出研究者的视野。
Audio Spectrogram Transformer (AST)工作介绍
Audio Spectrogram Transformer (AST),是一种基于 Transformer 模型的音频分类方法。AST 利用了 Transformer 模型在捕获全局特征方面的优势,将音频信号转换为频谱图进行处理。本文是对 AST 及其相关研究工作的详细介绍。
Tokenformer:基于参数标记化的高效可扩展Transformer架构
本文是对发表于arXiv的论文 “TOKENFORMER: RETHINKING TRANSFORMER SCALING WITH TOKENIZED MODEL PARAMETERS” 的深入解读与扩展分析。主要探讨了一种革新性的Transformer架构设计方案,该方案通过参数标记化实现了模型的
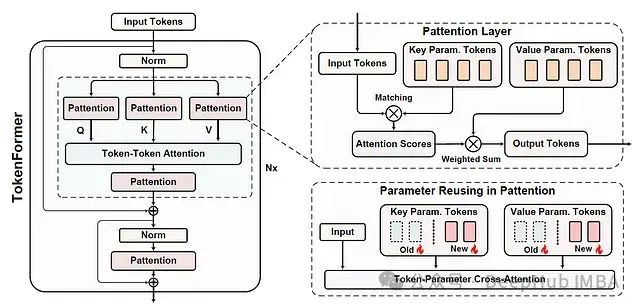
Tokenformer:基于参数标记化的高效可扩展Transformer架构
本文是对发表于arXiv的论文 "TOKENFORMER: RETHINKING TRANSFORMER SCALING WITH TOKENIZED MODEL PARAMETERS" 的深入解读与扩展分析。
论文研读:TransMorph—用于无监督医学图像配准的Transformer
在过去,卷积神经网络(ConvNets)一直是医学图像分析领域的研究热点。但是它的缺点是很少关注图像中的远程空间关系。最近,人们提出Transformer来解决ConvNet的缺点,并在许多医学成像应用中产生了最先进的性能,因为其大得多的感受野能够更精确地理解运动图像和固定图像之间的空间对应关系。在
【AI大模型】Transformer模型构建指南:轻松掌握核心技术
通过本专栏的博文,我们已经完成了所有组成部分的实现, 接下来就来实现完整的编码器-解码器结构. 接着将基于以上结构构建用于训练的模型.🍔 Tansformer模型构建过程的代码分析 nn.init.xavier_uniform演示:🍔 小结 学习并实现了编码器-解码器结
【代码复现训练】Vision Transformer(ViT)
尝试使用ViT做一个简单的花卉分类任务,默认使用ViT-B/16模型
AI大模型系列之七:Transformer架构讲解
Transformer模型设计之初,用于解决机器翻译问题,是完全基于注意力机制构建的编码器-解码器架构,编码器和解码器均由若干个具有相同结构的层叠加而成,每一层的参数不同。编码器主要负责将输入序列转化为一个定长的向量表示,解码器则将这个向量解码为输出序列。Transformer总体架构可分为四个部分
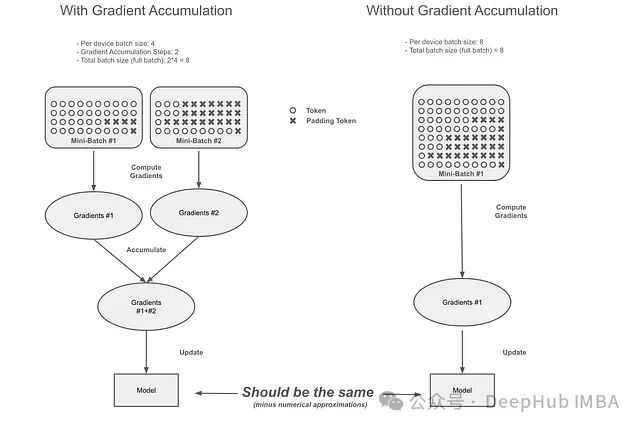
梯度累积的隐藏陷阱:Transformer库中梯度累积机制的缺陷与修正
本文将从以下几个方面展开讨论:首先阐述梯度累积的基本原理,通过实例说明问题的具体表现和错误累积过程;其次分析不同训练场景下该问题的影响程度;最后评估Unsloth提出并已被Hugging Face在Transformers框架中实现的修正方案的有效性。



