

交叉验证(也称为“过采样”技术)是数据科学项目的基本要素。它是一种重采样过程,用于评估机器学习模型并访问该模型对独立测试数据集的性能。
在本文中,您可以阅读以下大约8种不同的交叉验证技术,各有其优缺点:
- Leave p out cross-validation
- Leave one out cross-validation
- Holdout cross-validation
- Repeated random subsampling validation
- k-fold cross-validation
- Stratified k-fold cross-validation
- Time Series cross-validation
- Nested cross-validation
在介绍交叉验证技术之前,让我们知道为什么在数据科学项目中应使用交叉验证。
为什么交叉验证很重要?
我们经常将数据集随机分为训练数据和测试数据,以开发机器学习模型。训练数据用于训练ML模型,同一模型在独立的测试数据上进行测试以评估模型的性能。
随着分裂随机状态的变化,模型的准确性也会发生变化,因此我们无法为模型获得固定的准确性。测试数据应与训练数据无关,以免发生数据泄漏。在使用训练数据开发ML模型的过程中,需要评估模型的性能。这就是交叉验证数据的重要性。
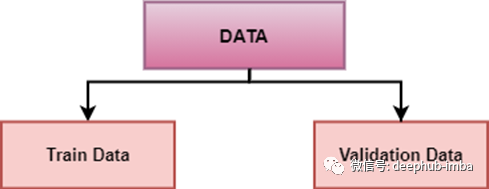
数据需要分为:
- 训练数据:用于模型开发
- 验证数据:用于验证相同模型的性能
简单来说,交叉验证使我们可以更好地利用我们的数据。
1.Leave p-out cross-validation
LpOCV是一种详尽的交叉验证技术,涉及使用p观测作为验证数据,而其余数据则用于训练模型。以所有方式重复此步骤,以在p个观察值的验证集和一个训练集上切割原始样本。
已推荐使用p = 2的LpOCV变体(称为休假配对交叉验证)作为估计二进制分类器ROC曲线下面积的几乎无偏的方法。
2. Leave-one-out cross-validation
留一法交叉验证(LOOCV)是一种详尽的穷尽验证技术。在p = 1的情况下,它是LpOCV的类别。
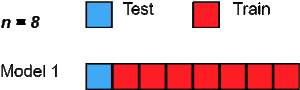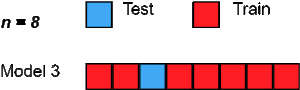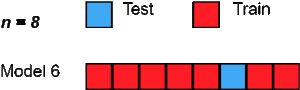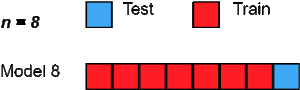
对于具有n行的数据集,选择第1行进行验证,其余(n-1)行用于训练模型。对于下一个迭代,选择第2行进行验证,然后重置来训练模型。类似地,这个过程重复进行,直到n步或达到所需的操作次数。
以上两种交叉验证技术都是详尽交叉验证的类型。穷尽性交叉验证方法是交叉验证方法,以所有可能的方式学习和测试。他们有相同的优点和缺点讨论如下:
优点:简单,易于理解和实施
缺点:该模型可能会导致较低的偏差、所需的计算时间长
3.Holdout cross-validation
保留技术是一种详尽的交叉验证方法,该方法根据数据分析将数据集随机分为训练数据和测试数据。
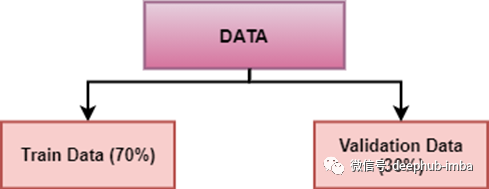
在保留交叉验证的情况下,数据集被随机分为训练和验证数据。通常,训练数据的分割不仅仅是测试数据。训练数据用于推导模型,而验证数据用于评估模型的性能。
用于训练模型的数据越多,模型越好。对于保留交叉验证方法,需要从训练中隔离大量数据。
优点:和以前一样,简单,易于理解和实施
缺点:不适合不平衡数据集、许多数据与训练模型隔离
4. k-fold cross-validation
在k折交叉验证中,原始数据集被平均分为k个子部分或折叠。从k折或组中,对于每次迭代,选择一组作为验证数据,其余(k-1)个组选择为训练数据。

该过程重复k次,直到将每个组视为验证并保留为训练数据为止。
模型的最终精度是通过获取k模型验证数据的平均精度来计算的。
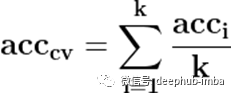
LOOCV是k折交叉验证的变体,其中k = n。
优点:
- 该模型偏差低
- 时间复杂度低
- 整个数据集可用于训练和验证
缺点:不适合不平衡数据集。
5. Repeated random subsampling validation
重复的随机子采样验证(也称为蒙特卡洛交叉验证)将数据集随机分为训练和验证。数据集的k倍交叉验证不太可能分成几类,而不是成组或成对,而是在这种情况下随机地成组。
迭代次数不是固定的,而是由分析决定的。然后将结果平均化。
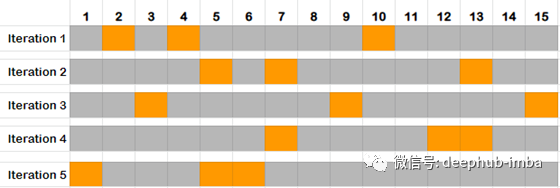
重复随机二次抽样验证
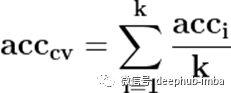
优点:训练和验证拆分的比例不取决于迭代或分区的数量
缺点:某些样本可能无法选择用于训练或验证、不适合不平衡数据集
6. Stratified k-fold cross-validation
对于上面讨论的所有交叉验证技术,它们可能不适用于不平衡的数据集。分层k折交叉验证解决了数据集不平衡的问题。
在分层k倍交叉验证中,数据集被划分为k个组或折叠,以使验证数据具有相等数量的目标类标签实例。这样可以确保在验证或训练数据中不会出现一个特定的类,尤其是在数据集不平衡时。
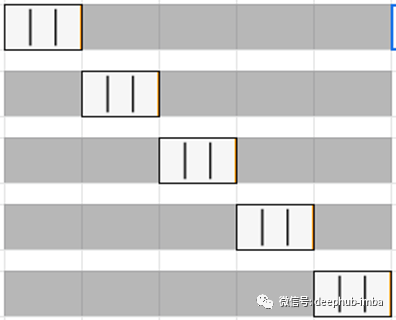
分层k折交叉验证,每折具有相等的目标类实例
最终分数是通过取各折分数的平均值来计算的
优点:对于不平衡的数据集,效果很好。
缺点:现在适合时间序列数据集。
7. Time Series cross-validation
数据的顺序对于与时间序列相关的问题非常重要。对于与时间相关的数据集,将数据随机拆分或k折拆分为训练和验证可能不会产生良好的结果。
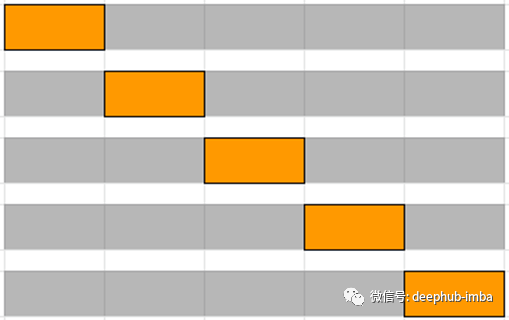
对于时间序列数据集,根据时间将数据分为训练和验证,也称为前向链接方法或滚动交叉验证。对于特定的迭代,可以将训练数据的下一个实例视为验证数据。
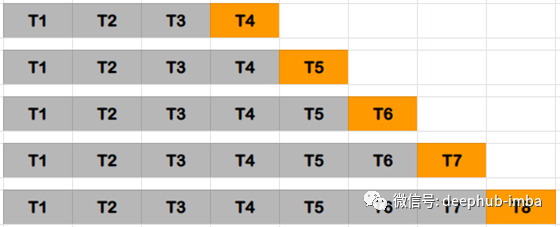
如上图所述,对于第一个迭代,第一个3行被视为训练数据,下一个实例T4是验证数据。选择训练和验证数据的机会将被进一步迭代。
8. Nested cross-validation
在进行k折和分层k折交叉验证的情况下,我们对训练和测试数据中的错误估计差。超参数调整是在较早的方法中单独完成的。当交叉验证同时用于调整超参数和泛化误差估计时,需要嵌套交叉验证。
嵌套交叉验证可同时应用于k折和分层k折变体。
结论
交叉验证用于比较和评估ML模型的性能。在本文中,我们介绍了8种交叉验证技术及其优缺点。k折和分层k折交叉验证是最常用的技术。时间序列交叉验证最适合与时间序列相关的问题。
这些交叉验证的实现可以在sklearn包中找到。有兴趣的读者可以阅读sklearn文档以获取更多详细信息。
https://scikit-learn.org/stable/modules/cross_validation.html
作者:Satyam Kumar
deephub翻译组