
在本篇文章中,我将概述如何使用卷积神经网络构建可靠的图像分类模型,以便从胸部x光图像中检测肺炎的存在。
肺炎是一种常见的感染,它使肺部的气囊发炎,引起呼吸困难和发烧等症状。尽管肺炎并不难治疗,但及时诊断是至关重要的。如果没有适当的治疗,肺炎可能会致命,特别是在儿童和老年人中。胸部x光检查是诊断肺炎的一种负担得起的方法。开发一种能够可靠地根据x光图像对肺炎进行分类的模型,可以减轻需求高的地区医生的负担。
数据
Kermany和他在加州大学圣迭戈分校的同事们在使用深度学习的胸部x光和光学相干断层扫描的基础上,主动识别疾病。我们使用他们研究中提供的胸部x光图像作为我们的数据集。
https://data.mendeley.com/datasets/rscbjbr9sj/3
数据结构
数据文件夹的结构应该如下所示。
DATA
│
├── train
│ ├── NORMAL
│ └── PNEUMONIA
│
├── test
│ ├── NORMAL
│ └── PNEUMONIA
│
└── validation
├── NORMAL
└── PNEUMONIA
在删除未经过正确编码的图像文件后,我们的数据集中有5639个文件,我们使用这些图像中的15%作为验证集,另外15%作为测试集。我们最终的训练集包括1076例正常病例和2873例肺炎病例。
数据探索
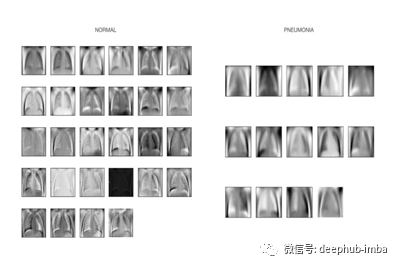
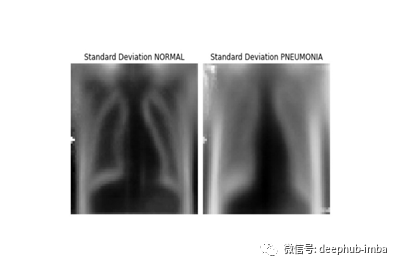
我们的探索性数据可视化显示,肺部的炎症经常阻碍心脏和胸腔的可见性,在肺周围造成更大的变异性。
基线模型
作为我们的基线模型,我们将构建一个简单的卷积神经网络,将图像调整为方形,并将所有像素值归一化到0到1的范围后,再将其接收。完整的步骤如下所示。
from tensorflow.keras.preprocessing import image, image_dataset_from_directory
from tensorflow.keras import models, layers, optimizers
from tensorflow.keras.callbacks import EarlyStopping
# initiating generator that rescale and resize the images in a directory
train_g = image.ImageDataGenerator(rescale = 1/255).flow_from_directory(train_dir,
target_size = (256,256),
color_mode='grayscale',
class_mode='binary')
val_g = image.ImageDataGenerator(rescale = 1/255).flow_from_directory(val_dir,
target_size = (256,256),
color_mode='grayscale',
class_mode='binary')
# setting up the architecture
model = models.Sequential()
model.add(layers.Conv2D(filters = 32, kernel_size = 3,
activation = 'relu', padding = 'same',
input_shape=(256, 256, 1)))
model.add(layers.MaxPooling2D(pool_size = (2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(128, activation = 'relu'))
model.add(layers.Dense(1, activation='sigmoid'))
# compiling models
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['accuracy', 'Recall'])
# setting up an early stopping callbacks to avoid overfitting
# stop if a validation loss is not reduced for 5 epochs
cp = EarlyStopping(patience = 5, restore_best_weights=True)
# fitting the model
history = model.fit(train_g, # fit train generator
epochs=100, # it will be stopped before 100 epochs (early stopping)
validation_data = val_g, # use the assigned generator as a validation set
callbacks = [cp], # use cp as callback
verbose = 2 # report each epoch without progress bar
)
# evaluating the model
model.evaluate(val_g) # evaluate the best weight on validation set
现在我将详细解释每一步。
缩放数据
keras.image.ImageDataGenerator()获取图像并基于参数创建增强数据。这里我们只是要求它将所有像素值缩放为0到1,而不指定任何其他的增强参数。生成器与flow_from_directory结合使用,以指定的格式从目录中调用图像,然后创建重新标定的数据。
构建模型体系结构
keras.models.Sequential()启动一个序列模型。这个模型将按顺序处理添加的层。
Conv2D是卷积层,它接收输入并通过指定数量的过滤器运行它们。内核大小指的是过滤器的尺寸。因此,在本例中,我们256 * 256 * 1的图像(1指通道的数量,RGB图像有3个通道,而灰度图像有1个通道)中的每一个连续的3 * 3个像素组将通过32个过滤器生成32个特征图,大小为256 * 256 * 1。
由于256不能被3整除,所以padding = ' same'用于在我们的窗口周围添加相等的划填充。
activation = 'relu'的意思是我们将激活函数设定为relu。简单地说,我们告诉这个层转换所有的负值为0。
然后,我们将卷积层的这些输出输入池化层。MaxPooling2D通过只保留卷积输出的每个2 * 2矩阵的最大值来抽象卷积输出。现在我们有32张特征图,大小为128 * 128 * 1。
现在我们需要把这些4维输出缩小到一个单独的数字,这个数字可以告诉我们是将图像划分为肺炎还是正常。我们首先将这一层扁平化成一个单一维度,然后在随后的越来越小的稠密层中运行它们。在最后一层应用一个s型函数作为激活函数,因为我们现在希望模型输出一个输出是否为肺炎的概率。
配置
我们已经定义了模型的体系结构。下一步是决定这个模型的目标以及我们希望它如何实现。使用model.compile,我们告诉模型使用梯度下降最小化二元交叉熵损失(对数损失,logistic回归基本类似)。这里我们使用RMSprop算法来优化这个过程,自适应地降低学习速率。在后面的模型中,我使用了AMSGrad算法,它对我们的问题表现得更好。
拟合数据
最后,我们完成了模型的构建。是时候匹配我们的训练数据了!默认情况下,每个epoch将运行32个批次。我们设置了提前停止,以防止过拟合。如果连续5个epoch验证损失没有减少,此模型将停止运行。我将restore_best_weights设置为true,这样它将在这5个epoch之后恢复到执行的最高权重。
验证和评价
我们的第一个模型显示,预测验证数据类的准确率为94%,损失为0.11。从下图可以看出,training loss还有改进的空间,所以我们可能会增加模型的复杂度。此外,验证损失似乎徘徊在0.1左右。我们可以尝试通过使用数据增强添加更多数据来提高通用性。
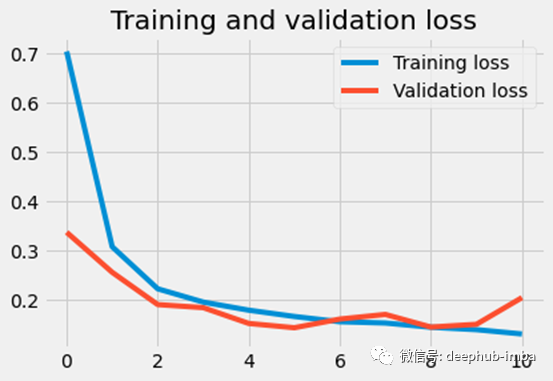
这里是一个完整的代码,从拟合的模型绘制损失图和精度图。
import matplotlib.pyplot as plt
%matplotlib inline
def plot_performance(hist):
'''
takes the fitted model as input
plot accuracy and loss
'''
hist_ = hist.history
epochs = hist.epoch
plt.plot(epochs, hist_['accuracy'], label='Training Accuracy')
plt.plot(epochs, hist_['val_accuracy'], label='Validation Accuracy')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, hist_['loss'], label='Training loss')
plt.plot(epochs, hist_['val_loss'], label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
改进模型
现在,我们将尝试实现数据扩充并为我们的模型增加更多的复杂性。
# redefining training generator
data_aug_train = image.ImageDataGenerator(rescale = 1/255,
# allow rotation withing 15 degree
rotation_range = 15,
# adjust range of brightness (1 = same)
brightness_range = [0.9, 1.1],
# allow shear by up to 5 degree
shear_range=5,
# zoom range of [0.8, 1.2]
zoom_range = 0.2)
# attach generator to the directory
train_g2 = data_aug_train.flow_from_directory(train_dir,
target_size = (256,256),
color_mode='grayscale',
class_mode='binary')
# define architecture
model = models.Sequential()
model.add(layers.Conv2D(32, 3, activation = 'relu', padding = 'same', input_shape=(256, 256, 1)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, 3, activation = 'relu', padding = 'same'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, 3, activation = 'relu', padding = 'same'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(256, 3, activation = 'relu', padding = 'same'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(512, 3, activation = 'relu', padding = 'same'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(2048, activation = 'relu'))
model.add(layers.Dense(1, activation='sigmoid'))
# configure
model.compile(loss='binary_crossentropy',
optimizer=optimizers.Adam(amsgrad = True),
metrics=['accuracy'])
# train
history = model.fit(train_g2,
epochs=100, # it won't run all 100
validation_data = val_g,
callbacks = [cp],
verbose = 2
)
# evaluate
model.evaluate(val_g)
数据增加
这一次,我们向训练图像数据生成器添加了一些参数。因此,现在我们的生成器将通过在指定的范围内对原始图像集应用不同的旋转、亮度、剪切和缩放来为每一批图像创建新图像。
模型的复杂性
我们还增加了三组卷积层和池层,从而增加了模型的复杂性。建议随着图层的发展增加卷积滤波器的数量。这是因为当我们在这些层中移动时,我们试图提取更多的信息,因此需要更大的过滤器集。这个类比类似于我们大脑处理视觉信息的方式。当信号从视网膜移动到视交叉,到丘脑,到初级视觉皮层,然后通过下颞叶皮层,神经元的接受区每一步都变大,对复杂的信息变得越来越敏感。
评价
我们的第二个模型在验证集上显示了97.3%的准确性,损失为0.075。看起来我们的调整确实改进了我们的模型!让我们在测试集上测试它,以确保它们能很好地推广到未见数据。
# create a test generator to apply rescaling
test_g = image.ImageDataGenerator(rescale = 1/255).flow_from_directory(test_dir,
target_size = (256,256),
color_mode='grayscale',
class_mode='binary',
shuffle=False)
# evaluate to get evaluation metrics
model.evaluate(test_g)
# use predict to get the actual prediction
y_pred_prob = model.predict(test_g)
y_pred = [int(x) for x in y_pred_prob]
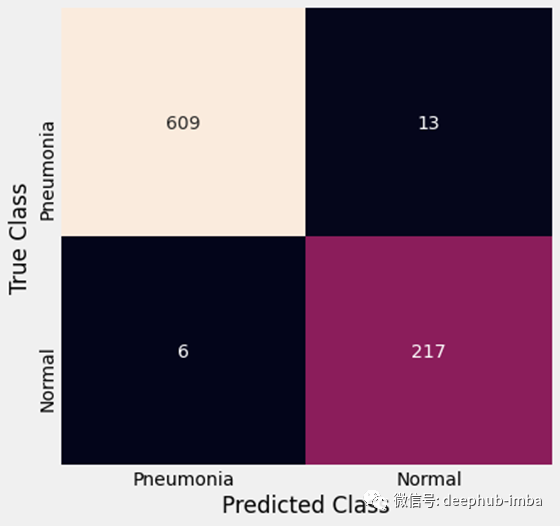
我们的模型以97.8%的准确率预测了测试集中的X_ray图像的类别。成功发现97.9%的肺炎病例。
结论
我们的模型显示,根据我们的数据集,使用卷积神经网络,它能够正确地检测到接近98%的肺炎病例。但尤其对于危及生命的医疗问题,即使只有2%的漏诊病例也不应被简单地忽略。
作者:Eunjoo Byeon
deephub翻译组