

lightGBM可以用来解决大多数表格数据问题的算法。有很多很棒的功能,并且在kaggle这种该数据比赛中会经常使用。
但我一直对了解哪些参数对性能的影响最大以及我应该如何调优lightGBM参数以最大限度地利用它很感兴趣。
我想我应该做一些研究,了解更多关于lightGBM的参数…并分享我的旅程。
我希望读完这篇文章后,你能回答以下问题:
- LightGBM中实现了哪些梯度增强方法,它们有什么区别?
- 一般来说,哪些参数是重要的?
- 哪些正则化参数需要调整?
- 如何调整lightGBM参数在python?
梯度提升的方法
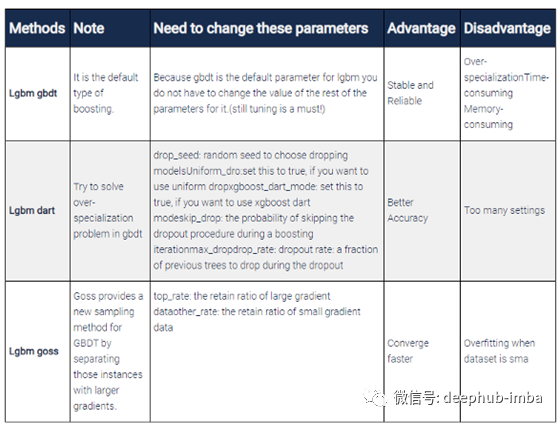
使用LightGBM,你可以运行不同类型的渐变增强提升方法。你有:GBDT、DART和GOSS,这些可以通过“boosting”参数指定。
在下一节中,我将对这些方法进行解释和比较。
梯度提升决策树(GBDT)
该方法是本文首先提出的传统梯度提升决策树,也是XGBoost和pGBRT等优秀库背后的算法。
由于其精度高、效率高、稳定性好,目前已得到广泛的应用。你可能知道gbdt是一个决策树的集合模型但是它到底是什么意思呢?
让我来告诉你要点。
它基于三个重要原则:
- 弱学习者(决策树)
- 梯度优化
- 提升技术
所以在gbdt方法中,我们有很多决策树(弱学习者)。这些树是按顺序构建的:
- 首先,树学习如何适应目标变量
- 第二棵树学习如何适合残差(差异)之间的预测,第一棵树和地面真相
- 第三棵树学习如何匹配第二棵树的残差,以此类推。
所有这些树都是通过传播整个系统的误差梯度来训练的。
gbdt的主要缺点是,在每个树节点中找到最佳分割点非常耗时,而且会消耗内存。其他的提升方法试图解决这个问题。
DART 梯度提升
在这篇优秀的论文中(arxiv/1505.01866),你可以学习所有关于DART梯度提升的东西,这是一种使用dropout(神经网络中的标准)的方法,来改进模型正则化和处理一些其他不太明显的问题。
也就是说,gbdt存在过度专门化(over-specialization)的问题,这意味着在以后的迭代中添加的树往往只会影响对少数实例的预测,而对其余实例的贡献则可以忽略不计。添加dropout会使树在以后的迭代中更加难以专门化那些少数的示例,从而提高性能。
lgbm goss 基于梯度的单边采样
事实上,将该方法命名为lightgbm的最重要原因就是使用了基于本文的Goss方法。Goss是较新的、较轻的gbdt实现(因此是“light”gbm)。
标准的gbdt是可靠的,但在大型数据集上速度不够快。因此goss提出了一种基于梯度的采样方法来避免搜索整个搜索空间。我们知道,对于每个数据实例,当梯度很小时,这意味着不用担心数据是经过良好训练的,而当梯度很大时,应该重新训练。这里我们有两个方面,数据实例有大的和小的渐变。因此,goss以一个大的梯度保存所有数据,并对一个小梯度的数据进行随机抽样(这就是为什么它被称为单边抽样)。这使得搜索空间更小,goss的收敛速度更快。
让我们把这些差异放在一个表格中:
注意:如果你将增强设置为RF,那么lightgbm算法表现为随机森林而不是增强树! 根据文档,要使用RF,必须使用bagging_fraction和feature_fraction小于1。
正则化
在这一节中,我将介绍lightgbm的一些重要的正则化参数。显然,这些是您需要调优以防止过拟合的参数。
您应该知道,对于较小的数据集(<10000条记录),lightGBM可能不是最佳选择。在这里,调优lightgbm参数可能没有帮助。
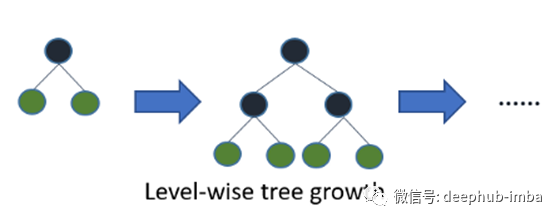
此外,lightgbm使用叶向树生长算法,而xgboost使用深度树生长算法。叶向方法使树的收敛速度更快,但过拟合的几率增加。
注意:如果有人问您LightGBM和XGBoost之间的主要区别是什么?你可以很容易地说,它们的区别在于它们是如何实现的。
根据lightGBM文档,当面临过拟合时,您可能需要做以下参数调优:
- 使用更小的max_bin
- 使用更小的num_leaves
- 使用min_data_in_leaf和min_sum_hessian_in_leaf
- 通过设置bagging_fraction和bagging_freq使用bagging_freq
- 通过设置feature_fraction使用特征子采样
- 使用更大的训练数据
- 尝试lambda_l1、lambda_l2和min_gain_to_split进行正则化
- 尝试max_depth以避免树的深度增长
在下面的部分中,我将更详细地解释这些参数。
lambda_l1
Lambda_l1(和lambda_l2)控制l1/l2,以及min_gain_to_split用于防止过拟合。我强烈建议您使用参数调优(在后面的小节中讨论)来确定这些参数的最佳值。
num_leaves
num_leaves无疑是控制模型复杂性的最重要参数之一。通过它,您可以设置每个弱学习者拥有的叶子的最大数量。较大的num_leaves增加了训练集的精确度,也增加了因过度拟合而受伤的几率。根据文档,一个简单的方法是num_leaves = 2^(max_depth)但是,考虑到在lightgbm中叶状树比层次树更深,你需要小心过度拟合!因此,必须同时使用max_depth调优num_leaves。
子采样
通过子样例(或bagging_fraction),您可以指定每个树构建迭代使用的行数百分比。这意味着将随机选择一些行来匹配每个学习者(树)。这不仅提高了泛化能力,也提高了训练速度。
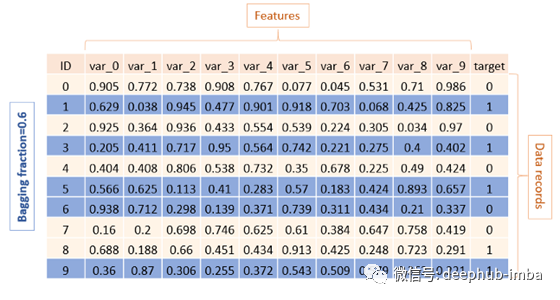
我建议对基线模型使用更小的子样本值,然后在完成其他实验(不同的特征选择,不同的树结构)时增加这个值。
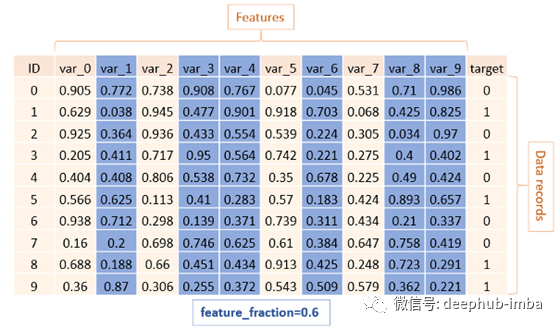
feature_fraction
特征分数或子特征处理列采样,LightGBM将在每次迭代(树)上随机选择特征子集。例如,如果将其设置为0.6,LightGBM将在训练每棵树之前选择60%的特性。
这个功能有两种用法:
- 可以用来加速训练吗
- 可以用来处理过拟合吗
max_depth
该参数控制每棵经过训练的树的最大深度,将对:
- num_leaves参数的最佳值
- 模型的性能
- 训练时间
注意,如果您使用较大的max_depth值,那么您的模型可能会对于训练集过拟合。
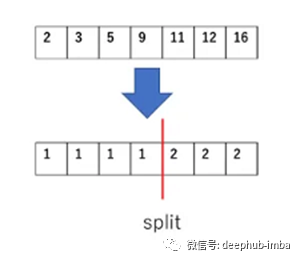
max_bin
装箱是一种用离散视图(直方图)表示数据的技术。Lightgbm在创建弱学习者时,使用基于直方图的算法来寻找最优分割点。因此,每个连续的数字特性(例如视频的视图数)应该被分割成离散的容器。
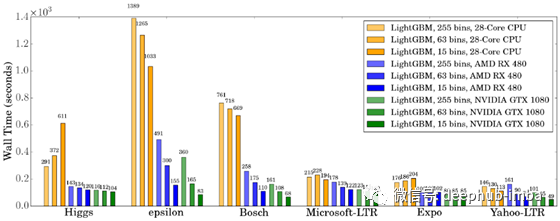
此外,在这个GitHub repo(huanzhang12/lightgbm-gpu)中,你可以找到一些全面的实验,完全解释了改变max_bin对CPU和GPU的影响。
如果你定义max_bin 255,这意味着我们可以有255个唯一的值每个特性。那么,较小的max_bin会导致更快的速度,较大的值会提高准确性。
训练参数
当你想用lightgbm训练你的模型时,一些典型的问题可能会出现:
- 训练是一个耗时的过程
- 处理计算复杂度(CPU/GPU RAM约束)
- 处理分类特征
- 拥有不平衡的数据集
- 定制度量的需要
- 需要对分类或回归问题进行的调整
在本节中,我们将尝试详细解释这些要点。
num_iterations
Num_iterations指定增强迭代的次数(要构建的树)。你建立的树越多,你的模型就越精确,代价是:
- 较长的训练时间
- 过拟合的可能性更高
从较少的树开始构建基线,然后当您想从模型中挤出最后的%时增加基线。
建议使用更小的learning_rate和更大的num_iteration。此外,如果您想要更高的num_iteration,那么您应该使用early_stopping_rounds,以便在无法学习任何有用的内容时停止训练。
early_stopping_rounds
如果验证度量在最后一轮停止后没有改进,此参数将停止训练。这应该与一些迭代成对地进行定义。如果你把它设置得太大,你就增加了过拟合的变化(但你的模型可以更好)。
经验法则是让它占num_iterations的10%。
lightgbm categorical_feature
使用lightgbm的优势之一是它可以很好地处理分类特性。是的,这个算法非常强大,但是你必须小心如何使用它的参数。lightgbm使用一种特殊的整数编码方法(由Fisher提出)来处理分类特征
实验表明,该方法比常用的单热编码方法具有更好的性能。
它的默认值是“auto”,意思是:让lightgbm决定哪个表示lightgbm将推断哪些特性是绝对的。
它并不总是工作得很好,我强烈建议您简单地用这段代码手动设置分类特性
cat_col = dataset_name.select_dtypes(‘object’).columns.tolist()
但是在幕后发生了什么,lightgbm是如何处理分类特征的呢?
根据lightgbm的文档,我们知道树学习器不能很好地使用一种热编码方法,因为它们在树中深度生长。在提出的替代方法中,树形学习器被最优构造。例如,一个特征有k个不同的类别,有2^(k-1) -1个可能的划分,通过fisher方法,可以改进到k * log(k),通过找到分类特征中值排序直方图的最佳分割方式。
is_unbalance vs scale_pos_weight
其中一个问题,你可能面临的二分类问题是如何处理不平衡的数据集。显然,您需要平衡正/负样本,但如何在lightgbm中做到这一点呢?
lightgbm中有两个参数允许你处理这个问题,那就是is_unbalance和scale_pos_weight,但是它们之间有什么区别呢?
当您设置Is_unbalace: True时,算法将尝试自动平衡占主导地位的标签的权重(使用列集中的pos/neg分数)
如果您想改变scale_pos_weight(默认情况下是1,这意味着假设正负标签都是相等的),在不平衡数据集的情况下,您可以使用以下公式来正确地设置它
sample_pos_weight = number of negative samples / number of positive samples
lgbm函数宏指令(feaval)
有时你想定义一个自定义评估函数来测量你的模型的性能,你需要创建一个“feval”函数。
Feval函数应该接受两个参数:
preds 、train_data
并返回
eval_name、eval_result、is_higher_better
让我们一步一步地创建一个自定义度量函数。
定义一个单独的python函数
def feval_func(preds, train_data):
# Define a formula that evaluates the results
return ('feval_func_name', eval_result, False)
使用这个函数作为参数:
print('Start training...')
lgb_train = lgb.train(...,
metric=None,
feval=feval_func)
注意:要使用feval函数代替度量,您应该设置度量参数 metric “None”。
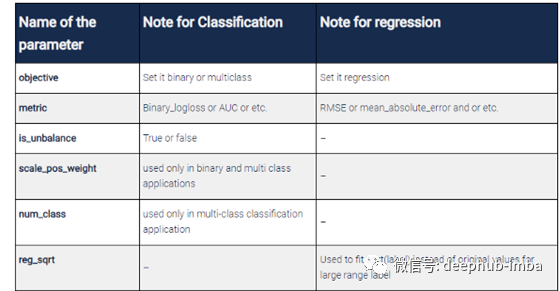
分类参数与回归参数
我之前提到的大多数事情对于分类和回归都是正确的,但是有些事情需要调整。
具体你应该:
lightgbm最重要的参数
我们已经在前面的部分中回顾并了解了有关lightgbm参数的知识,但是如果不提及Laurae令人难以置信的基准测试,那么关于增强树的文章将是不完整的。
您可以了解用于lightGBM和XGBoost的许多问题的最佳默认参数。
你可以查看这里(https://sites.google.com/view/lauraepp/parameters),但一些最重要的结论是:
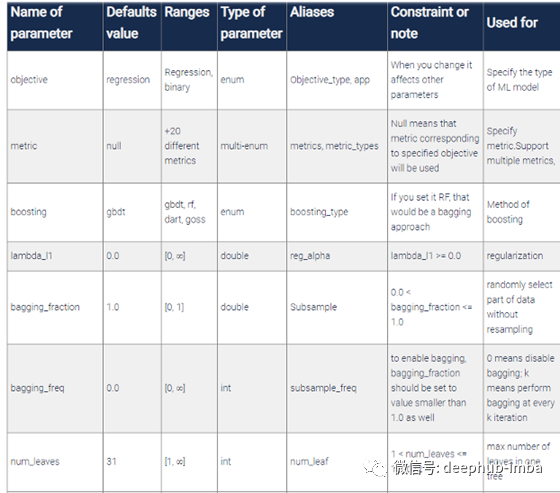
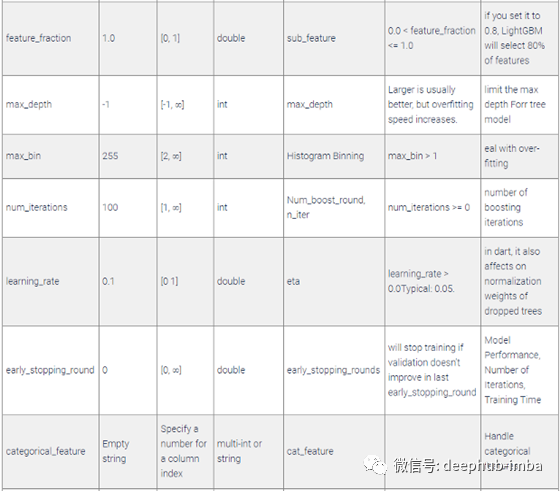
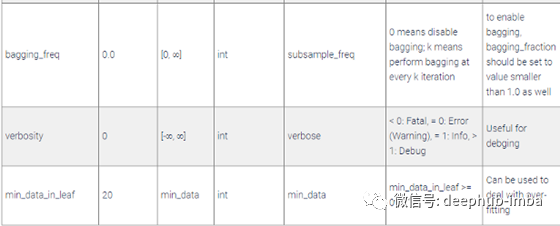
注意:绝对不要理会任何参数值的默认值,并根据您的问题进行调整。也就是说,这些参数是超参数调整算法的一个很好的起点。
Python中的Lightgbm参数调整示例
最后,在解释完所有重要参数之后,该进行一些实验了!
我将使用最受欢迎的Kaggle竞赛之一:Santander Customer Transaction Prediction. 交易预测
我将使用本文介绍如何在任何脚本中的Python中运行超参数调整。
在开始之前,一个重要的问题!我们应该调整哪些参数?
请注意您要解决的问题,例如,Santander 数据集高度不平衡,在调整时应考虑到这一点!
一些参数是相互依赖的,必须一起调整。例如,min_data_in_leaf取决于训练样本和num_leaves的数量。
注意:为超参数创建两个字典是一个好主意,一个字典包含您不想调整的参数和值,另一个字典包含您想要调整的参数和值范围。
SEARCH_PARAMS = {'learning_rate': 0.4,
'max_depth': 15,
'num_leaves': 20,
'feature_fraction': 0.8,
'subsample': 0.2}
FIXED_PARAMS={'objective': 'binary',
'metric': 'auc',
'is_unbalance':True,
'boosting':'gbdt',
'num_boost_round':300,
'early_stopping_rounds':30}
这样,您就可以将基线值与搜索空间分开!
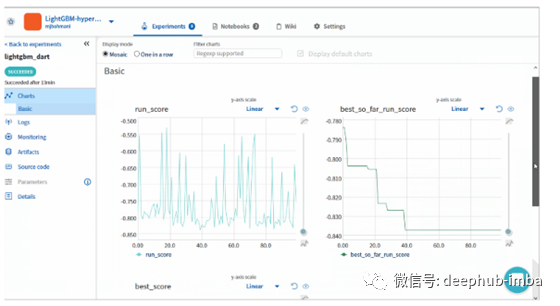
如果您查看了上一节,则会发现我在数据集上进行了14个以上的不同实验。在这里,我解释了如何逐步调整超参数的值。
创建基线训练代码:
from sklearn.metrics import roc_auc_score, roc_curve
from sklearn.model_selection import train_test_split
import neptunecontrib.monitoring.skopt as sk_utils
import lightgbm as lgb
import pandas as pd
import neptune
import skopt
import sys
import os
SEARCH_PARAMS = {'learning_rate': 0.4,
'max_depth': 15,
'num_leaves': 32,
'feature_fraction': 0.8,
'subsample': 0.2}
FIXED_PARAMS={'objective': 'binary',
'metric': 'auc',
'is_unbalance':True,
'bagging_freq':5,
'boosting':'dart',
'num_boost_round':300,
'early_stopping_rounds':30}
def train_evaluate(search_params):
# you can download the dataset from this link(https://www.kaggle.com/c/santander-customer-transaction-prediction/data)
# import Dataset to play with it
data= pd.read_csv("sample_train.csv")
X = data.drop(['ID_code', 'target'], axis=1)
y = data['target']
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.2, random_state=1234)
train_data = lgb.Dataset(X_train, label=y_train)
valid_data = lgb.Dataset(X_valid, label=y_valid, reference=train_data)
params = {'metric':FIXED_PARAMS['metric'],
'objective':FIXED_PARAMS['objective'],
**search_params}
model = lgb.train(params, train_data,
valid_sets=[valid_data],
num_boost_round=FIXED_PARAMS['num_boost_round'],
early_stopping_rounds=FIXED_PARAMS['early_stopping_rounds'],
valid_names=['valid'])
score = model.best_score['valid']['auc']
return score
使用您选择的超参数优化库(例如scikit-optimize)。
neptune.init('mjbahmani/LightGBM-hyperparameters')
neptune.create_experiment('lgb-tuning_final', upload_source_files=['*.*'],
tags=['lgb-tuning', 'dart'],params=SEARCH_PARAMS)
SPACE = [
skopt.space.Real(0.01, 0.5, name='learning_rate', prior='log-uniform'),
skopt.space.Integer(1, 30, name='max_depth'),
skopt.space.Integer(10, 200, name='num_leaves'),
skopt.space.Real(0.1, 1.0, name='feature_fraction', prior='uniform'),
skopt.space.Real(0.1, 1.0, name='subsample', prior='uniform')
]
@skopt.utils.use_named_args(SPACE)
def objective(**params):
return -1.0 * train_evaluate(params)
monitor = sk_utils.NeptuneMonitor()
results = skopt.forest_minimize(objective, SPACE,
n_calls=100, n_random_starts=10,
callback=[monitor])
sk_utils.log_results(results)
neptune.stop()
注,本文代码使用了neptune.ai平台,所以有一些neptune的api
尝试不同类型的配置并在Neptune中跟踪结果
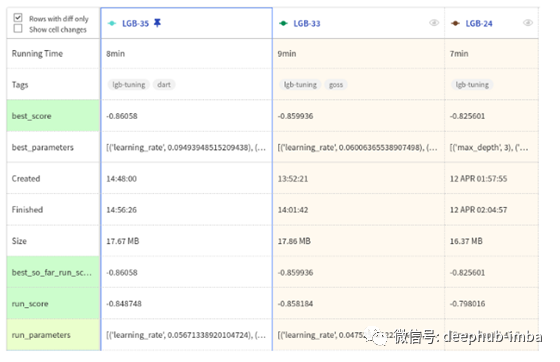
最后,在下表中,您可以看到参数中发生了什么变化。
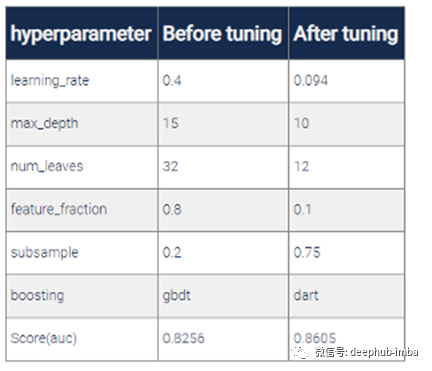
总结
长话短说,您了解到:
- lightgbm的主要参数是什么,
- 如何使用feval函数创建自定义指标
- 主要参数的默认值是多少
- 看到了如何调整lightgbm参数以改善模型性能的示例
作者:Kamil Kaczmarek
deephub 翻译组
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
喜欢就请三连暴击!********** **********