
在本教程中,我将将展示如何使用梯度上升来解决如何对输入进行错误分类。
出如何使用梯度上升改变一个输入分类
神经网络是一个黑盒。理解他们的决策需要创造力,但他们并不是那么不透明。
在本教程中,我将向您展示如何使用反向传播来更改输入,使其按照想要的方式进行分类。
人类的黑盒
首先让我们以人类为例。如果我向你展示以下输入:

很有可能你不知道这是5还是6。事实上,我相信我可以让你们相信这也可能是8。
现在,如果你问一个人,他们需要做什么才能把一个东西变成5,你可能会在视觉上做这样的事情:

如果我想让你把这个变成8,你可以这样做:

现在,用几个if语句或查看几个系数不容易解释这个问题的答案。并且对于某些类型的输入(图像,声音,视频等),可解释性无疑会变得更加困难,但并非不可能。
神经网络怎么处理
一个神经网络如何回答我上面提出的同样的问题?要回答这个问题,我们可以用梯度上升来做。
这是神经网络认为我们需要修改输入使其更接近其他分类的方式。
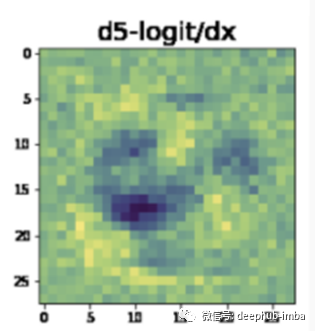
由此产生了两个有趣的结果。首先,黑色区域是我们需要去除像素密度的网络物体。第二,黄色区域是它认为我们需要增加像素密度的地方。
我们可以在这个梯度方向上采取一步,添加梯度到原始图像。当然,我们可以一遍又一遍地重复这个过程,最终将输入变为我们所希望的预测。
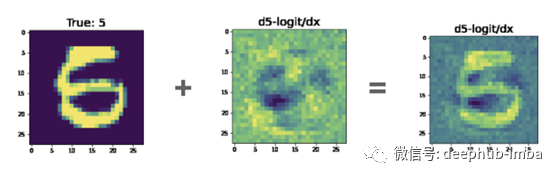
你可以看到图片左下角的黑斑和人类的想法非常相似。
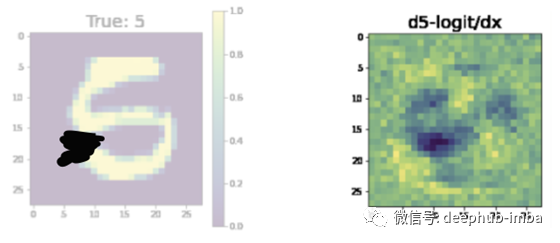
让输入看起来更像8怎么样?这是网络认为你必须改变输入的方式。
值得注意的是,在左下角有一团黑色的物质在中间有一团明亮的物质。如果我们把这个和输入相加,我们得到如下结果:

在这种情况下,我并不特别相信我们已经将这个5变成了8。但是,我们减少了5的概率,说服你这个是8的论点肯定会更容易使用 右侧的图片,而不是左侧的图片。
梯度
在回归分析中,我们通过系数来了解我们所学到的知识。在随机森林中,我们可以观察决策节点。
在神经网络中,它归结为我们如何创造性地使用梯度。为了对这个数字进行分类,我们根据可能的预测生成了一个分布。
这就是我们说的前向传播
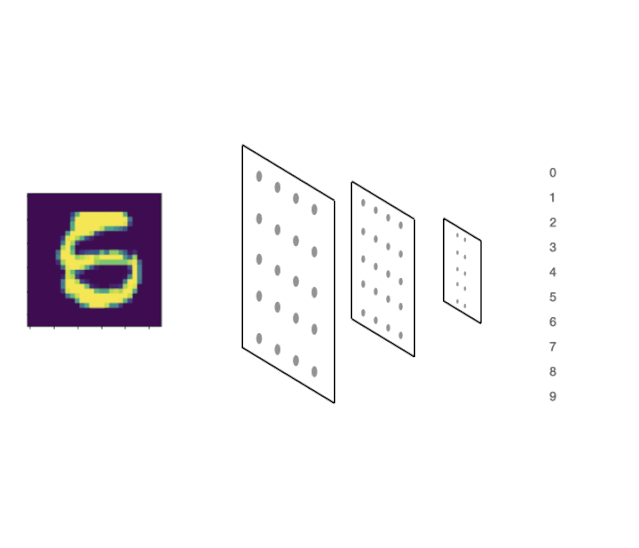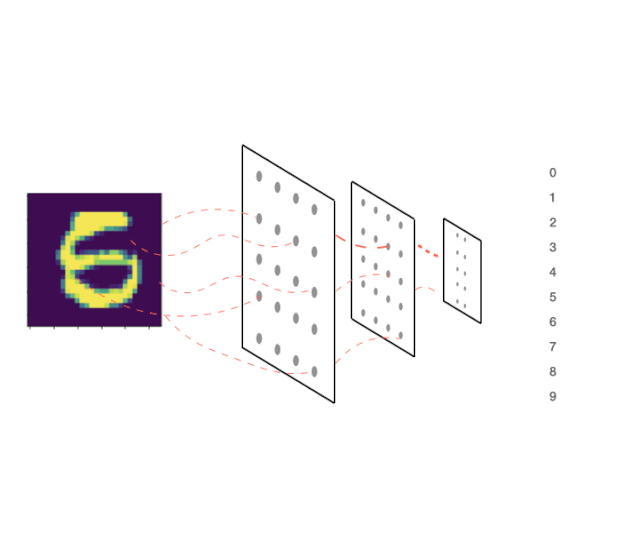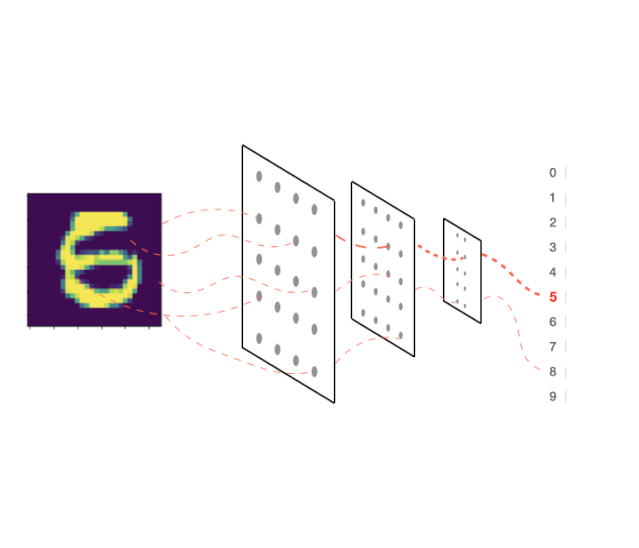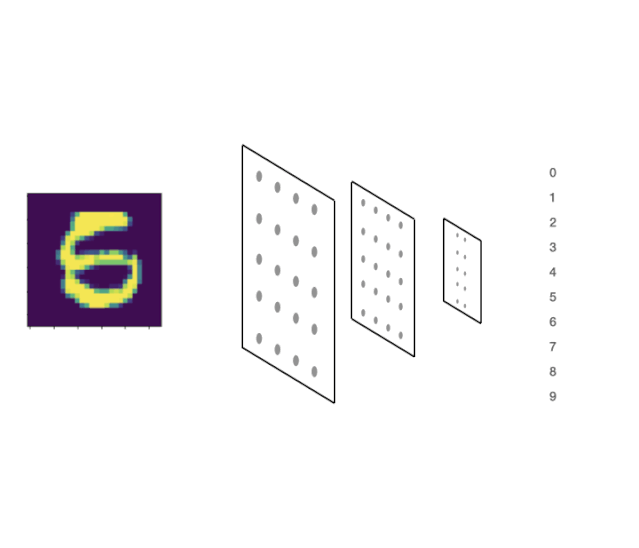
在前进过程中,我们计算输出的概率分布
代码类似这样:

现在假设我们想要欺骗网络,让它预测输入x的值为“5”,实现这一点的方法是给它一个图像(x),计算对图像的预测,然后最大化预测标签“5”的概率。
为此,我们可以使用梯度上升来计算第6个索引处(即label = 5) (p)相对于输入x的预测的梯度。
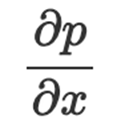
为了在代码中做到这一点,我们将输入x作为参数输入到神经网络,选择第6个预测(因为我们有标签:0,1,2,3,4,5,…),第6个索引意味着标签“5”。
视觉上这看起来像:
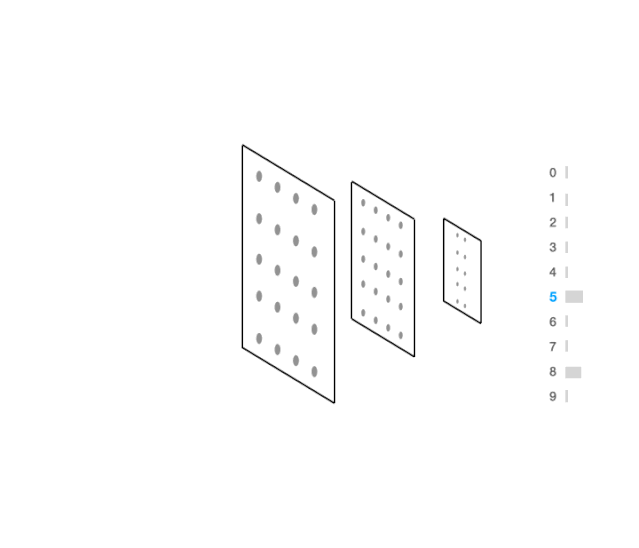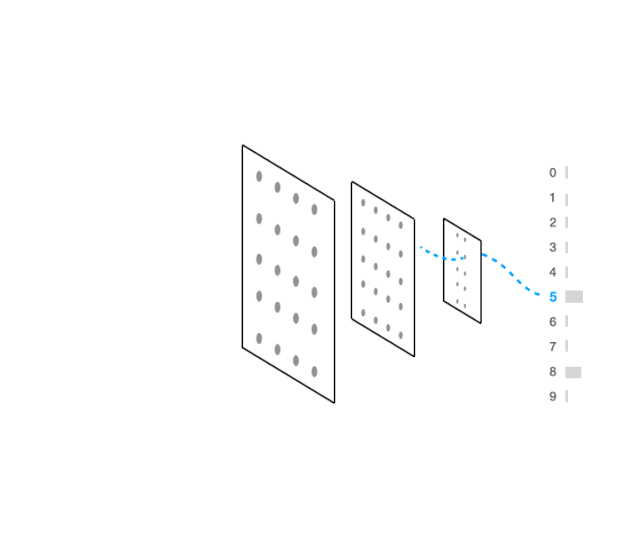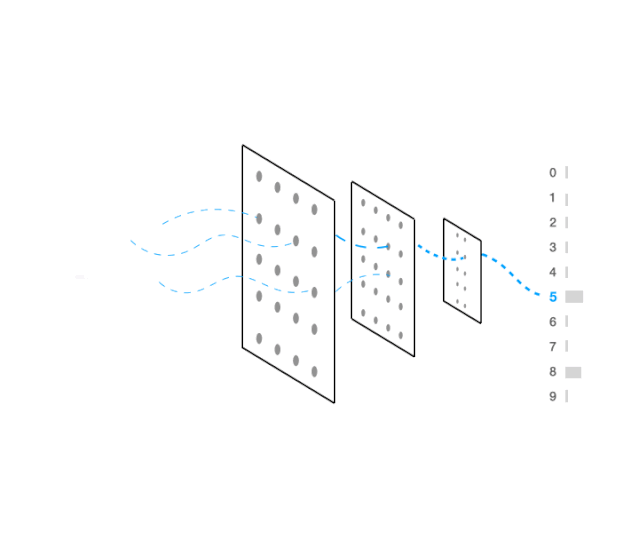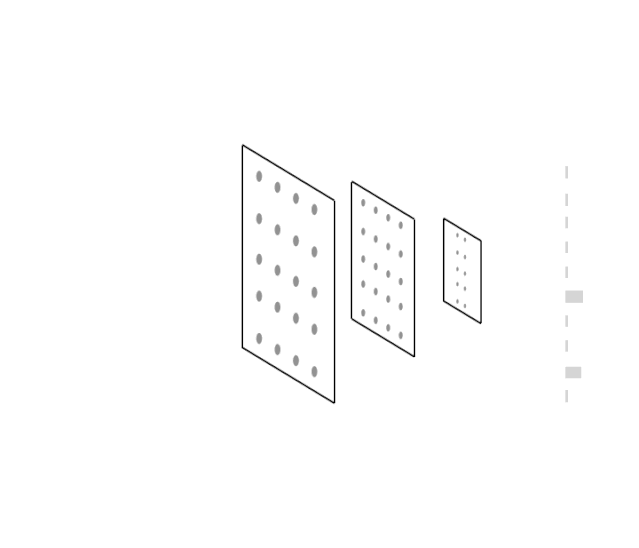
代码如下:

当我们调用.backward()时,所发生的过程可以通过前面的动画可视化。
现在我们计算了梯度,我们可以可视化并绘制它们:

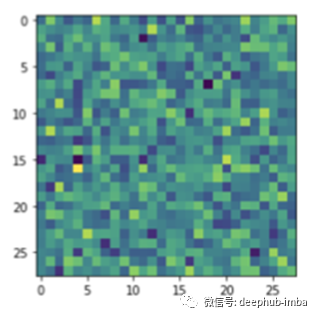
由于网络还没有经过训练,所以上面的梯度看起来像随机噪声……但是,一旦我们对网络进行训练,梯度的信息会更丰富:
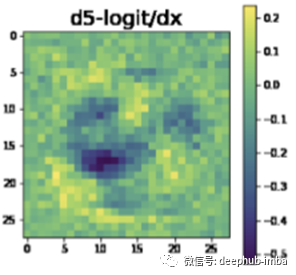
通过回调实现自动化
这是一个非常有用的工具,帮助阐明在你的网络训练中发生了什么。在这种情况下,我们想要自动化这个过程,这样它就会在训练中自动发生。
为此,我们将使用PyTorch Lightning来实现我们的神经网络:
import torch
import torch.nn.functional as F
import pytorch_lightning as pl
class LitClassifier(pl.LightningModule):
def __init__(self):
super().__init__()
self.l1 = torch.nn.Linear(28 * 28, 10)
def forward(self, x):
return torch.relu(self.l1(x.view(x.size(0), -1)))
def training_step(self, batch, batch_idx):
x, y = batch
y_hat = self(x)
loss = F.cross_entropy(y_hat, y)
result = pl.TrainResult(loss)
# enable the auto confused logit callback
self.last_batch = batch
self.last_logits = y_hat.detach()
result.log('train_loss', loss, on_epoch=True)
return result
def validation_step(self, batch, batch_idx):
x, y = batch
y_hat = self(x)
loss = F.cross_entropy(y_hat, y)
result = pl.EvalResult(checkpoint_on=loss)
result.log('val_loss', loss)
return result
def configure_optimizers(self):
return torch.optim.Adam(self.parameters(), lr=0.005)
可以将自动绘制出此处描述内容的复杂代码,抽象为Lightning中的Callback。Callback回调是一个小程序,您可能会在训练的各个部分调用它。
在本例中,当处理训练批处理时,我们希望生成这些图像,以防某些输入出现混乱。。
import torch
from pytorch_lightning import Callback
from torch import nn
class ConfusedLogitCallback(Callback):
def __init__(
self,
top_k,
projection_factor=3,
min_logit_value=5.0,
logging_batch_interval=20,
max_logit_difference=0.1
):
super().__init__()
self.top_k = top_k
self.projection_factor = projection_factor
self.max_logit_difference = max_logit_difference
self.logging_batch_interval = logging_batch_interval
self.min_logit_value = min_logit_value
def on_train_batch_end(self, trainer, pl_module, batch, batch_idx, dataloader_idx):
# show images only every 20 batches
if (trainer.batch_idx + 1) % self.logging_batch_interval != 0:
return
# pick the last batch and logits
x, y = batch
try:
logits = pl_module.last_logits
except AttributeError as e:
m = """please track the last_logits in the training_step like so:
def training_step(...):
self.last_logits = your_logits
"""
raise AttributeError(m)
# only check when it has opinions (ie: the logit > 5)
if logits.max() > self.min_logit_value:
# pick the top two confused probs
(values, idxs) = torch.topk(logits, k=2, dim=1)
# care about only the ones that are at most eps close to each other
eps = self.max_logit_difference
mask = (values[:, 0] - values[:, 1]).abs() < eps
if mask.sum() > 0:
# pull out the ones we care about
confusing_x = x[mask, ...]
confusing_y = y[mask]
mask_idxs = idxs[mask]
pl_module.eval()
self._plot(confusing_x, confusing_y, trainer, pl_module, mask_idxs)
pl_module.train()
def _plot(self, confusing_x, confusing_y, trainer, model, mask_idxs):
from matplotlib import pyplot as plt
confusing_x = confusing_x[:self.top_k]
confusing_y = confusing_y[:self.top_k]
x_param_a = nn.Parameter(confusing_x)
x_param_b = nn.Parameter(confusing_x)
batch_size, c, w, h = confusing_x.size()
for logit_i, x_param in enumerate((x_param_a, x_param_b)):
x_param = x_param.to(model.device)
logits = model(x_param.view(batch_size, -1))
logits[:, mask_idxs[:, logit_i]].sum().backward()
# reshape grads
grad_a = x_param_a.grad.view(batch_size, w, h)
grad_b = x_param_b.grad.view(batch_size, w, h)
for img_i in range(len(confusing_x)):
x = confusing_x[img_i].squeeze(0).cpu()
y = confusing_y[img_i].cpu()
ga = grad_a[img_i].cpu()
gb = grad_b[img_i].cpu()
mask_idx = mask_idxs[img_i].cpu()
fig, axarr = plt.subplots(nrows=2, ncols=3, figsize=(15, 10))
self.__draw_sample(fig, axarr, 0, 0, x, f'True: {y}')
self.__draw_sample(fig, axarr, 0, 1, ga, f'd{mask_idx[0]}-logit/dx')
self.__draw_sample(fig, axarr, 0, 2, gb, f'd{mask_idx[1]}-logit/dx')
self.__draw_sample(fig, axarr, 1, 1, ga * 2 + x, f'd{mask_idx[0]}-logit/dx')
self.__draw_sample(fig, axarr, 1, 2, gb * 2 + x, f'd{mask_idx[1]}-logit/dx')
trainer.logger.experiment.add_figure('confusing_imgs', fig, global_step=trainer.global_step)
@staticmethod
def __draw_sample(fig, axarr, row_idx, col_idx, img, title):
im = axarr[row_idx, col_idx].imshow(img)
fig.colorbar(im, ax=axarr[row_idx, col_idx])
axarr[row_idx, col_idx].set_title(title, fontsize=20)
但是,通过安装pytorch-lightning-bolts,我们让它变得更容易了
!pip install pytorch-lightning-bolts
from pl_bolts.callbacks.vision import ConfusedLogitCallback
trainer = Trainer(callbacks=[ConfusedLogitCallback(1)])
把它们放在一起
最后,我们可以训练我们的模型,并在判断逻辑产生混乱时自动生成图像。
# data
dataset = MNIST(os.getcwd(), download=True, transform=transforms.ToTensor())
train, val = random_split(dataset, [55000, 5000])
# model
model = LitClassifier()
# attach callback
trainer = Trainer(callbacks=[ConfusedLogitCallback(1)])
# train!
trainer.fit(model, DataLoader(train, batch_size=64), DataLoader(val, batch_size=64))
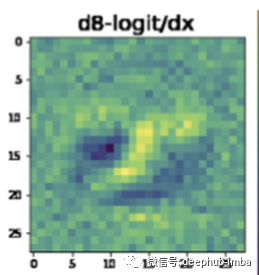
tensorboard会自动生成如下图片:
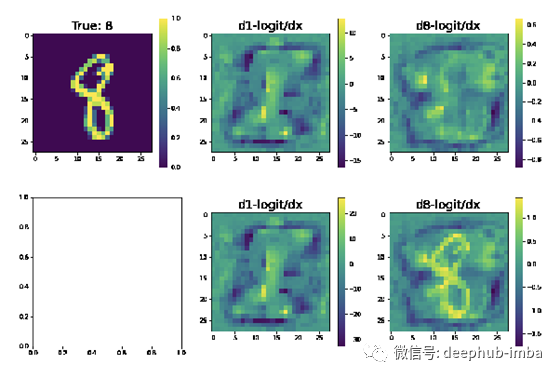
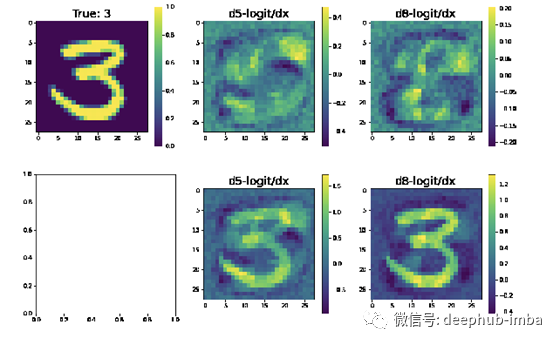
看看这个是不是变得不一样了
作者:William Falcon
完整代码:https://colab.research.google.com/drive/16HVAJHdCkyj7W43Q3ZChnxZ7DOwx6K5i?usp=sharing
deephub翻译组