
定义
向前传播
通常,当我们使用神经网络时,我们输入某个向量x,然后网络产生一个输出y,这个输入向量通过每一层隐含层,直到输出层。这个方向的流动叫做正向传播。
在训练阶段,输入最后可以计算出一个代价标量J(θ)。
反向传播算法
然后,代价通过反向算法返回到网络中,调整权重并计算梯度。未完待续……
分析
可能是你们在学校里做过用代数的方法来分析反向传播。对于普通函数,这很简单。但当解析法很困难时,我们通常尝试数值微分。
数值微分
由于代数操作很困难,在数值方法中,我们通常使用计算量大的方法,因此经常需要用到计算机。一般有两种方法,一种是利用近邻点,另一种是利用曲线拟合。
随机梯度下降法
负责“学习”的算法。它使用了由反向传播算法产生的梯度。
反向传播算法
然后,反向传播算法返回到网络中,调整权重来计算梯度。一般来说,反向传播算法不仅仅适用于多层感知器。它是一个通用的数值微分算法,可以用来找到任何函数的导数,只要给定函数是可微的。
该算法最重要的特点之一是,它使用了一个相对简单和廉价的程序来计算微分,提高效率。
如何计算一个代价函数的梯度
给定一个函数f,我们想要找到梯度:
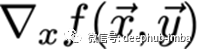
x是一组我们需要它的导数的变量,y是额外的变量,我们不需要它的导数。
为了使网络继续学习,我们想要找到代价函数的梯度。
损失函数
这个函数通常应用于一个数据点,寻找预测点和实际点之间的距离。大多数情况下,这是距离的平方损失。
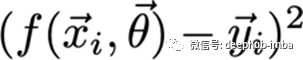
代价函数
这个函数是所有损失函数的组合,它不总是一个和。但有时是平均值或加权平均值。例如:
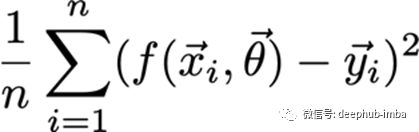
如何计算一个代价函数的梯度
给定一个函数f,我们想要找到梯度:
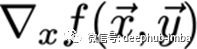
x是一组我们需要它的导数的变量,y是额外的变量,我们不需要它的导数。
为了网络的学习,我们想要找到代价函数的梯度。
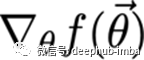
微积分链式法则
假设x是实数,f和g都是实数到实数的映射函数。此外,

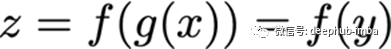
根据链式法则,
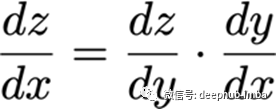
多变量链式法则
已知x和y是不同维数的向量,

g和f也是从一个维度映射到另一个维度的函数,

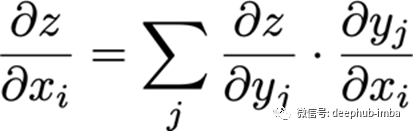
或者说,
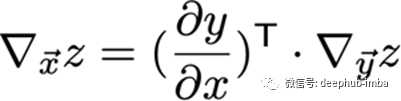
∂y /∂x是g的n×m雅可比矩阵。
梯度
而导数或微分是沿一个轴的变化率。梯度是一个函数沿多个轴的斜率矢量。
雅可比矩阵
有时我们需要找出输入和输出都是向量的函数的所有偏导数。包含所有这些偏导数的矩阵就是雅可比矩阵。
有函数
雅可比矩阵J为:

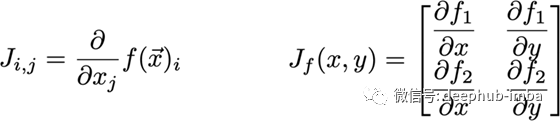
张量的链式法则
我们大部分时间都在处理高维数据,例如图像和视频。所以我们需要将链式法则扩展到张量。
想象一个三维张量,
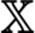
z值对这个张量的梯度是,
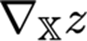
对于这个张量, iᵗʰ 指数给出一个向量,
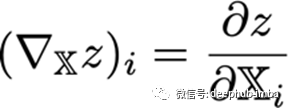
所以考虑到这一点,

张量的链式法则是,
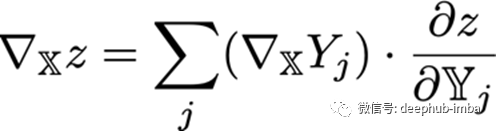
概念
计算图
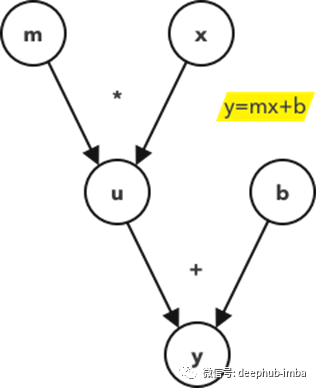
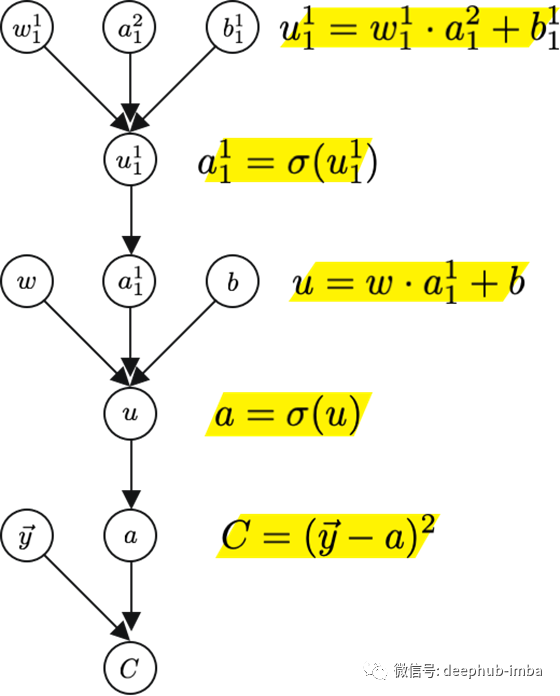
这是一个关于直线方程的计算图的例子。开始节点是你将在方程中看到的,为了计算图的方便,总是需要为中间节点定义额外的变量,在这个例子中是节点u。节点“u”等价于“mx”。
我们引入这个概念来说明复杂的计算流程的支撑算法。
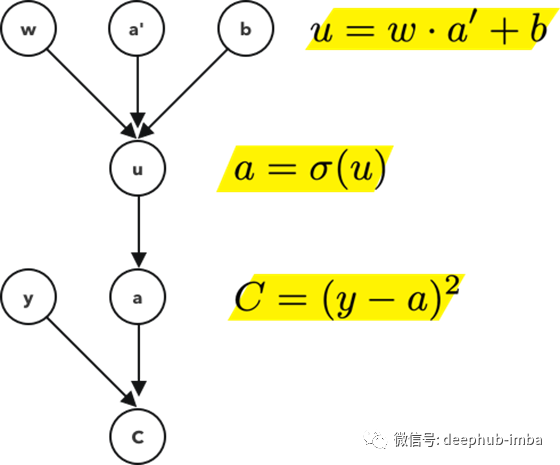
还记得之前,当我们把损失函数定义为差的平方,这就是我们在计算图的最后一层使用的。其中y是实际值a是预测值。

请注意,我们的损失值严重依赖于最后的激活值,而最后的激活值又依赖于前一个激活值,再依赖于前一个激活值,以此类推。
在神经网络的前进过程中,我们最终得到一个预测值a。在训练阶段,我们有一个额外的信息,这就是网络应该得到的实际结果,y。我们的损失函数就是这些值之间的距离。当我们想要最小化这个距离时,我们首先要更新最后一层的权重。但这最后一层依赖于它的前一层,因此我们更新它们。所以从这个意义上说,我们是在向后传递神经网络并更新每一层。
敏感性改变
当x的一个小变化导致函数f的一个大变化时,我们说函数对x非常敏感如果x的一个小变化导致f的一个小变化,我们说它不是很敏感。
例如,一种药物的有效性可用f来衡量,而x是所使用的剂量。灵敏度表示为:
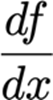
为了进一步扩展,我们假设现在的函数是多变量的。

函数f可以对每个输入有不同的敏感度。举个例子,也许仅仅进行数量分析是不够的,所以我们把药物分解成3种活性成分,然后考虑每种成分的剂量。
最后一点扩展,如果其中一个输入值,比如x也依赖于它自己的输入。我们可以用链式法则来找出敏感性。同样的例子,也许x被分解成它在身体里的组成部分,所以我们也要考虑这个。

我们考虑x的组成,以及它的成分如何影响药物的整体效果。

在这里,我们测量的是整个药物的效果对药物中这个小成分的敏感度。
一个简单的模型
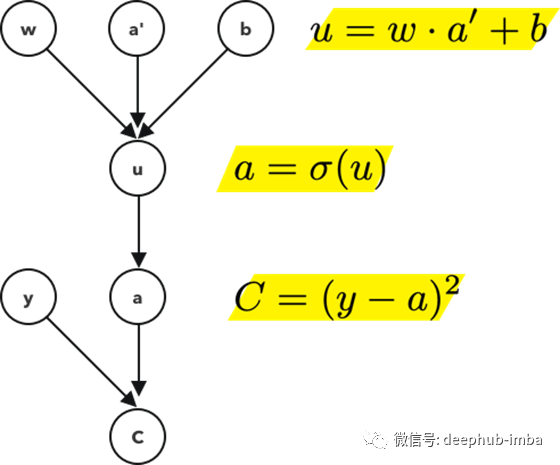
这个计算图考虑了节点a和它前面的节点a '之间的连接。

用链式法则,
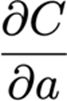
它测量了a对u的微小变化有多敏感。然后我们继续前面的3次计算,
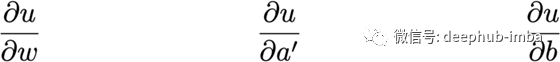
测量u对以下每一项的微小变化的敏感度:
- 权重,w
- 之前的激活值,a '
- 偏质,b
把这些放在一起,
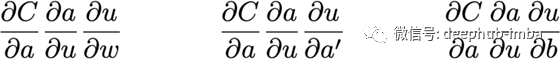
简单模型的复杂性
如果在前面的例子中,我们有两个节点和它们之间的一个链接。在这个例子中,我们有3个节点和2个链接。

因为链式法则的链式长度是没有限制的。我们可以对任意数量的层继续这样做。对于这一层,注意计算图是这样的,
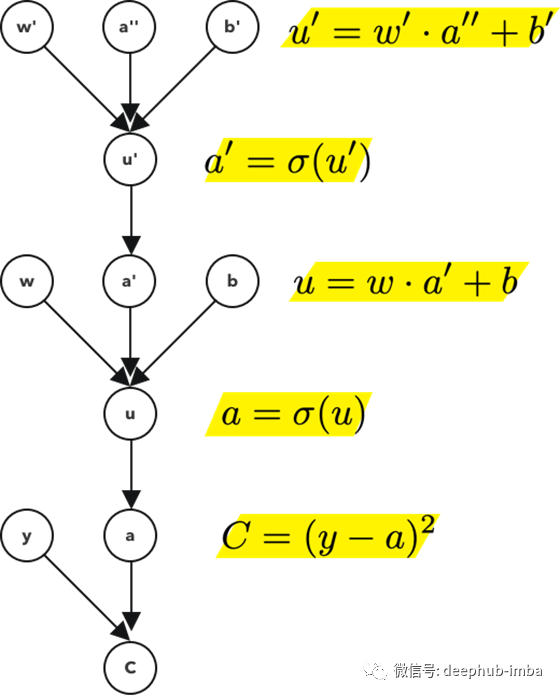
请注意,需要用附加的刻度对每个节点进行注释。这些刻度不是衍生物,它们只是表示u和u '是不同的、唯一的值或对象
复杂模型的复杂性
到目前为止的例子都是线性的,链表式的神经网络。把它扩展到现实的网络是这样的,
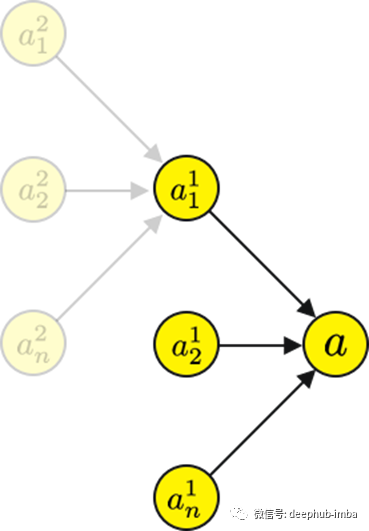
我们需要给网络添加一些额外的符号。
让我们通过 a¹₁计算一下计算图 a²₁。
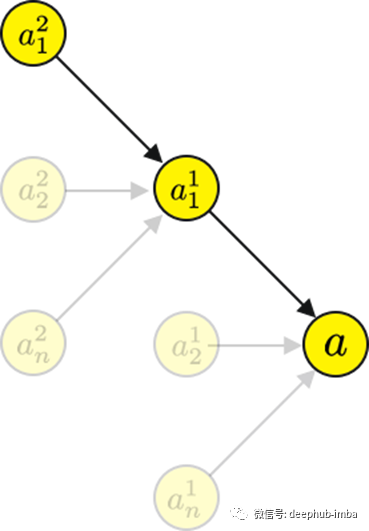
实际上你会发现两个计算图有一个很大的共同点,特别是到a¹₁。这意味着,如果一个计算已经被计算过,那么它可以在下一次和下下次被重用,依此类推。虽然这增加了内存的占用,但它显著减少了计算时间,而且对于大型神经网络来说,这是必要的。
如果我们用链式法则,得到的公式几乎是一样的,只是增加了索引。
复杂模型的进一步复杂化
你会发现一个a²₂ 会有几个路径输出层节点,。
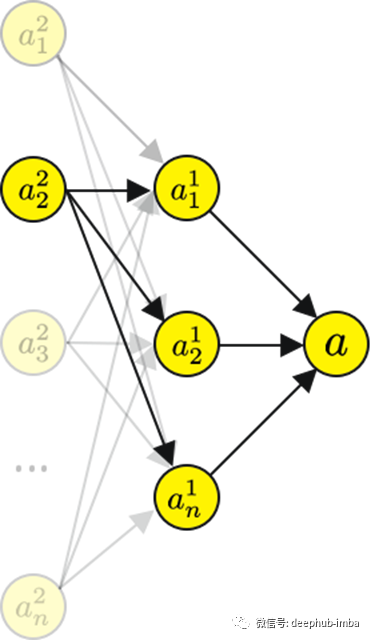
所以我们需要对前一层求和。我们从所有前面的节点和它们的梯度的总和中得到的这个值有更新它的指令,以便我们最小化损失。
最小化成本函数
如果你还记得定义6和7,特别是定义7,你会记得成本函数在概念上是预测产出和实际产出之差的平均值或加权平均值。
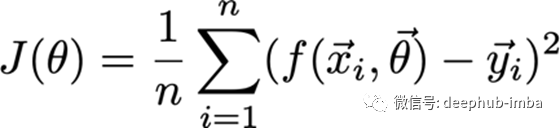
如果我们使用线性回归或逻辑回归的梯度下降算法来最小化代价函数。
对于神经网络,我们使用反向传播算法。我想现在已经很清楚为什么我们不能对神经网络使用单一方程了。神经网络并不是我们可以很好地求导数的连续函数。相反,它们近似一个函数的离散节点。因此需要一个递归算法来找到它的导数或梯度,这需要考虑到所有的节点。
完整的成本函数是这样的:
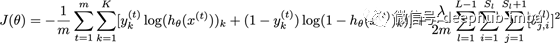
从概念上讲
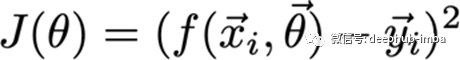
符号对符号导数
到目前为止,您已经了解了如何得到神经网络中节点梯度的代数表达式。通过链式法则在张量上的应用和计算图的概念。
代数表达式或计算图不处理具体问题,而只是给我们的理论背景,以验证我们正在正确地计算它们。它们帮助指导我们的编码。
在下一个概念中,我们将讨论符号对数值导数的影响。
符号-数值导数
这里我们开始脱离理论,进入实践领域。
算法
基本设置+计算节点的梯度
首先我们要做一些设置,包括神经网络的顺序以及与网络相关的节点的计算图。我们把它们排列好。
每个节点u^{(n)} 都与一个操作f^{(i)}相关联,使得:
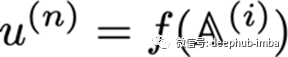
在𝔸^ {(i)}是所有节点的集合,u^ {(n)}的父节点。
首先我们需要计算所有的输入节点,为此我们需要将所有的训练数据以x向量的形式输入:
fori = 1, ...., n_i
u_i = get_u(x_i)
注意,
n_i
为输入节点数,其中输入节点为:

如果这些是输入节点,则节点:
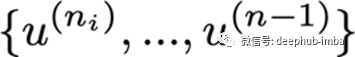
是输入节点之后最后一个节点之前的节点u^{(n)}。
fori = n_i+1, ..., n
A_i = { u_j = get_j(Pa(u_i)) }
u_i = fi(A_i)
你会注意到,这和我们链式法则计算图的概念上的方向是相反的。这是因为这部分详细说明了正向传播。
我们称这个图为:
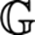
利用这个图,我们可以构造另一个图:
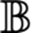
G中的每个节点计算正向图节点u^i,而B中的每个节点使用链式法则计算梯度。
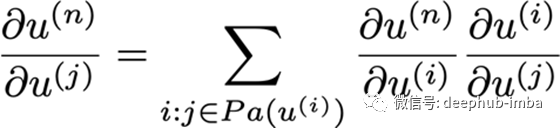
如果你考虑神经网络中的所有节点和连接它们的边,你就能想到反向传播所需的计算量随着边的数量线性增加。因为每条边都代表了一条链规则的计算,它将一些节点连接到它的一个父节点。
附加约束+简单的反向传播
如前所述,该算法的计算复杂度与网络的边数呈线性关系。但这是假设求每条边的偏导数需要一个常数时间。
在这里,我们的目标是建立一个具体反向传播算法。
Run forward propagation
这将获得处于随机的或非有用状态的网络的激活值。
Initialize grad_table
在这个数据结构中,我们将存储所有我们计算的梯度。
To get an individual entry, we use grad_table(u_i)
这将存储计算值:
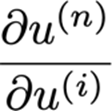
grad_table[u_n] = 1
这将最后一个节点设置为1。
forj = n-1to1
grad_table[u_j] = \\sumgrad_table[u_i] du_i/du_j
理论上是这样的:
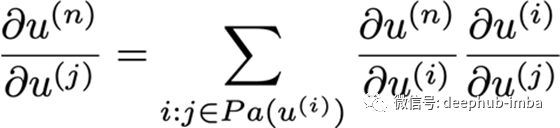
return grad_table
反向传播算法只访问每个节点一次来计算偏置,这避免了不必要的重新计算子表达式的步骤。请记住,这是以更多内存占用为代价的。
作者:Tojo Batsuuri
deephub翻译组:孟翔杰