
在这篇文章中,我们将构建一个基于LSTM的Seq2Seq模型,使用编码器-解码器架构进行机器翻译。
本篇文章内容:
- 介绍
- 数据准备和预处理
- 长短期记忆(LSTM) - 背景知识
- 编码器模型架构(Seq2Seq)
- 编码器代码实现(Seq2Seq)
- 解码器模型架构(Seq2Seq)
- 解码器代码实现(Seq2Seq)
- Seq2Seq(编码器+解码器)接口
- Seq2Seq(编码器+解码器)代码实现
- Seq2Seq模型训练
- Seq2Seq模型推理
1.介绍
神经机器翻译(NMT)是一种机器翻译方法,它使用人工神经网络来预测一个单词序列的可能性,通常在一个单一的集成模型中建模整个句子。
对于计算机来说,用一个简单的基于规则的系统从一种语言转换成另一种语言是最困难的问题之一,因为它们无法捕捉到过程中的细微差别。不久之后,我们开始使用统计模型,但在进入深度学习之后,这个领域被统称为神经机器翻译,现在已经取得了最先进的成果。
这篇文章是针对于初学者的,所以一个特定类型的架构(Seq2Seq)显示了一个好的开始,这就是我们要在这里实现的。
因此,本文中的序列对序列(seq2seq)模型使用了一种编码器-解码器架构,它使用一种名为LSTM(长短期记忆)的RNN,其中编码器神经网络将输入的语言序列编码为单个向量,也称为上下文向量。
这个上下文向量被称为包含输入语言序列的抽象表示。
然后将这个向量传递到解码器神经网络中,用解码器神经网络一个词一个词地输出相应的输出语言翻译句子。
这里我正在做一个德语到英语的神经机器翻译。但同样的概念可以扩展到其他问题,如命名实体识别(NER),文本摘要,甚至其他语言模型,等等。
2.数据准备和预处理
为了以我们想要的最佳方式获取数据,我使用了SpaCy(词汇构建)、TorchText(文本预处理)库和multi30k dataset,其中包含英语、德语和法语的翻译序列
让我们看看它能做的一些过程,
- 训练/验证/测试分割:将数据分割到指定的训练/验证/测试集。
- 文件加载:加载各种格式(.txt、.json、.csv)的文本语料库。
- 分词:把句子分解成一串单词。
- 从文本语料库生成一个词汇表列表。
- 单词编码:将单词映射为整个语料库的整数,反之亦然。
- 字向量:将字从高维转换为低维(字嵌入)。
- 批处理:生成批次的样品。
因此,一旦我们了解了torch文本可以做什么,让我们谈谈如何在torch text模块中实现它。在这里,我们将利用torchtext下的3个类。
Fields :这是torchtext下的一个类,在这里我们指定如何在我们的数据库里进行预处理。
TabularDataset:我们实际上可以定义以CSV、TSV或JSON格式存储的列数据集,并将它们映射为整数。
BucketIterator:我们可以填充我们的数据以获得近似,并使用我们的数据批量进行模型训练。
这里我们的源语言(SRC - Input)是德语,目标语言(TRG - Output)是英语。为了有效的模型训练,我们还额外增加了两个令牌“序列开始”<sos>和“序列结束”<eos>。
!pip install torchtext==0.6.0 --quiet
import torch
import torch.nn as nn
import torch.optim as optim
from torchtext.datasets import Multi30k
from torchtext.data import Field, BucketIterator
import numpy as np
import pandas as pd
import spacy, random
## Loading the SpaCy's vocabulary for our desired languages.
!python -m spacy download en --quiet
!python -m spacy download de --quiet
spacy_german = spacy.load("de")
spacy_english = spacy.load("en")
def tokenize_german(text):
return [token.text for token in spacy_german.tokenizer(text)]
def tokenize_english(text):
return [token.text for token in spacy_english.tokenizer(text)]
german = Field(tokenize=tokenize_german, lower=True,
init_token="<sos>", eos_token="<eos>")
english = Field(tokenize=tokenize_english, lower=True,
init_token="<sos>", eos_token="<eos>")
train_data, valid_data, test_data = Multi30k.splits(exts = (".de", ".en"),
fields=(german, english))
german.build_vocab(train_data, max_size=10000, min_freq=3)
english.build_vocab(train_data, max_size=10000, min_freq=3)
print(f"Unique tokens in source (de) vocabulary: {len(german.vocab)}")
print(f"Unique tokens in target (en) vocabulary: {len(english.vocab)}")
******************************* OUTPUT *******************************
Unique tokens in source (de) vocabulary: 5376
Unique tokens in target (en) vocabulary: 4556
在设置了语言预处理标准之后,下一步是使用迭代器创建成批的训练、测试和验证数据。
创建批是一个详尽的过程,幸运的是我们可以利用TorchText的迭代器库。
这里我们使用BucketIterator来有效填充源句和目标句。我们可以使用.src属性访问源(德语)批数据,使用.trg属性访问对应的(英语)批数据。同样,我们可以在标记之前看到数据。
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
BATCH_SIZE = 32
train_iterator, valid_iterator, test_iterator = BucketIterator.splits((train_data, valid_data, test_data),
batch_size = BATCH_SIZE,
sort_within_batch=True,
sort_key=lambda x: len(x.src),
device = device)
# Dataset Sneek peek before tokenizing
for data in train_data:
max_len_ger.append(len(data.src))
max_len_eng.append(len(data.trg))
if count < 10 :
print("German - ",*data.src, " Length - ", len(data.src))
print("English - ",*data.trg, " Length - ", len(data.trg))
print()
count += 1
print("Maximum Length of English Sentence {} and German Sentence {} in the dataset".format(max(max_len_eng),max(max_len_ger)))
print("Minimum Length of English Sentence {} and German Sentence {} in the dataset".format(min(max_len_eng),min(max_len_ger)))
************************************************************** OUTPUT **************************************************************
German - zwei junge weiße männer sind im freien in der nähe vieler büsche . Length - 13
English - two young , white males are outside near many bushes . Length - 11
German - ein mann in grün hält eine gitarre , während der andere mann sein hemd ansieht . Length - 16
English - a man in green holds a guitar while the other man observes his shirt . Length - 15
German - ein mann lächelt einen ausgestopften löwen an . Length - 8
English - a man is smiling at a stuffed lion Length - 8
German - ein schickes mädchen spricht mit dem handy während sie langsam die straße entlangschwebt . Length - 14
English - a trendy girl talking on her cellphone while gliding slowly down the street . Length - 14
German - eine frau mit einer großen geldbörse geht an einem tor vorbei . Length - 12
English - a woman with a large purse is walking by a gate . Length - 12
German - jungen tanzen mitten in der nacht auf pfosten . Length - 9
English - boys dancing on poles in the middle of the night . Length - 11
Maximum Length of English Sentence 41 and German Sentence 44 in the dataset
Minimum Length of English Sentence 4 and German Sentence 1 in the dataset
我刚刚试验了一批大小为32和样本批如下所示。这些句子被标记成一个单词列表,并根据词汇索引。“pad”标记的索引值为1。
每一列对应一个句子,用数字索引,在单个目标批处理中有32个这样的句子,行数对应于句子的最大长度。短句用1来填充以弥补其长度。
下表包含批处理的数字索引,这些索引稍后被输入到嵌入的单词中,并转换为密集表示,以便进行Seq2Seq处理。
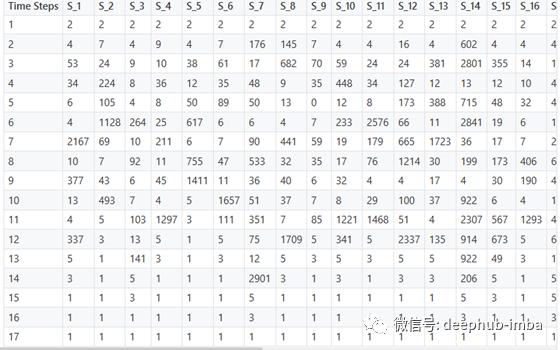
下表包含与批处理的数字索引映射的对应单词。
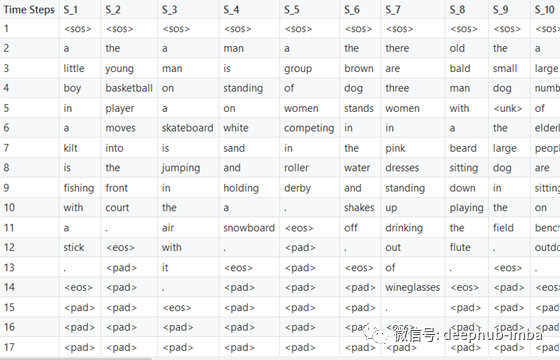
3.长短期记忆(LSTM)背景知识

上面的图片显示了在单个LSTM单元下的计算。在最后一篇文章中,我将添加一些参考资料来学习更多关于LSTM的知识,以及为什么它适用于长序列。
但简单地说,传统RNN和门控(GRU)是无法捕捉的长期依赖性因其自然消失的梯度设计和遭受严重的问题,这使得权重和偏置值的变化率可以忽略不计,导致器泛化性的降低。
但是LSTM有一些特殊的单元称为门(记忆门,忘记门,更新门),这有助于克服前面提到的问题。
在LSTM细胞内,我们有一堆小型神经网络,在最后一层有sigmoid 和TanH激活和少量矢量加法,连接,乘法操作。
Sigmoid NN→压缩0到1之间的值。说接近0的值表示忘记,而接近1的值表示记住。
EmbeddingNN→将输入的单词索引转换为单词嵌入。
TanH NN→压缩-1和1之间的值。有助于调节矢量值,使其免于爆炸至最大值或缩小至最小值。
隐藏状态和单元状态在此称为上下文向量,它们是LSTM单元的输出。输入则是输入到嵌入NN中的句子的数字索引。
4.编码器模型架构(Seq2Seq)
在开始构建seq2seq模型之前,我们需要创建一个Encoder,Decoder,并在seq2seq模型中创建它们之间的接口。
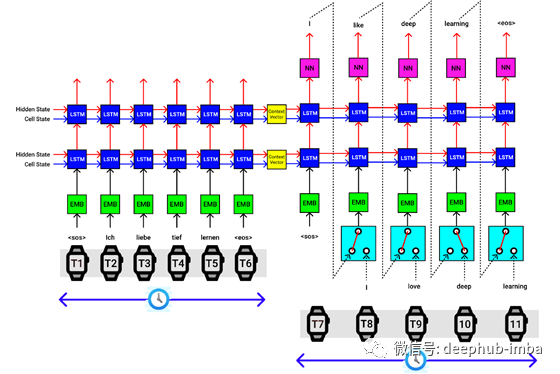
让我们通过德语输入序列“ Ich Liebe Tief Lernen”,该序列翻译成英语“ I love deep learning”。
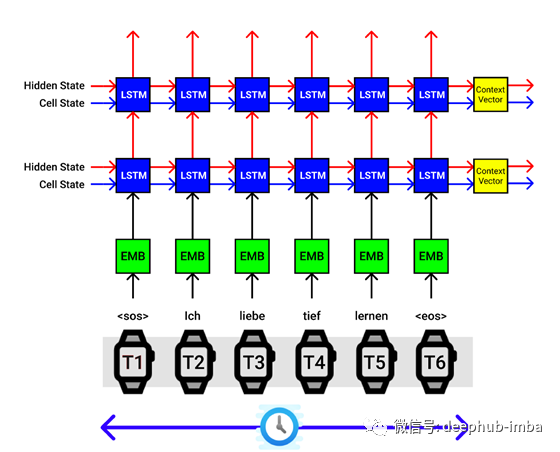
LSTM编码器体系结构。X轴对应于时间步长,Y轴对应于批量大小
为了便于说明,让我们解释上图中的过程。Seq2Seq模型的编码器一次只接受一个输入。我们输入的德语单词序列为“ ich Liebe Tief Lernen”。
另外,我们在输入句子的开头和结尾处附加序列“ SOS”的开头和句子“ EOS”标记的结尾。
因此在
- 在时间步0,发送“ SOS”
- 在时间步1,发送“ ich”
- 在时间步2,发送“ Liebe”
- 在时间步3,发送“ Tief”
- 在时间步4,发送“ Lernen”
- 在时间步5,发送“ EOS”
编码器体系结构中的第一个块是单词嵌入层(以绿色块显示),该层将输入的索引词转换为被称为词嵌入的密集向量表示(大小为100/200/300)。
然后我们的词嵌入向量被发送到LSTM单元,在这里它与隐藏状态(hs)组合,并且前一个时间步的单元状态(cs)组合,编码器块输出新的hs和cs到下一个LSTM单元。可以理解,到目前为止,hs和cs捕获了该句子的某些矢量表示。
在时间步0,隐藏状态和单元状态被完全初始化为零或随机数。
然后,在我们发送完所有输入的德语单词序列之后,最终获得上下文向量[以黄色块显示](hs,cs),该上下文向量是单词序列的密集表示形式,可以发送到解码器的第一个LSTM(hs ,cs)进行相应的英语翻译。
在上图中,我们使用2层LSTM体系结构,其中将第一个LSTM连接到第二个LSTM,然后获得2个上下文向量,这些向量堆叠在顶部作为最终输出。
我们必须在seq2seq模型中设计相同的编码器和解码器模块。
以上可视化适用于批处理中的单个句子。
假设我们的批处理大小为5,然后一次将5个句子(每个句子带有一个单词)传递给编码器,如下图所示。
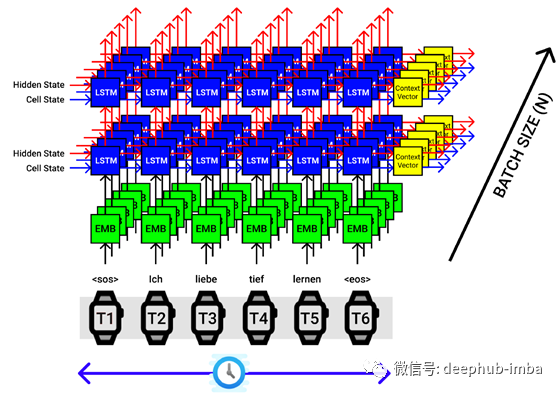
LSTM编码器的批处理大小为5。X轴对应于时间步长,Y轴对应于批处理大小。
5.编码器代码实现(Seq2Seq)
class EncoderLSTM(nn.Module):
def __init__(self, input_size, embedding_size, hidden_size, num_layers, p):
super(EncoderLSTM, self).__init__()
# Size of the one hot vectors that will be the input to the encoder
self.input_size = input_size
# Output size of the word embedding NN
self.embedding_size = embedding_size
# Dimension of the NN's inside the lstm cell/ (hs,cs)'s dimension.
self.hidden_size = hidden_size
# Number of layers in the lstm
self.num_layers = num_layers
# Regularization parameter
self.dropout = nn.Dropout(p)
self.tag = True
# Shape --------------------> (5376, 300) [input size, embedding dims]
self.embedding = nn.Embedding(self.input_size, self.embedding_size)
# Shape -----------> (300, 2, 1024) [embedding dims, hidden size, num layers]
self.LSTM = nn.LSTM(self.embedding_size, hidden_size, num_layers, dropout = p)
# Shape of x (26, 32) [Sequence_length, batch_size]
def forward(self, x):
# Shape -----------> (26, 32, 300) [Sequence_length , batch_size , embedding dims]
embedding = self.dropout(self.embedding(x))
# Shape --> outputs (26, 32, 1024) [Sequence_length , batch_size , hidden_size]
# Shape --> (hs, cs) (2, 32, 1024) , (2, 32, 1024) [num_layers, batch_size size, hidden_size]
outputs, (hidden_state, cell_state) = self.LSTM(embedding)
return hidden_state, cell_state
input_size_encoder = len(german.vocab)
encoder_embedding_size = 300
hidden_size = 1024
num_layers = 2
encoder_dropout = float(0.5)
encoder_lstm = EncoderLSTM(input_size_encoder, encoder_embedding_size,
hidden_size, num_layers, encoder_dropout).to(device)
print(encoder_lstm)
************************************************ OUTPUT ************************************************
EncoderLSTM(
(dropout): Dropout(p=0.5, inplace=False)
(embedding): Embedding(5376, 300)
(LSTM): LSTM(300, 1024, num_layers=2, dropout=0.5)
)
6.解码器模型架构(Seq2Seq)
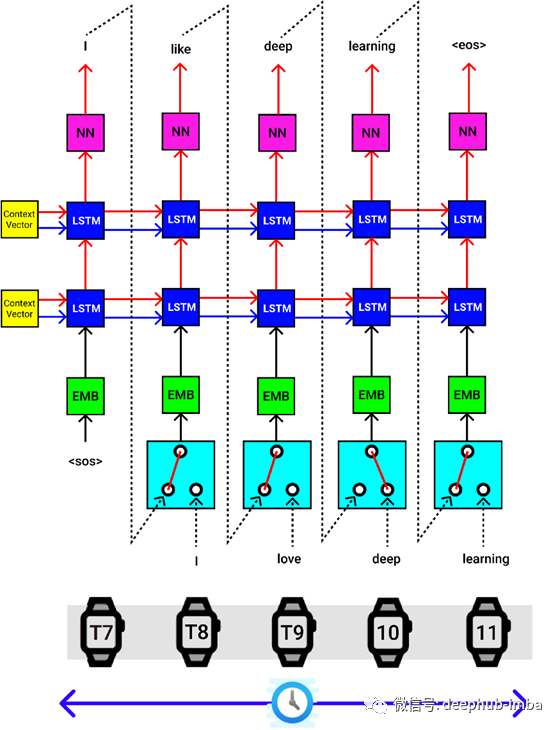
解码器一次也执行单个步骤。
提供来自编码器块的上下文向量,作为解码器的第一个LSTM块的隐藏状态(hs)和单元状态(cs)。
句子“ SOS”令牌的开头被传递到嵌入的NN,然后传递到解码器的第一个LSTM单元,最后,它经过一个线性层[以粉红色显示],该层提供输出的英语令牌预测 概率(4556个概率)[4556 —如英语的总词汇量一样],隐藏状态(hs),单元状态(cs)。
选择4556个值中概率最高的输出单词,将隐藏状态(hs)和单元状态(cs)作为输入传递到下一个LSTM单元,并执行此过程,直到到达句子“ EOS”的结尾 ”。
后续层将使用先前时间步骤中的隐藏状态和单元状态。
除其他块外,您还将在Seq2Seq架构的解码器中看到以下所示的块。
在进行模型训练时,我们发送输入(德语序列)和目标(英语序列)。从编码器获得上下文向量后,我们将它们和目标发送给解码器进行翻译。
但是在模型推断期间,目标是根据训练数据的一般性从解码器生成的。因此,将输出的预测单词作为下一个输入单词发送到解码器,直到获得<EOS>令牌。
因此,在模型训练本身中,我们可以使用 teach force ratio(暂译教力比)控制输入字到解码器的流向。
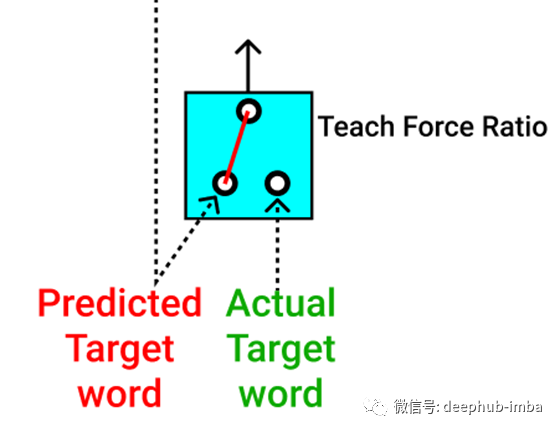
我们可以在训练时将实际的目标词发送到解码器部分(以绿色显示)。
我们还可以发送预测的目标词,作为解码器的输入(以红色显示)。
发送单词(实际目标单词或预测目标单词)的可能性可以控制为50%,因此在任何时间步长,在训练过程中都会通过其中一个。
此方法的作用类似于正则化。因此,在此过程中,模型可以快速有效地进行训练。
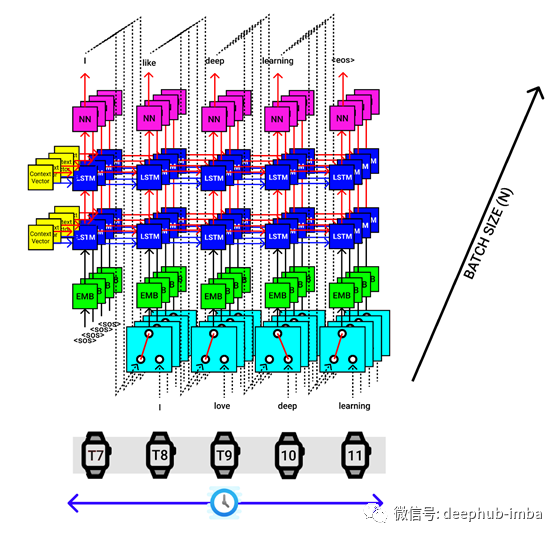
以上可视化适用于批处理中的单个句子。假设我们的批处理大小为4,然后一次将4个句子传递给编码器,该编码器提供4组上下文向量,它们都被传递到解码器中,如下图所示。
7.解码器代码实现(Seq2Seq)
class DecoderLSTM(nn.Module):
def __init__(self, input_size, embedding_size, hidden_size, num_layers, p, output_size):
super(DecoderLSTM, self).__init__()
# Size of the one hot vectors that will be the input to the encoder
self.input_size = input_size
# Output size of the word embedding NN
self.embedding_size = embedding_size
# Dimension of the NN's inside the lstm cell/ (hs,cs)'s dimension.
self.hidden_size = hidden_size
# Number of layers in the lstm
self.num_layers = num_layers
# Size of the one hot vectors that will be the output to the encoder (English Vocab Size)
self.output_size = output_size
# Regularization parameter
self.dropout = nn.Dropout(p)
self.tag = True
# Shape --------------------> (5376, 300) [input size, embedding dims]
self.embedding = nn.Embedding(self.input_size, self.embedding_size)
# Shape -----------> (300, 2, 1024) [embedding dims, hidden size, num layers]
self.LSTM = nn.LSTM(self.embedding_size, hidden_size, num_layers, dropout = p)
# Shape -----------> (1024, 4556) [embedding dims, hidden size, num layers]
self.fc = nn.Linear(self.hidden_size, self.output_size)
# Shape of x (32) [batch_size]
def forward(self, x, hidden_state, cell_state):
# Shape of x (1, 32) [1, batch_size]
x = x.unsqueeze(0)
# Shape -----------> (1, 32, 300) [1, batch_size, embedding dims]
embedding = self.dropout(self.embedding(x))
# Shape --> outputs (1, 32, 1024) [1, batch_size , hidden_size]
# Shape --> (hs, cs) (2, 32, 1024) , (2, 32, 1024) [num_layers, batch_size size, hidden_size] (passing encoder's hs, cs - context vectors)
outputs, (hidden_state, cell_state) = self.LSTM(embedding, (hidden_state, cell_state))
# Shape --> predictions (1, 32, 4556) [ 1, batch_size , output_size]
predictions = self.fc(outputs)
# Shape --> predictions (32, 4556) [batch_size , output_size]
predictions = predictions.squeeze(0)
return predictions, hidden_state, cell_state
input_size_decoder = len(english.vocab)
decoder_embedding_size = 300
hidden_size = 1024
num_layers = 2
decoder_dropout = float(0.5)
output_size = len(english.vocab)
decoder_lstm = DecoderLSTM(input_size_decoder, decoder_embedding_size,
hidden_size, num_layers, decoder_dropout, output_size).to(device)
print(decoder_lstm)
************************************************ OUTPUT ************************************************
DecoderLSTM(
(dropout): Dropout(p=0.5, inplace=False)
(embedding): Embedding(4556, 300)
(LSTM): LSTM(300, 1024, num_layers=2, dropout=0.5)
(fc): Linear(in_features=1024, out_features=4556, bias=True)
)
8.Seq2Seq(编码器+解码器)接口
单个输入语句的最终seq2seq实现如下图所示。
- 提供输入(德语)和输出(英语)句子
- 将输入序列传递给编码器并提取上下文向量
- 将输出序列传递给解码器,以及来自编码器的上下文向量,以生成预测的输出序列
以上可视化适用于批处理中的单个句子。假设我们的批处理大小为4,然后一次将4个句子传递给编码器,该编码器提供4组上下文向量,它们都被传递到解码器中,如下图所示。
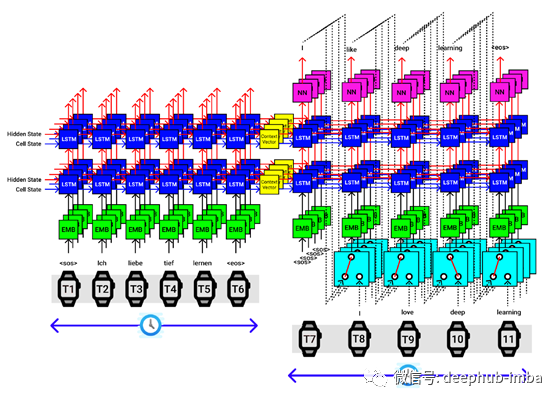
9.Seq2Seq(编码器+解码器)代码实现
class Seq2Seq(nn.Module):
def __init__(self, Encoder_LSTM, Decoder_LSTM):
super(Seq2Seq, self).__init__()
self.Encoder_LSTM = Encoder_LSTM
self.Decoder_LSTM = Decoder_LSTM
def forward(self, source, target, tfr=0.5):
# Shape - Source : (10, 32) [(Sentence length German + some padding), Number of Sentences]
batch_size = source.shape[1]
# Shape - Source : (14, 32) [(Sentence length English + some padding), Number of Sentences]
target_len = target.shape[0]
target_vocab_size = len(english.vocab)
# Shape --> outputs (14, 32, 5766)
outputs = torch.zeros(target_len, batch_size, target_vocab_size).to(device)
# Shape --> (hs, cs) (2, 32, 1024) ,(2, 32, 1024) [num_layers, batch_size size, hidden_size] (contains encoder's hs, cs - context vectors)
hidden_state_encoder, cell_state_encoder = self.Encoder_LSTM(source)
# Shape of x (32 elements)
x = target[0] # Trigger token <SOS>
for i in range(1, target_len):
# Shape --> output (32, 5766)
output, hidden_state_decoder, cell_state_decoder = self.Decoder_LSTM(x, hidden_state_encoder, cell_state_encoder)
outputs[i] = output
best_guess = output.argmax(1) # 0th dimension is batch size, 1st dimension is word embedding
x = target[i] if random.random() < tfr else best_guess # Either pass the next word correctly from the dataset or use the earlier predicted word
# Shape --> outputs (14, 32, 5766)
return outputs
print(model)
************************************************ OUTPUT ************************************************
Seq2Seq(
(Encoder_LSTM): EncoderLSTM(
(dropout): Dropout(p=0.5, inplace=False)
(embedding): Embedding(5376, 300)
(LSTM): LSTM(300, 1024, num_layers=2, dropout=0.5)
)
(Decoder_LSTM): DecoderLSTM(
(dropout): Dropout(p=0.5, inplace=False)
(embedding): Embedding(4556, 300)
(LSTM): LSTM(300, 1024, num_layers=2, dropout=0.5)
(fc): Linear(in_features=1024, out_features=4556, bias=True)
)
)
10.Seq2Seq模型训练
epoch_loss = 0.0
num_epochs = 100
best_loss = 999999
best_epoch = -1
sentence1 = "ein mann in einem blauen hemd steht auf einer leiter und putzt ein fenster"
ts1 = []
for epoch in range(num_epochs):
print("Epoch - {} / {}".format(epoch+1, num_epochs))
model.eval()
translated_sentence1 = translate_sentence(model, sentence1, german, english, device, max_length=50)
print(f"Translated example sentence 1: \n {translated_sentence1}")
ts1.append(translated_sentence1)
model.train(True)
for batch_idx, batch in enumerate(train_iterator):
input = batch.src.to(device)
target = batch.trg.to(device)
# Pass the input and target for model's forward method
output = model(input, target)
output = output[1:].reshape(-1, output.shape[2])
target = target[1:].reshape(-1)
# Clear the accumulating gradients
optimizer.zero_grad()
# Calculate the loss value for every epoch
loss = criterion(output, target)
# Calculate the gradients for weights & biases using back-propagation
loss.backward()
# Clip the gradient value is it exceeds > 1
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1)
# Update the weights values using the gradients we calculated using bp
optimizer.step()
step += 1
epoch_loss += loss.item()
writer.add_scalar("Training loss", loss, global_step=step)
if epoch_loss < best_loss:
best_loss = epoch_loss
best_epoch = epoch
checkpoint_and_save(model, best_loss, epoch, optimizer, epoch_loss)
if ((epoch - best_epoch) >= 10):
print("no improvement in 10 epochs, break")
break
print("Epoch_Loss - {}".format(loss.item()))
print()
print(epoch_loss / len(train_iterator))
score = bleu(test_data[1:100], model, german, english, device)
print(f"Bleu score {score*100:.2f}")
************************************************ OUTPUT ************************************************
Bleu score 15.62
例句训练进度:

训练损失:
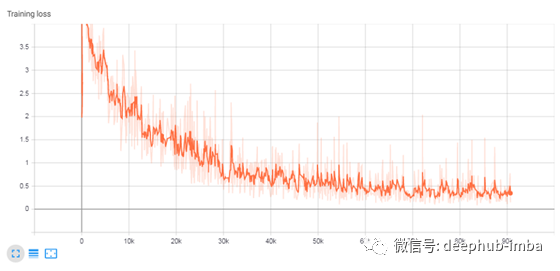
11.Seq2Seq模型推理
现在,让我们将我们训练有素的模型与SOTA Google Translate的模型进行比较。

model.eval()
test_sentences = ["Zwei Männer gehen die Straße entlang", "Kinder spielen im Park.",
"Diese Stadt verdient eine bessere Klasse von Verbrechern. Der Spaßvogel"]
actual_sentences = ["Two men are walking down the street", "Children play in the park",
"This city deserves a better class of criminals. The joker"]
pred_sentences = []
for idx, i in enumerate(test_sentences):
model.eval()
translated_sentence = translate_sentence(model, i, german, english, device, max_length=50)
progress.append(TreebankWordDetokenizer().detokenize(translated_sentence))
print("German : {}".format(i))
print("Actual Sentence in English : {}".format(actual_sentences[idx]))
print("Predicted Sentence in English : {}".format(progress[-1]))
print()
******************************************* OUTPUT *******************************************
German : "Zwei Männer gehen die Straße entlang"
Actual Sentence in English : "Two men are walking down the street"
Predicted Sentence in English : "two men are walking on the street . <eos>"
German : "Kinder spielen im Park."
Actual Sentence in English : "Children play in the park"
Predicted Sentence in English : "children playing in the park . <eos>"
German : "Diese Stadt verdient eine bessere Klasse von Verbrechern. Der Spaßvogel"
Actual Sentence in English : "This city deserves a better class of criminals. The joker"
Predicted Sentence in English : "this <unk>'s <unk> from a <unk> green team <unk> by the sidelines . <eos>"
不错,但是很明显,该模型不能理解复杂的句子。因此,在接下来的系列文章中,我将通过更改模型的体系结构来提高上述模型的性能,例如使用双向LSTM,添加注意力机制或将LSTM替换为Transformers模型来克服这些明显的缺点。
希望我能够对Seq2Seq模型如何处理数据有一些直观的了解,在评论部分告诉我您的想法。
作者:Balakrishnakumar V
deephub翻译组