
VQ-VAE 是变分自编码器(VAE)的一种改进。这些模型可以用来学习有效的表示。本文将深入研究 VQ-VAE 之前,不过,在这之前我们先讨论一些概率基础和 VAE 架构。
后验和先验分布

证据下界(ELBO)
在机器学习模型中,大多数后验分布都相当复杂。我们使用变分推理这一基于优化的方法来近似这些分布。ELBO 是变分推理中一个至关重要的目标函数。其推导方式如下。


重构项用于评估解码器从潜在变量重构输入的能力。KL散度项则充当正则化机制。
变分自编码器(VAE)
标准的自编码器将输入映射到潜在空间中的单个点。然而,VAE的编码器输出概率分布的参数(均值和方差)。模型从这个分布中采样一个点,然后将其输入到解码器中。
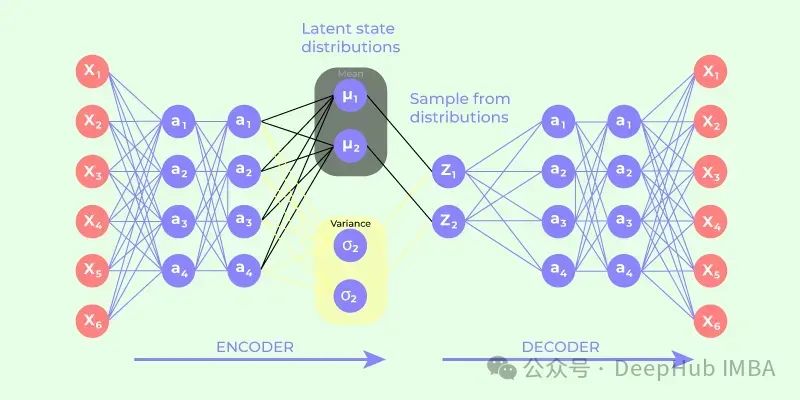
我们使用ELBO作为损失函数。
VAE存在后验崩溃的问题:模型中的正则化项开始主导损失函数,后验分布变得与先验分布相似。解码器变得过于强大,忽略了潜在表示。因此后验分布将不包含有关潜在变量的信息。
在VQ-VAE中,通过矢量量化步骤避免了后验崩溃。
矢量量化变分自编码器(VQ-VAE)
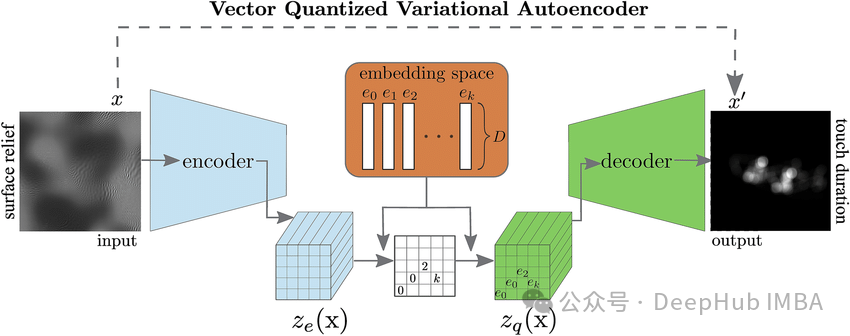
离散表示可以有效地用来提高机器学习模型的性能。人类语言本质上是离散的,使用符号表示。我们可以使用语言来解释图像。因此在机器学习中使用潜在空间的离散表示是一个自然的选择。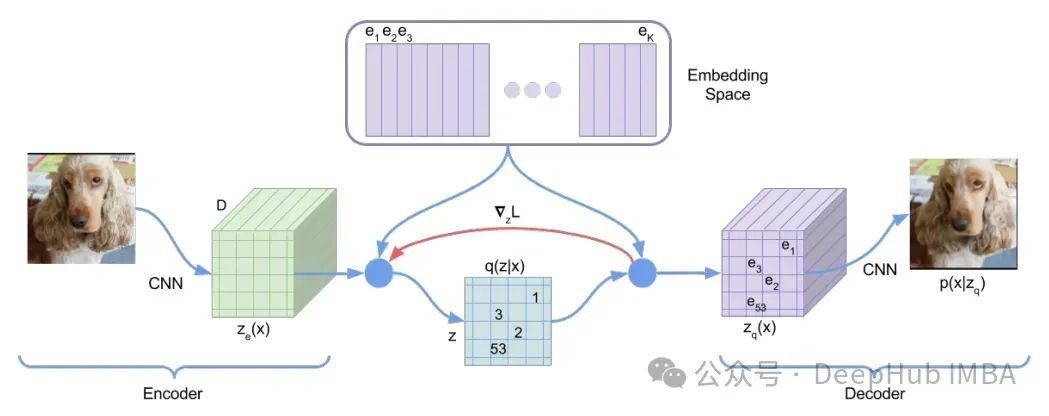
首先,编码器生成嵌入。然后从码本中为给定嵌入选择最佳近似。码本由离散向量组成。使用L2距离进行最近邻查找。
在反向传播过程中,通过嵌入选择步骤的梯度流动并非易事。编码器的输出嵌入和解码器的输入嵌入具有相同的维度。所以直接将解码器输入的梯度复制到编码器输出(红色箭头)。这样可以产生一个良好的梯度近似。
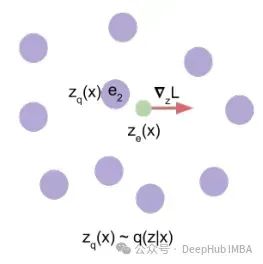
在训练过程中,梯度可以推动编码器嵌入(绿色圆圈)靠近不同的离散表示(紫色圆圈)。
优化编码器、解码器和嵌入(即码本)。损失函数可以用以下方式表达。
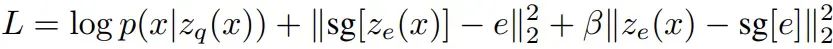
第一个术语是重构损失(类似于标准的VAE)。它衡量解码器在生成与输入分布相似的输出方面的表现。如果输入是正态分布的,这一项将是简单的均方误差。
sg 是停止梯度操作符,用来停止参数学习。由于从解码器到编码器的直接路径,重构损失项不会向嵌入提供学习信号。所以使用第二项来优化码本,将嵌入推向编码器表示。
第三项是commitment损失。它防止嵌入任意增长。
解码器仅由第一项优化。第一项和第三项优化编码器。第二项优化码本。
在训练期间,先验保持均匀。因此,ELBO的KL散度项是恒定的。

Pytorch实现
矢量量化器可以通过以下方式实现。
classVectorQuantizer(nn.Module):
def__init__(self, num_embeddings, embedding_dim, commitment_cost):
super(VectorQuantizer, self).__init__()
self._embedding_dim=embedding_dim
self._num_embeddings=num_embeddings
self._embedding=nn.Embedding(self._num_embeddings, self._embedding_dim)
self._embedding.weight.data.uniform_(-1/self._num_embeddings, 1/self._num_embeddings)
self._commitment_cost=commitment_cost
defforward(self, inputs):
# convert inputs from BCHW -> BHWC
inputs=inputs.permute(0, 2, 3, 1).contiguous()
input_shape=inputs.shape
# Flatten input
flat_input=inputs.view(-1, self._embedding_dim)
# Calculate distances
distances= (torch.sum(flat_input**2, dim=1, keepdim=True)
+torch.sum(self._embedding.weight**2, dim=1)
-2*torch.matmul(flat_input, self._embedding.weight.t()))
# Encoding
encoding_indices=torch.argmin(distances, dim=1).unsqueeze(1)
encodings=torch.zeros(encoding_indices.shape[0], self._num_embeddings, device=inputs.device)
encodings.scatter_(1, encoding_indices, 1)
# Quantize and unflatten
quantized=torch.matmul(encodings, self._embedding.weight).view(input_shape)
# Loss
e_latent_loss=F.mse_loss(quantized.detach(), inputs)
q_latent_loss=F.mse_loss(quantized, inputs.detach())
loss=q_latent_loss+self._commitment_cost*e_latent_loss
quantized=inputs+ (quantized-inputs).detach()
avg_probs=torch.mean(encodings, dim=0)
perplexity=torch.exp(-torch.sum(avg_probs*torch.log(avg_probs+1e-10)))
# convert quantized from BHWC -> BCHW
returnloss, quantized.permute(0, 3, 1, 2).contiguous(), perplexity, encodings
我们将输入扁平化,并保持嵌入空间的维数为_embedding_dim。假设输入为 16,32,32,64 BHWC/ batch, height, width, channels 。被压扁成[16384,64]。
# Flatten input
flat_input = inputs.view(-1, self._embedding_dim)
然后计算从每个嵌入向量到每个码本向量的距离的平方。假设(N, D)是编码器的输出,(K, D)是码本。得到(N, K)大小的结果。
distances = (torch.sum(flat_input**2, dim=1, keepdim=True)
+ torch.sum(self._embedding.weight**2, dim=1)
- 2 * torch.matmul(flat_input, self._embedding.weight.t()))
接下来,我们跨dim = 1(跨码本)执行简单的argmin,获得与编码器输出距离最小的嵌入。我们生成N个大小为K的一元向量。
encoding_indices = torch.argmin(distances, dim=1).unsqueeze(1)
encodings = torch.zeros(encoding_indices.shape[0], self._num_embeddings, device=inputs.device)
将嵌入表与这个独热向量相乘以提取最接近的码本向量。这就是量化过程。
接下来定义损失项(重建损失除外)。Mse代表均方误差,.detach作为停止梯度操作。
e_latent_loss = F.mse_loss(quantized.detach(), inputs)
q_latent_loss = F.mse_loss(quantized, inputs.detach())
loss = q_latent_loss + self._commitment_cost * e_latent_loss
最后确保梯度可以直接从解码器流向编码器。
quantized = inputs + (quantized - inputs).detach()
从数学上讲,左右两边是相等的(+输入和-输入将相互抵消)。在反向传播过程中,.detach部分将被忽略
以上就是VQ VAE的完整实现,原始的完整代码可以在这里找到:
最后论文:ArXiv. /abs/1711.00937
作者:Kavishka Abeywardana