
时间序列分析中包含了许多复杂的数学公式,它们往往难以留存于记忆之中。为了更好地掌握这些内容,本文将整理并总结时间序列分析中的一些核心概念,如自协方差、自相关和平稳性等,并通过Python实现和图形化展示这些概念,使其更加直观易懂。希望通过这篇文章帮助大家更清楚地理解时间序列分析的基础框架和关键点。
1、什么是时间序列?-自协方差、自相关和平稳性
时间序列与时间有关,随着时间的推移观察到的数据称为时间序列数据:例如,心率监测,每日最高温度等。虽然这些例子是有规律的间隔观察到的,但也有不规则间隔观察到的时间序列数据,如盘中股票交易、临床试验等。我们将使用定期观察跨度的时间序列数据,并且只有一个变量(单变量时间序列)。从数学上我们可以这样定义时间序列:
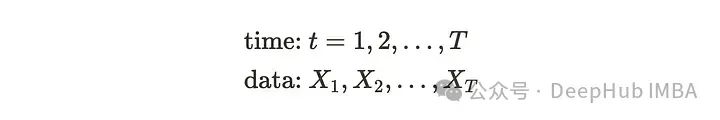
如果我们把X _l看作一个随机变量,可以定义一个依赖于观测时间t的均值和方差。
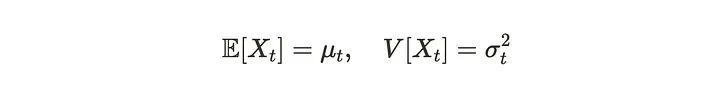
对于时间序列数据,可能想要比较过去和当前的数据。所以就引出了两个基本概念,自协方差和自相关
自协方差
从技术上讲,自协方差和协方差是一样的。协方差有如下公式:
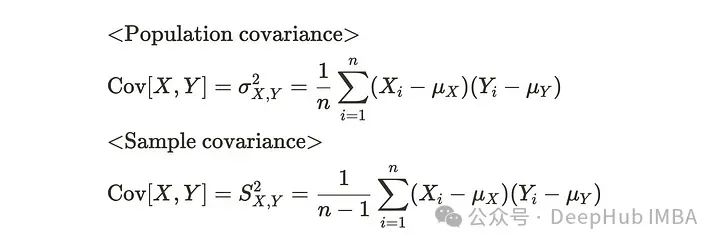
协方差计算两个变量X和y之间的关系。在计算样本协方差时,我们将每个观测值与平均值之间的差除以n-1,类似于样本方差。对于自协方差则计算前一个观测值与当前观测值之间的样本协方差。公式如下:
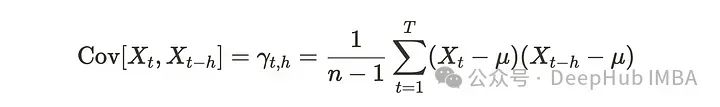
这里的h被称为滞后。滞后的X是前一个X值偏移了h位置。所以公式与协方差相同。
自相关
自相关也和相关一样,相关关系有如下公式。
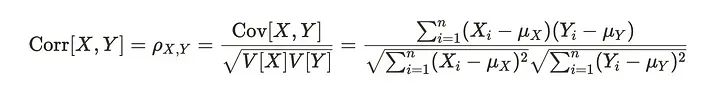
相关性将协方差除以变量X和y的标准差,我们可以认为相关性类似于标准化协方差除以标准差。对于自相关,计算以前和当前观测值之间的相关性。h在公式中也表示滞后性。
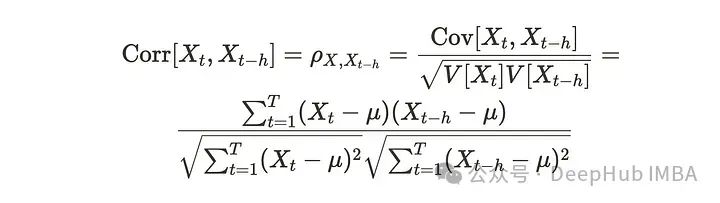
当协方差和相关取较大的正值时,X和Y两个变量呈正相关关系。那么自协方差和自相关呢?我们来看看可视化。
对于第一个示例,从AR(1)流程生成数据(稍后我们将看到它)。它看起来像嘈杂的数据。
在这种情况下,自协方差和自相关图如下图所示。x轴表示滞后。
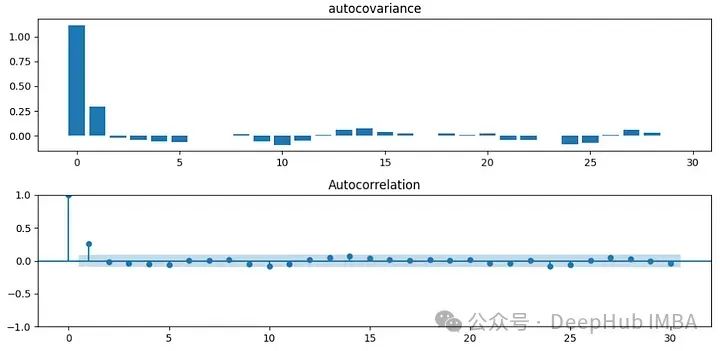
可以看到自协方差和自相关有相似的趋势。因此可以想象自相关可以被认为是标准化的自协方差。
对于下面的示例将使用真实世界的数据,例如AirPassengers[4]。airpassenger数据有明显的上升趋势。
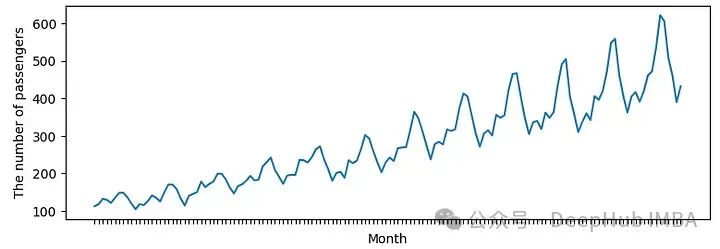
自协方差和自相关图如下图所示。x轴表示滞后。
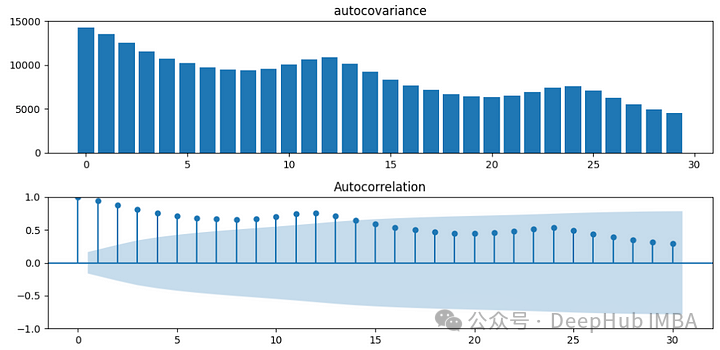
自协方差和自相关也有类似的趋势。这个数据比第一个例子有更多的相关性和更大的滞后。
我们了解了两个关键概念,自协方差和自相关。接下来,我们讨论一个叫做平稳性的新概念。平稳时间序列意味着数据属性,如均值、方差和协方差,不依赖于观测时间。平稳性有两种类型:
弱平稳(二阶平稳)
该过程具有以下关系,称为弱平稳性,二阶平稳性或协方差平稳性。(有很多称呼它的方式。)
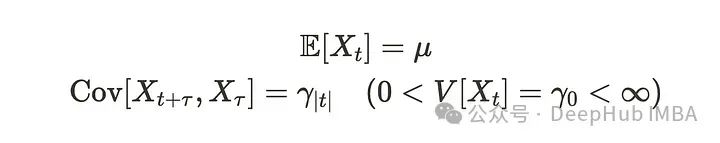
其中µ是常数,且 𝛾ₜ 不依赖于𝛕。这些公式表明,随着时间的推移,均值和方差是稳定的,协方差取决于时滞。例如,上一段中的第一个例子具有弱平稳性。
严格平稳性(强平稳性)
令Fx(・)表示联合密度函数时,严格平稳性描述为:
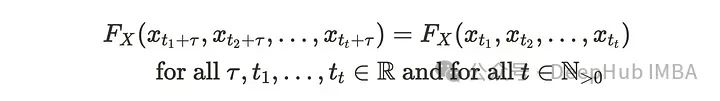
如果所有时间序列数据的联合分布不随时间的变化而变化,则该时间序列具有严格的平稳性。严格平稳意味着弱平稳。这个性质在现实世界中是非常受限的。因此许多应用程序依赖于弱平稳性。
有一些统计检验来检验时间序列数据是否平稳,我们后面进行介绍
2、时间序列过程
我们将介绍代表性的时间序列过程,如白噪声、自回归(AR)、移动平均(MA)、ARMA和ARIMA过程。
白噪声
当我们拥有具有以下属性的时间序列数据时,该时间序列数据具有白噪声。
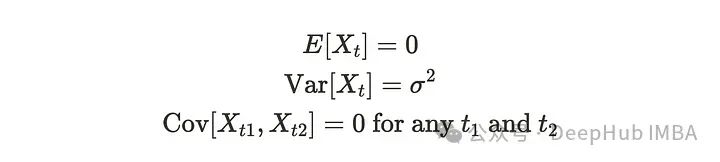
白噪声的均值为零,其方差在时间步长上是相同的。它具有零协方差,这意味着时间序列与其滞后版本是不相关的。所以自相关也是零。一般用于时间序列回归分析中残差项满足的假设。白噪声图如下图所示。
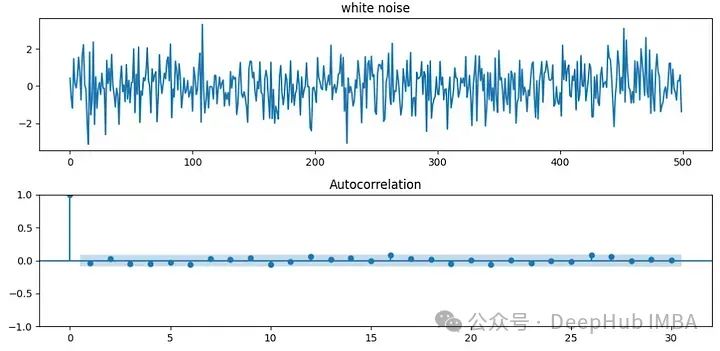
我们可以很容易地从标准正态分布中抽样产生白噪声序列。正如你所看到的,除了滞后0之外,似乎没有任何相关性,随着时间的推移,方差似乎几乎相同,平均值似乎为零。
自回归(AR)的过程
一些时间序列数据的值与前面步骤的值相似。在这种情况下,自回归(AR)过程可以很好地解释数据。AR过程有一个表示序列中先前值的数量的顺序,该顺序用于预测当前值。我们用AR(order)表示。下式表示AR(1)过程。
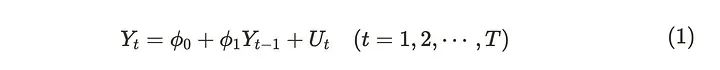
Uₜ假定为白噪声,𝜙来说是一个未知参数对应于一步前一个值。它也被称为shock。当我们沿着前面的步骤解(1)式时,可以得到下面的公式。
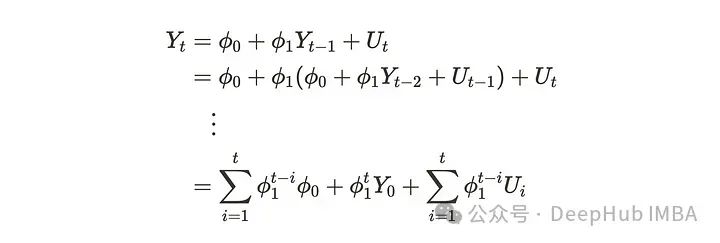
由上式可知,𝜙ᵗ₁仅影响Y系列。由此,可以认识到以下几点:
如果| 𝜙₁ | < 1,则过去值的影响随着步骤的增加而变小。
如果| 𝜙₁| = 1,无论滞后与否,过去值的影响是恒定的。
如果| 𝜙₁| > 1,则随着步骤的推移,过去值的影响会影响当前值。
让我们看看每种情况的可视化。
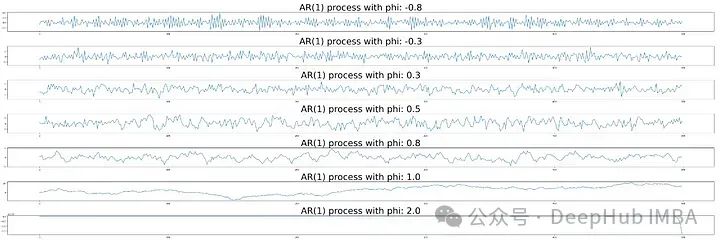
随着𝜙₁值变大,当前一级跟随前一级的值随着值的增加,它看起来更平滑,直到𝜙₁ = 1。当𝜙₁值大于1时,这些值会像无穷大一样增加,所以序列看起来像最终的结果。
注意:| 𝜙₁ | < 1的情况有弱平稳过程。当AR(1)过程满足弱平稳性时,均值和协方差为:
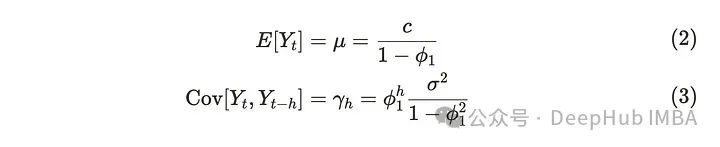
对于平均值,我们使用随时间变化的平均值作为常数。利用白噪声的平均值为零的事实,可以推导出如下公式:
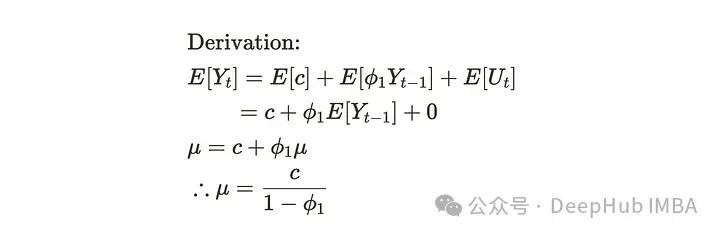
对于协方差,我们需要先改变公式(1)

然后,按这个顺序推导方差和协方差。对于方差,可以通过对上述推导公式取平方来推导。
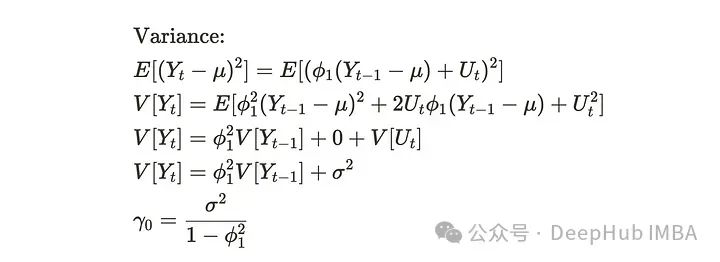
对于协方差,可以通过将前一步值减去平均值来推导。
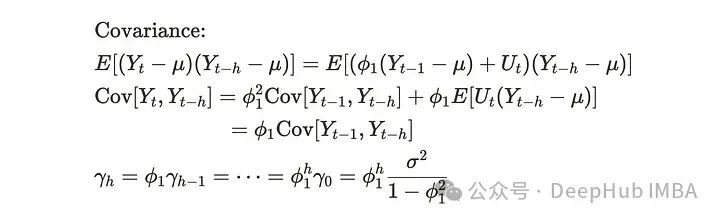
可以类似地考虑AR(p)过程。
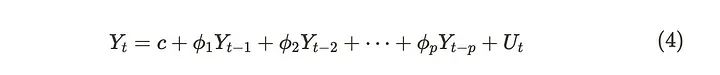
一般情况下,当满足(5)(6)条件时,AR(p)过程是弱平稳的。
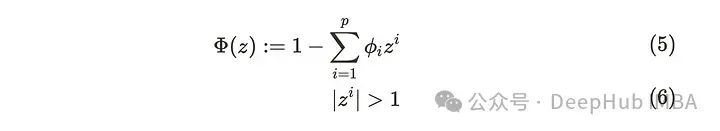
公式(5)和(6)意味着所有的根公式(5)必须在单位圆之外。尽管我们可以扩展p值,但在现实世界中先考虑几个步骤就足够了。
2、移动平均线(MA)过程
移动平均线(MA)过程由当前和以前的shock的总和组成。MA过程有一个表示先前残差或shock(Uₜ)的数量的顺序。我们用MA(阶)来表示。为简单起见,我们介绍MA(1)流程。下式表示MA(1)过程。
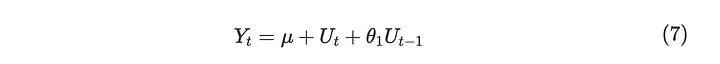
假设U₁为白噪声,θ₁为未知参数,对应前一步shock。MA(1)过程由白噪声组成,其均值始终为µ。另一方面,方差和协方差可以推导为:
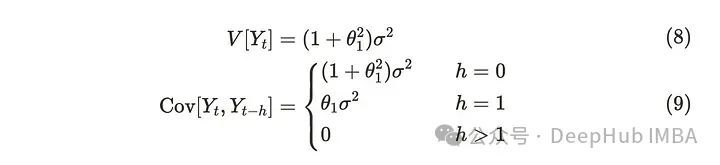
可以推导出方差如下:
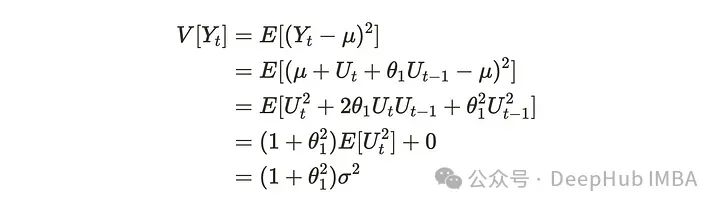
同样可以推导出协方差如下:
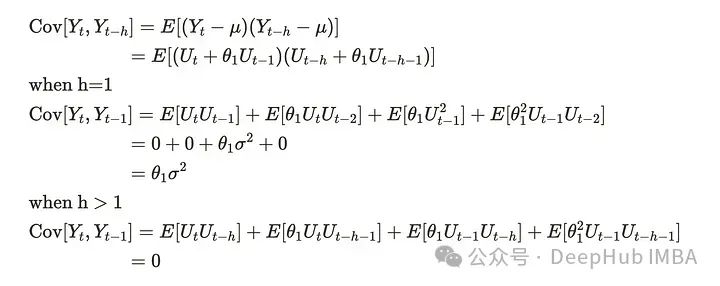
白噪声假设每个变量是相互独立的,所以可以消去它们。因此对于任意参数θ₁,MA(1)过程都是弱平稳过程。现在用可视化的方法来验证一下。
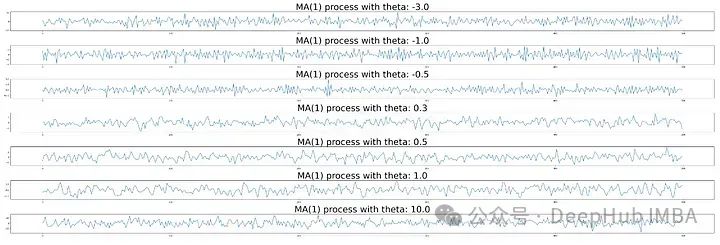
与AR(1)过程相比,均值和方差似乎保持不变。随着参数值的增大,序列变得相对平滑。注意MA(1)过程和白噪声方差不同。
一般来说,MA(q)过程也是弱平稳的。
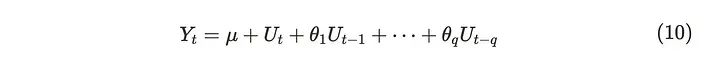
均值和协方差可以表示为:
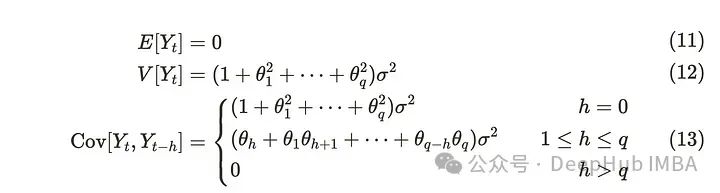
尽管我们可以扩展q值,但考虑现实世界中的前几个步骤就足够了。
3、自回归移动平均(ARMA)过程和ARIMA过程
顾名思义,自回归移动平均(ARMA)过程结合了AR和MA过程。直观上,ARMA过程可以相互弥补缺点,在表示数据时获得更大的灵活性。数学表示如下:
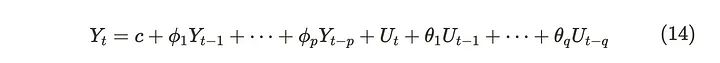
我们将ARMA过程记为ARMA(p, q),参数p和q对应于AR和MA过程的参数。由于MA过程总是具有弱平稳性,因此ARMA过程的弱平稳性取决于AR部分。所以式(14)的AR部分满足式(5)(6),其平稳性较弱。
通过可视化来检查它是如何看起来像ARMA过程的。AR(p=1,q=1)过程如下:
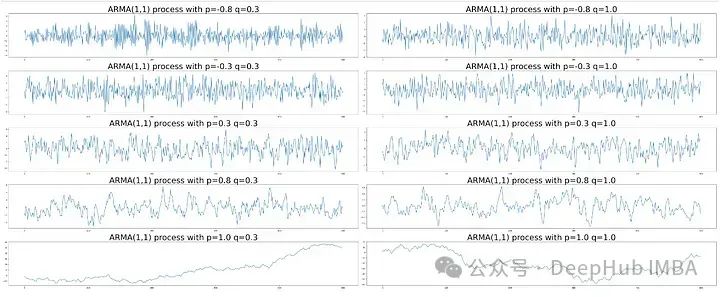
AR(p=3, q=2)过程如下图所示。
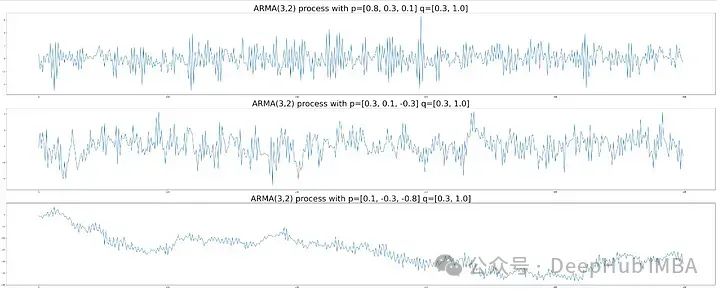
可以看到它可以比单独的AR和MA过程更好地掌握更复杂的数据结构。参数值越大,图形越平滑。
最后自回归积分移动平均(ARIMA)过程与ARMA过程有一些共同之处。不同之处在于ARIMA有一个积分部分(I),积分部分是指为了获得平稳性需要对数据进行差分的次数。
首先,我们定义差分算子∇:
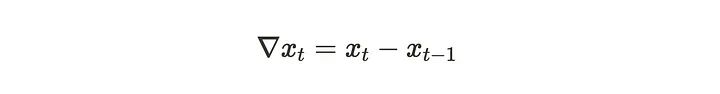
当想要更多的差分时,可以通过迭代将其扩展到幂:
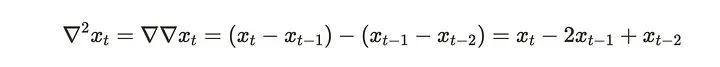
使用差分参数,可以将ARIMA(p, d, q)过程定义为:
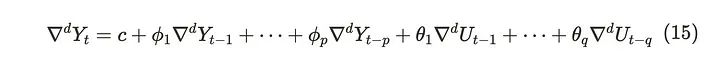
p为AR过程的阶数,d为待微分的次数,q为MA过程的阶数。在对数据进行区分之后,ARIMA过程就变成了ARMA过程。当时间序列的平均值不同时,ARIMA过程是有用的,这意味着时间序列不是平稳的。我们这里使用的是AirPassengers数据集。因为不是所有序列的均值都相同,当我们对这个系列应用nabla时,图形看起来如下所示:
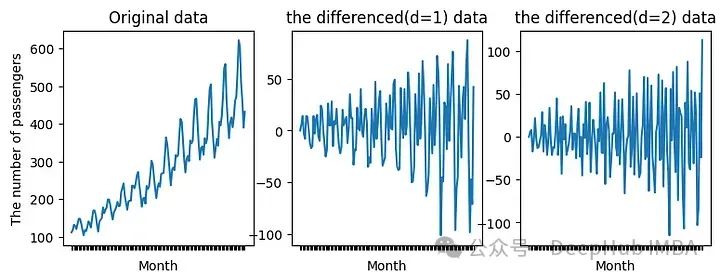
与左图的原始数据相比,右图的平均值在时间序列中似乎是稳定的。
还有最后一个问题,我们想要在微分后拟合ARMA过程,如何定义参数?
有一些方法来确定它们如下。
用自相关函数(ACF)图确定MA过程的阶数(q),用部分自相关函数(PACF)图确定AR过程的阶数(p),或使用AIC或BIC来确定最佳拟合参数。
第一种方法,我们使用ACF和PACF图来确定MA和AR过程的顺序。PACF也是自相关的,但是在0 < n < k的范围内,消除了滞后n的Y′′和Y′′+ₖ之间的间接相关关系。我们有时不能仅用图来确定参数,所以使用第二种方法。AIC和BIC是用来估计相对于其他模型的模型质量的信息标准。借助库pmdarima[7],可以很容易地根据上述信息标准找到最佳参数。例如,当使用pmdarima来估计AirPassengers数据时,结果将如下所示。
# fit stepwise auto-ARIMA
arima = pm.auto_arima(y_train, start_p=1, start_q=1,
max_p=3, max_q=3, # m=12,
seasonal=False,
d=d, trace=True,
error_action='ignore', # don't want to know if an order does not work
suppress_warnings=True, # don't want convergence warnings
stepwise=True) # set to stepwise
arima.summary()
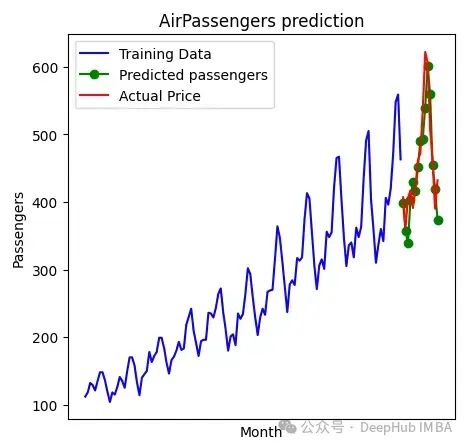
只需写几行代码,就可以很好地拟合和预测数据。此外pmdarima可以使用更高级的模型(如SARIMA)来估计时间序列。所以pmdarima在实际用例中非常有用。
3、时间序列的统计检验
最后我门将介绍两个著名的时间序列统计检验。这些检验通常用于检查数据是否平稳或残差项是否具有自相关。在深入每个测试之前,有一个重要的概念叫做单位根。如果时间序列有单位根,它就不是平稳的。如果AR(p)过程满足式(5)= 1的至少一个根,这意味着AR(p)过程不是平稳的,所以可以说AR(p)过程具有单位根的。有几个统计测试使用了这个概念。
增强Dickey-Fuller(ADF)检验
增强的Dickey-Fuller (ADF)检验评估在给定的单变量时间序列中是否存在单位根。
ADF检验采用由式(10)导出的下式。
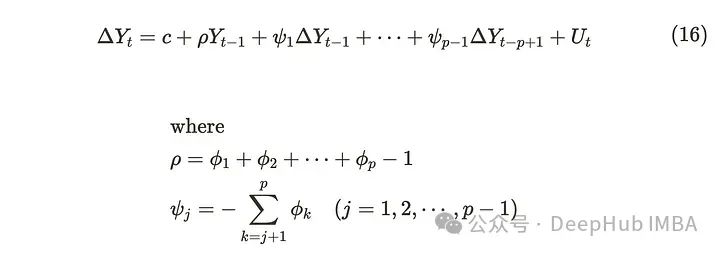
然后,它设置以下零假设和备择假设。
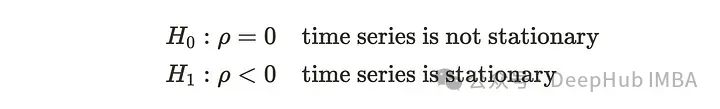
统计数据如下公式所示。
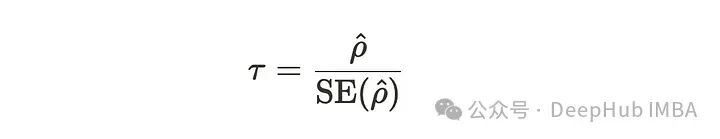
当时间序列平稳时,分子必须为负。有几个库允许我们计算ADF测试,因此不需要自己实现它们。下面的示例显示了三个时间序列数据示例。左边的是AR(1)过程,中间的是MA(1)过程,最后一个是AirPassenger数据集。图标题显示ADF检验的进程名和p值。
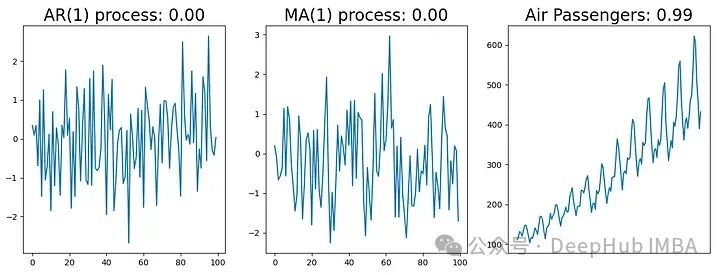
平稳数据(左和中)小于阈值的显著性,因此我们可以拒绝零假设,这意味着数据是平稳的。非平稳数据(右)比阈值更大,所以我们不能拒绝零假设,这意味着数据不是平稳的。
Durbin-Watson检验
Durbin-Watson检验用于评价时间序列回归模型中残差项是否具有自相关性。当我们使用时间序列假设以下回归模型时,我们可以使用最小二乘法估计参数。
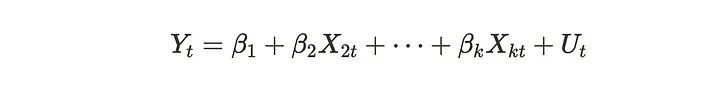
如果Uₜ不遵循白噪声,模型质量就不好。可以考虑Uₜ具有某种自相关或序列相关,我们应该将它们包含在我们的模型中。为了验证这一点,我们可以使用Durbin-Watson测试。Durbin-Watson检验假设残差项具有AR(1)模型。
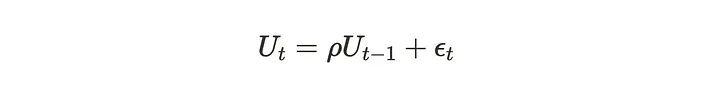
然后设置以下零假设和备择假设。
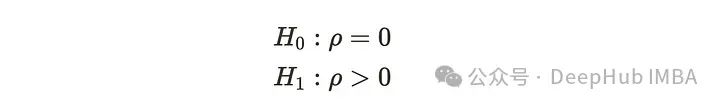
我们使用下面的统计。
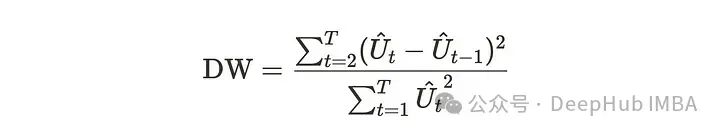
这个公式可能不太直观,所以我们把它改一下。我们假设T对于下面的关系足够大。
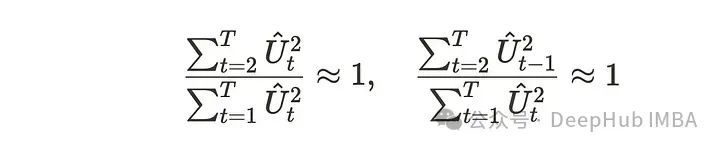
我们将Durbin-Watson统计量变换为:
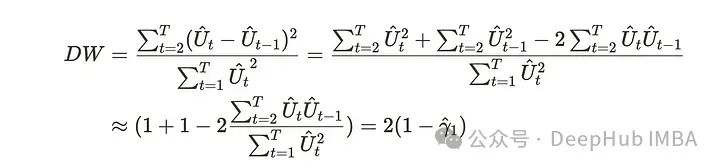
𝛾表示一阶自相关。当自相关趋近于0时,DW统计量趋近于2,这意味着时间序列中几乎没有自相关。如果时间序列中存在自相关,则DW统计量小于2。
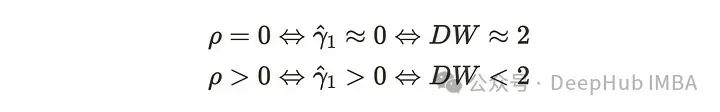
让我们使用在2.4节中创建的ARIMA模型检查DW统计量。
from statsmodels.stats.stattools import durbin_watson
arima = pm.arima.ARIMA(order=(2,1,2))
arima.fit(y_train)
dw = durbin_watson(arima.resid())
print('DW statistic: ', dw)
# DW statistic: 1.6882339836228373
DW统计量小于2,因此仍然存在自相关或序列相关。下面的残差图显示残差仍然有一定的相关性。
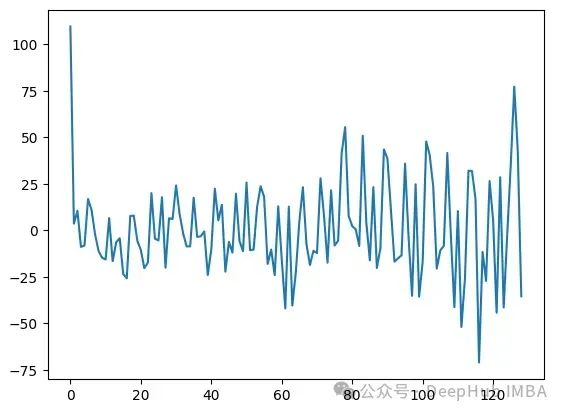
在这种情况下,我们需要使用更高级的模型来正确拟合数据。例如SARIMA,循环神经网络,prophets等。
引用
[1] 統計検定準一級
[2] Wang, D., Lecture Notes, University of South Carolina
[3] Buteikis, A., 02 Stationary time series
[4] AirPassengers dataset, kaggle
[5] Eshel, G., The Yule Walker Equations for the AR coefficients
[6] Bartlett, P., Introduction to Time Series Analysis. Lecture 12, Berkeley university
[7] pmdarima: ARIMA estimators for Python
作者:Yuki Shizuya