
Deephub
更多文章请关注公众号:Deephub-IMBA
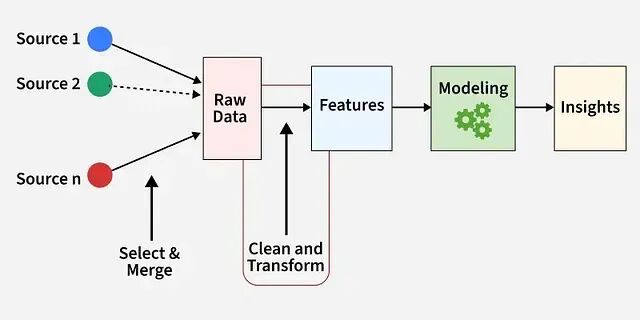
机器学习特征工程:缩放、编码、聚合、嵌入与自动化
好模型的秘诀不在于更花哨的算法,而在于更好的特征。

ADK 多智能体编排:SequentialAgent、ParallelAgent 与 LoopAgent 解析
本文讲介绍每种模式的适用场景、状态的流转机制,以及如何在不编写编排逻辑的前提下搭建一条完整的从订单到交付的流水线。
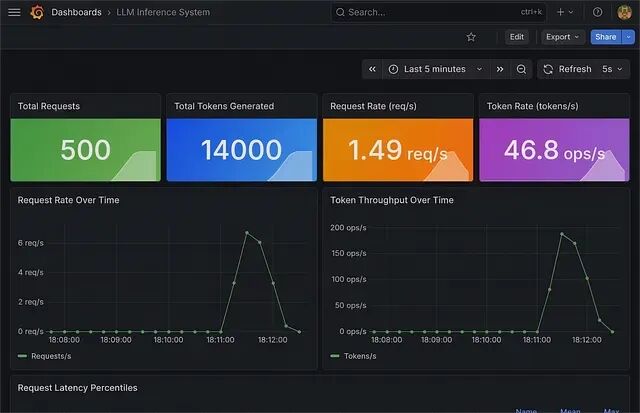
从零构建 Mini-vLLM:KV-Cache、动态批处理与分布式推理全流程
Mini-vLLM是一个从零开始写的推理引擎,我们的目标不是为了造轮子,而是要知道轮子是如何工作的。
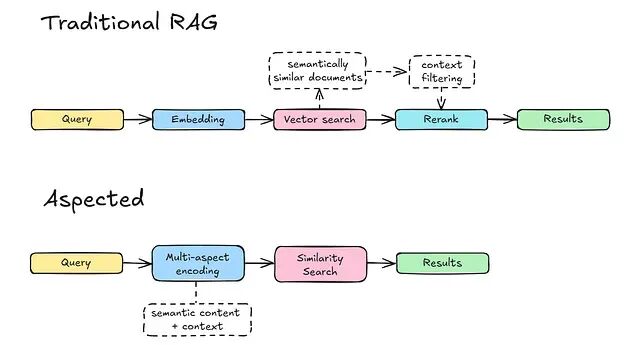
多 Aspect Embedding:将上下文信号编入向量相似性计算的检索架构
本文分析传统向量数据库架构的过滤与检索机制,并介绍 Aspected 的 Aspect Database:一个面向 AI 系统的上下文感知检索引擎
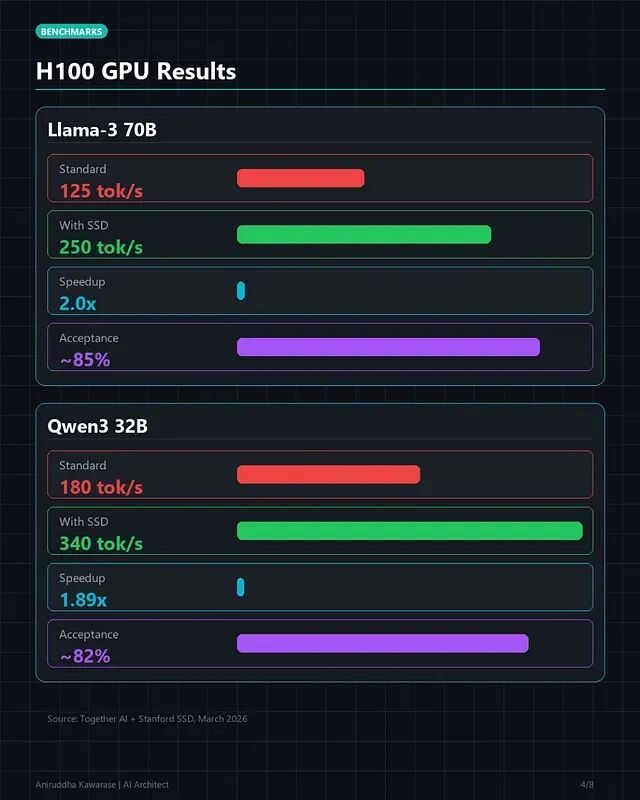
投机解码原理详解:小模型打草稿,大模型一次验证
投机解码的出发点很简单:用一个小而快的模型去猜测大模型接下来要输出什么,而大多数时候它能猜对。

10个内置在 Pandas 中却常被忽略的向量化操作
本文整理了10个这样的写法,每个都附带常见的冗长版本作为对照。

10个内置在 Pandas 中却常被忽略的向量化操作
本文整理了10个这样的写法,每个都附带常见的冗长版本作为对照。
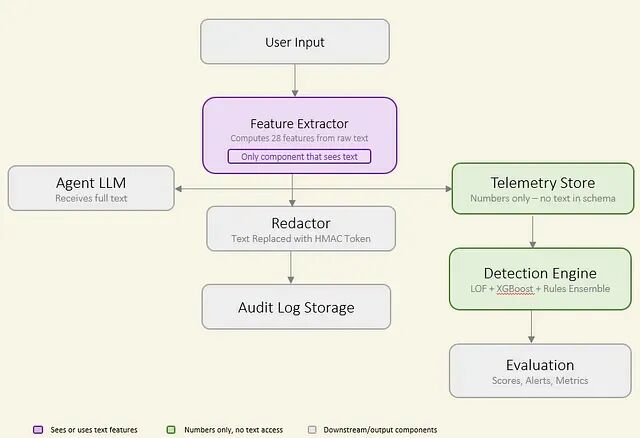
不依赖对话日志检测Prompt注入,一套隐私优先的实现方案
本文就是做一个受约束的实验,用于测试这种架构边界是否可行。
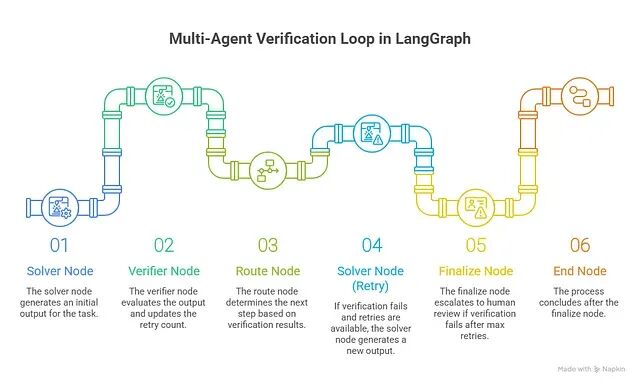
多 Agent 验证架构实战:从输出评分到过程验证
正确构建验证层需要理解四种不同的架构模式、各自的失效边界,以及一个被多数团队忽视的规律。
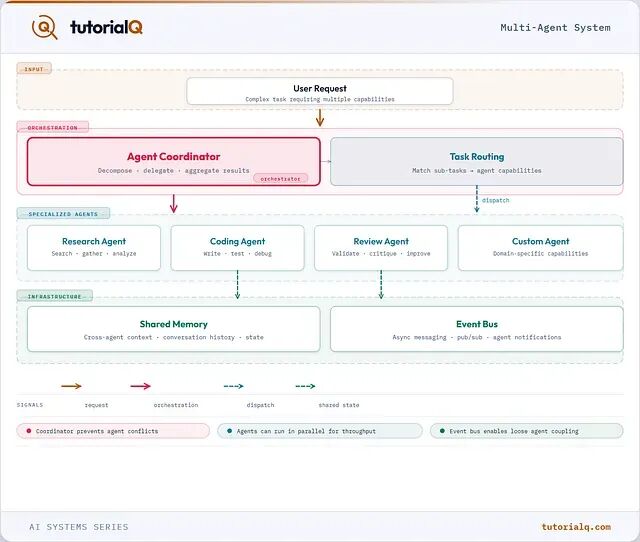
多智能体系统的核心设计:从任务分解到依赖图驱动的编排循环
多智能体系统将复杂任务分配给各自拥有独立角色、工具和评估标准的专门智能体。
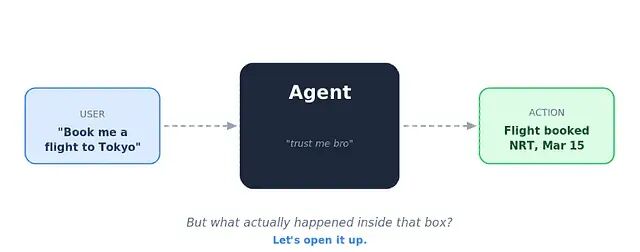
AI Agent 架构详解:Chain-of-Thought、ReAct 与工具调用的协作机制
这篇文章填的就是这个空白。从用户输入"帮我订机票"到 AI 点击"确认",每一步都用架构图拆开来看。
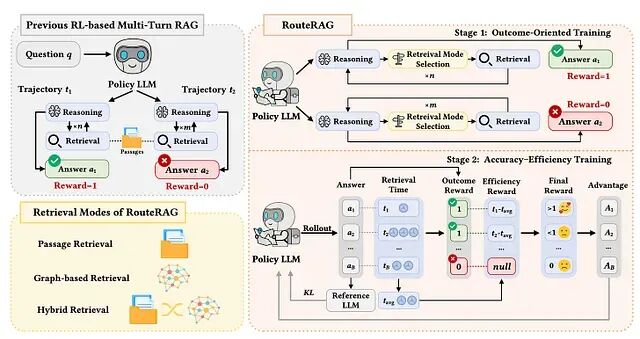
RouteRAG:用特殊 Token 和强化学习构建可学习的 RAG 检索策略
RouteRAG 把多轮 RAG 重新建模为序列决策过程。
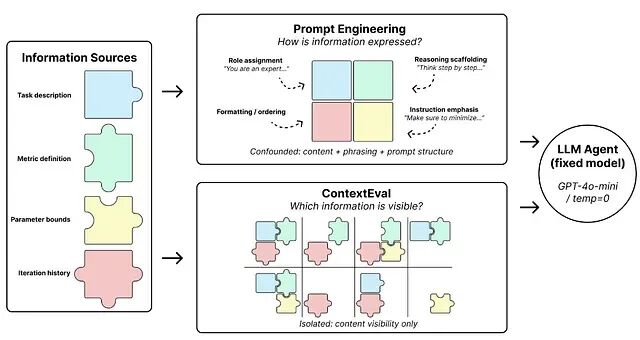
信息访问 vs. 推理能力:LLM Agent 性能归因的实验分析
LLM agent 看起来越来越智能了。但实际上它们可能只是拿到了更多信息。
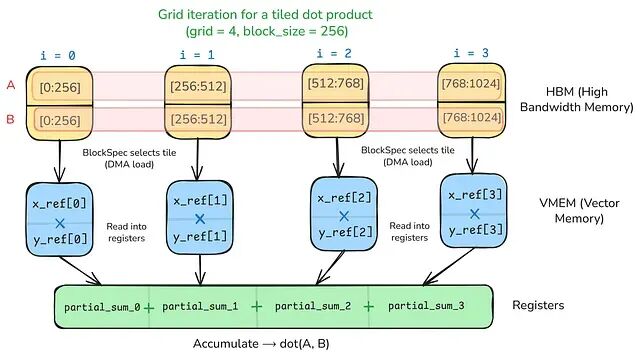
TPU 架构与 Pallas Kernel 编程入门:从内存层次结构到 FlashAttention
本文通过四个复杂度递增的 kernel 展示了 Pallas 的核心编程模式
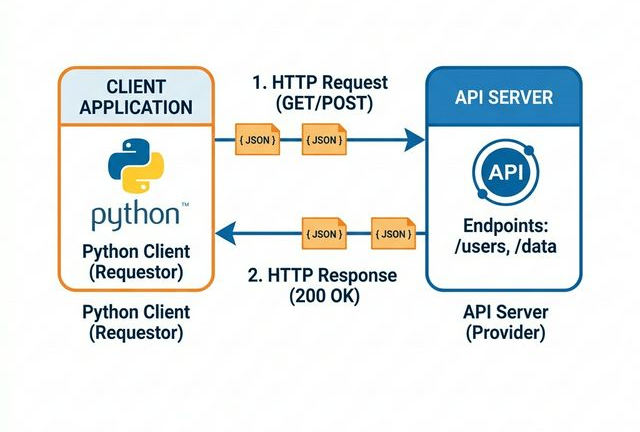
腾讯微信OpenClaw插件API通信过程剖析与Python原生代码复刻原理
本文将介绍如何不装 OpenClaw,直接把协议扒出来,并用 Python 复刻 。
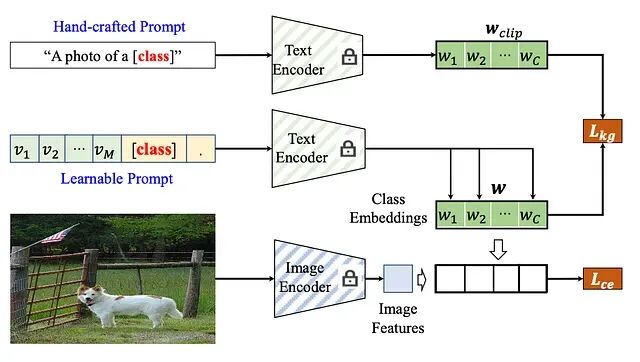
知识引导上下文优化(KgCoOp):一种解决灾难性遗忘的 Prompt Tuning 机制
如何使用知识引导损失对可学习 Prompt 进行正则化以保持泛化能力。
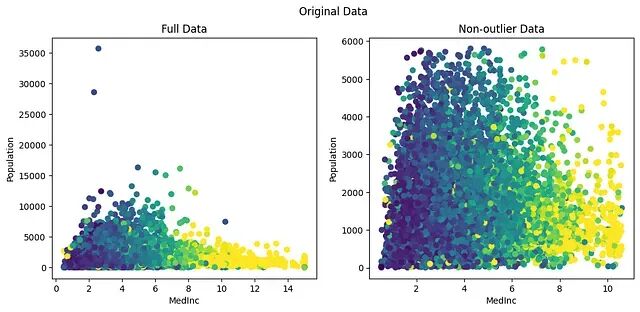
数值特征工程中的四种缩放方法:原理、适用场景与局限性
数值特征工程是机器学习模型训练中不可跳过的预处理环节。处理数值数据时需要面对两个核心问题:特征的量级差异和异常值。

9个提升Python代码生产质量的第三方库
这9个库覆盖了日常开发中几个反复出现的痛点:嵌套数据访问、标准库功能缺失、运行时类型安全、错误处理模式、时区陷阱、性能分析、测试断言、重试机制和数据管道。

Claude Code 命令体系解析:三种类型、七大分类、50+ 命令
这篇文章覆盖每一个斜杠命令、每一个 CLI 标志、每一个键盘快捷键,以及开发团队从未正式宣布就悄悄上线的隐藏功能
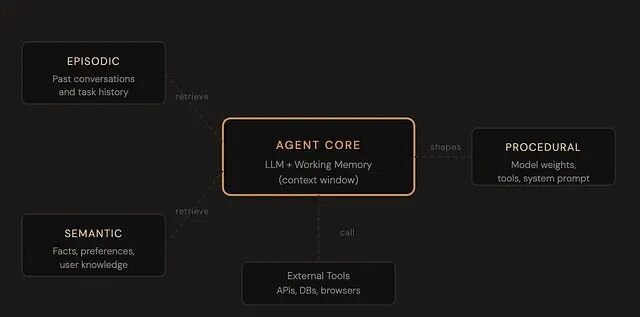
理解 Agent 记忆:从无状态模型到持久化记忆架构
Agent 记忆并非单一概念,它是一个四层体系,各层服务于不同目的。