
异常检测是指数据科学中可帮助发现数据集中的异常值有用的技术。异常检测在处理时间序列数据时特别有用。例如时间序列数据来自传感器测量结果(例如压力和温度),由于设备故障和瞬态现象等问题包含许多异常点, 异常检测有助于消除这些点异常值,以优化时间序列数据中的信号。对于销量预测等需求异常点也可以表示为活动或者营销的记录,可以进行重点分析。
在这篇文章中,将介绍一个可用于检测异常值的简单但高效的算法,该算法来自论文(https://www.researchgate.net/publication/231046287_Measurement_of_free_surface_deformation_in_PIV_images)
时间序列异常检测算法
下图说明了可以在测量传感器的日常操作中观察到的时间序列数据的典型示例。橙色线表示基础信号,而蓝色峰表示可能由于测量读数中的尖峰而出现的异常点。在这种情况下,我们所需的异常检测工具的目的是通过删除那些异常点来简单地细化信号。
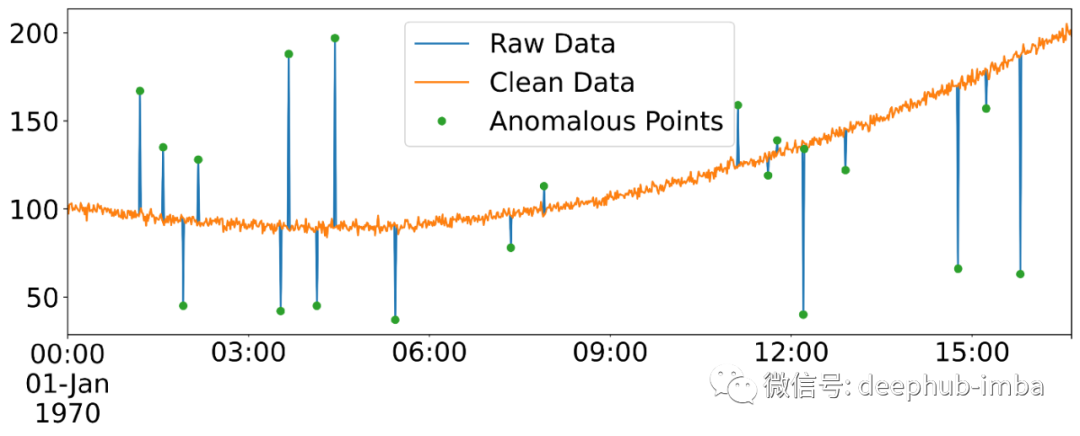
我们将点异常定义为与其预期值完全不同的任何点。在这篇文章中展示的算法是通过使用多项式回归和学生化残差( studentized residual也叫学生化删除的残差)来识别这些异常。
第一步是定义一条多项式曲线,为数据集的基础信号提供估计。

为了将这条曲线拟合到数据中,必须通过最小化某个损失函数来确定系数(直到 N 级)。通常损失函数可以定义为普通残差的最小化,其计算为实际值与其预测值之间的差异。

但是使用这种方式识别异常值存在一些局限性。异常的存在可能会导致回归系数出现偏差,从而无法标记异常值。这个限制可以通过移除评估为残差的数据点并在数据上重新拟合多项式回归来解决,并且这个操作可以重复多次。

上述方法对于每个数据点,必须重新拟合回归模型。但是有一个数学技巧可以通过仅在整个数据集上计算一次回归拟合来确定删除的残差并将它们标准化。最终残差被称为学生化删除残差(即将残差除以其标准差),所以可以按如下方式计算:

数学技巧是使用 Hat 矩阵的对角线来调整每个观测值 i 的 SSE(误差平方和)。这个Hat 矩阵计算为:

然后,学生化删除的残差可用于通过查找异常大的偏差来查找异常点。这些残差遵循具有 n-1-p 自由度的 T 分布,因此可以通过计算定义为的 Bonferroni 临界值来建立合适的阈值:
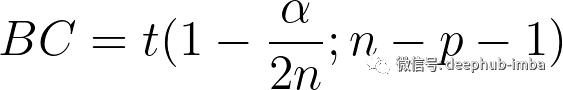
α 是显著性值(通常设置为 0.05),可以识别我们期望在预期置信区间内的值。
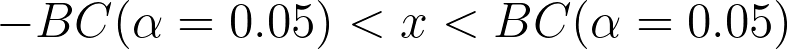
然后可以使用此阈值来识别和删除数据集中的任何点异常。此外还可以对 BC 值应用一个校正因子以获得更好的结果(在论文中发现 1/6 的值可以提供最佳性能)。
Python 实现
为了生成简单的实验数据集,我们使用添加了高斯噪声的基线多项式曲线。然后,我们将 20 个随机点添加到我们认为是异常的数据中。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
rng = np.random.default_rng(12345)
# Define index
nx = 1000
index = pd.date_range(start="1970", periods=nx, freq="1T")
# Define signal and noise
x = np.linspace(0, 10, nx)
signal = 2*x**2- 10* x + 2
noise = np.random.normal(loc=100, size=nx, scale=2)
y = noise + signal
# Add anomalies
anom_num = rng.integers(low=0, high=200, size=20)
anom_ids = rng.integers(low=0, high=nx, size=20)
y[anom_ids] = anom_num
is_anom = [item in anom_ids for item in range(nx)]
# Pandas DataFrame and plot
raw_data = pd.Series(y, index = index)
clean_data = raw_data[np.invert(is_anom)]
raw_data.plot(figsize=(15,5))
clean_data.plot()
raw_data[anom_ids].plot(style='o')
plt.legend(['Raw Data', 'Clean Data','Anomalous Points'])
在将日期时间索引转换为整数后,可以使用 numpy 对该数据集执行多项式回归(在这种情况下,它转换为从 1970-01-01 开始的以毫秒为单位的时间)。
# Transform variables to lists
x = (np.array(raw_data.index, dtype=np.int64) - raw_data.index[0].value) / 1e9
y = raw_data.to_numpy()
# Create a polynomial fit and apply the fit to data
poly_order = 2
coefs = np.polyfit(x, y, poly_order)
y_pred = np.polyval(coefs, x)
Hat矩阵的计算可以如下进行:
# Calculate hat matrix
X_mat = np.vstack((np.ones_like(x), x)).T
X_hat = X_mat @ np.linalg.inv(X_mat.T @ X_mat) @ X_mat.T
hat_diagonal = X_hat.diagonal()
根据 T 分布计算学生化删除残差及其对应的 p 值可以如下执行:
from scipy.stats import t as student_dist
# Calculate degrees of freedom
n = len(y)
dof = n - 3 # Using p = 2 from paper
# Calculate standardised residuals
res = y - y_pred
sse = np.sum(res ** 2)
t_res = res * np.sqrt(dof / (sse * (1 - hat_diagonal) - res**2))
最后,用 Bonferroni 临界值过滤掉异常,阈值和绘制结果如下。
# Return filtered dataframe with the anomalies removed using BC value
alpha=0.05
bc_relaxation = 1/6
bc = student_dist.ppf(1 - alpha / (2 * n), df=dof) * bc_relaxation
mask = np.logical_and(t_res < bc, t_res > - bc)
# Plot anomalous and filtered data
ax=raw_data.plot(figsize=(15,5))
raw_data[mask].plot(ax=ax)
raw_data[anom_ids].plot(style='o')
raw_data[np.invert(mask)].plot(style='ok')
plt.legend(['Raw Data','Filtered with Anomaly Detector', 'Missed Anomalies', 'Anomalous Points Found'],bbox_to_anchor=(0.5, 1.05))
结果
将生成数据使用典型的准确率和召回率分类指标来确定我们的模型的工作情况。在我们的合成数据集上使用上述方法,得到了 95% 的召回率和 86% 的准确率。这意味着我们只错过了 20 个异常中的一个,并且只有 3 个误报。

到目前为止一切都很好,但是这个算法将如何处理实际的真实数据呢?为了测试这一点,我们使用开放工业数据,这是一个可供公众使用的公开数据集(https://openindustrialdata.com/)。那数据量比较大,但让我们选择一个对工业过程非常重要的传感器数据。在此示例中,将使用一个压力变送器来测量第一级压缩机的冲击压力(标签的外部 ID 为 pi:160696)并检查过去 50 天的每小时值。
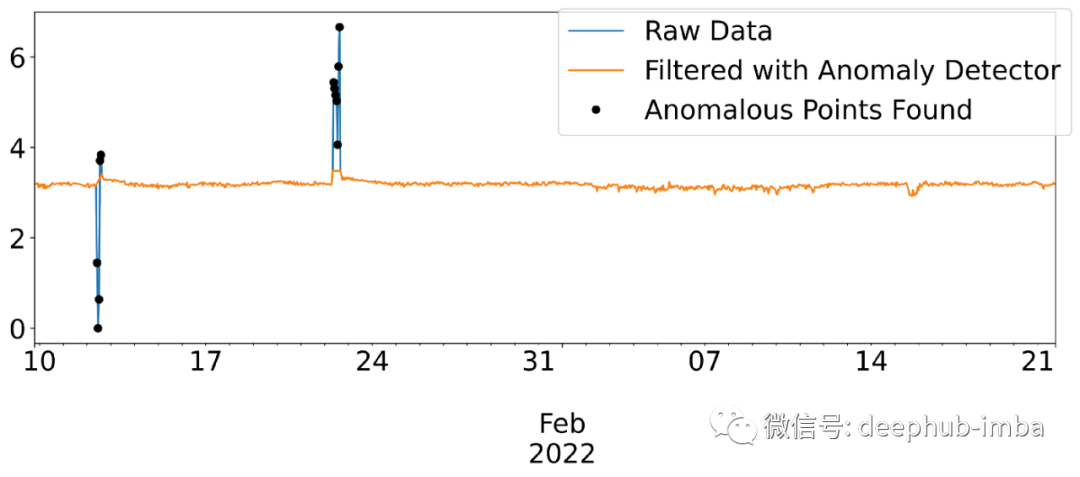
人肉的检查表明异常确实已成功消除,并且信号已被细化以供进一步分析。
总结
最后大家可能对这个术语听起来感到非常的奇怪,这里做一个简单的解释
残差(residual)=观察值 - 预期值
一个好的线性回归残差应该是符合正态分布的,但是可以通过变换使得残差符合自由度为n-1-p 的t分布。t分布因为叫做student‘s t distribution, 所以这个变换后的残差值就是studentized residual。通过检查这个值可以知道观察值的分布情况,可以用来寻找outlier及确定其p value。
还记得t分布的背景吧:当时的业余统计学研究者 W. Gosset 以笔名 Student 发表关于 T 分布的统计学史地标性文献,所以T分布又被称作学生 t -分布(Student's t-distribution)
学生化这个词其实就是studentized的中文直译,因为约定俗成了所以也没什办法,studentized就是把其他分布转换成t分布,所以其实 studentized residual 翻译为 T 化残差 ,要比 学生化残差 更自然,也更好理解。
作者:Andris Piebalgs