
NVidia 的新 H100 GPU已经发布了,我们也很久没有发论文推荐了,这是4月份的论文推荐:Google 的 5400 亿参数 PaLM、Pathways、Kubric、Tensor Programs、Bootstrapping Reasoning With Reasoning、Sparse all-MLP 架构、使用深度学习制作人脸动画等等。

1、Tensor Programs V: Tuning Large Neural Networks via Zero-Shot Hyperparameter Transfer
By Greg Yang, Edward J. Hu et al.
超参数调优是创建 SOTA 模型的重要因素。对于大型模型,这通常需要大量的计算资源,这使得资源有限的小型参与者根本无法进入这一领域。论文的这项工作展示了如何更有效地完成超参数调整。
为了训练神经网络,必须选择合适的超参数。在前几年,超参数只有少数几个(例如固定学习率、卷积核大小等),但现在超参数空间变得更加复杂:学习率激活函数、学习率计划、优化器选择、注意力头的数量、隐藏维度 等等。
论文中提到的方法可以在小型模型中找到最佳超参数,然后扩展模型到大型模型进行最终的资源密集型训练运行。这种称为 μTransfer 的方法不仅基于理论分析,并且可证明在某些条件下有效,作者也凭经验表明,通过在现代 Transformer 上使用该技术,这种方法可以更宽松地应用。

作者也提到,这种方法仍然存在许多局限性,但它为促进大型模型的训练,甚至对现有模型的进一步优化,甚至在数万亿参数规模上实现下一代更大型模型的超参数调整提供了一个有趣的方向.
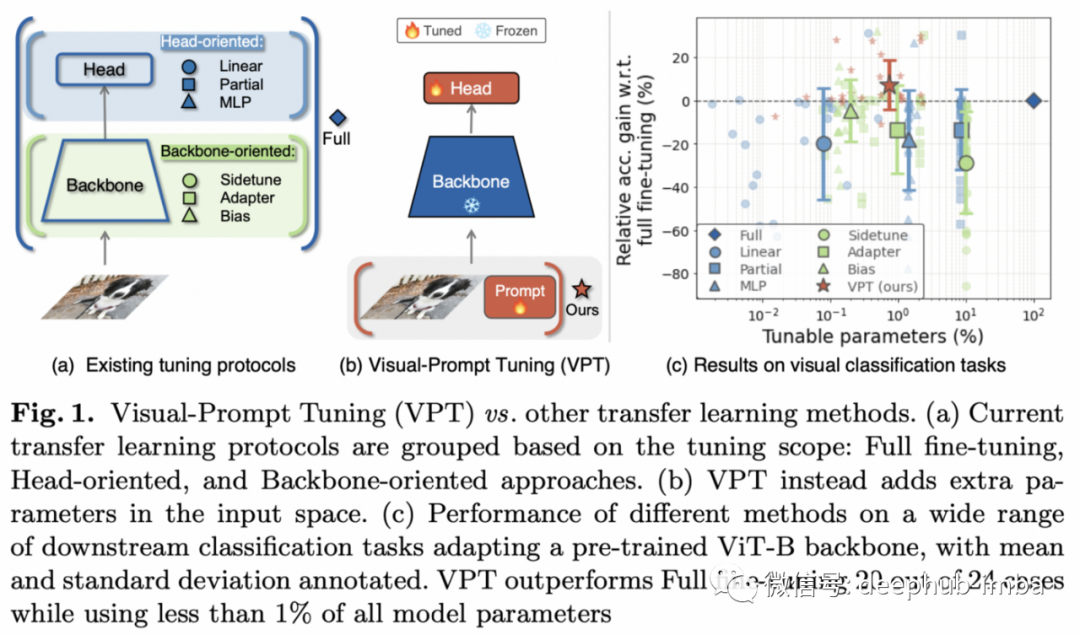
2、Visual Prompt Tuning
By Menglin Jia, Luming Tang, et al.
对于现在的大型模型而言人们不会从头开始构建模型,而是使用预先训练的模型进行微调。下游任务中最大限度地利用大型预训练模型同时计算成本低的技术将是关键。Prompt 就是这样一种技术。
作者探讨了各种“部分调整”技术如何在调整参数/性能比的百分比方面进行比较。大型预训练模型通过使用标记数据和在整个架构中传播梯度来进行微调。但是在过去的一年中,prompt已成为一种可行的替代方案:保持预先训练的模型权重不变,并在输入中预先添加一组嵌入,这些嵌入可以通过梯度下降和一些标记数据来学习。
这种技术已被证明在 NLP 任务上是有效的,现在正被用于图像分类,它不仅在效率方面而且在绝对准确度方面都表现出非常有竞争力的性能。更重要的是,Prompt 在 few-shot 的情况下最为突出,在这种情况下,完全微调通常很困难。Prompt 的另一个好处是,它可以预训练模型概念化为输入/输出黑盒,训练一个只能通过 API 访问的模型(使用无梯度优化⁷,或在梯度可用时进行梯度下降) ,这是行业正在发展的方向。
3、Pathways: Asynchronous Distributed Dataflow for ML and PaLM: Scaling Language Modeling with Pathways
By Paul Barham et al.
如果你认为大规模扩展的工具将是未来AI不可缺少的一部分,那么这是你所需要的谷歌对未来的计划。它包含了最新的5400亿参数的巨大Transformer。
本文是 Google 的Pathways 的未来路径蓝图,“用于硬件加速器的大规模编排层,可在数千个加速器上进行异构并行计算,同时通过其专用互连协调数据传输。”
现有的加速器框架擅长在数据的不同部分并行运行相同的计算,这些部分稍后会同步(又名单程序多数据,SPMD)。Pathways 旨在能够并行计算更多异构计算(又名多程序多数据,MPMD)。
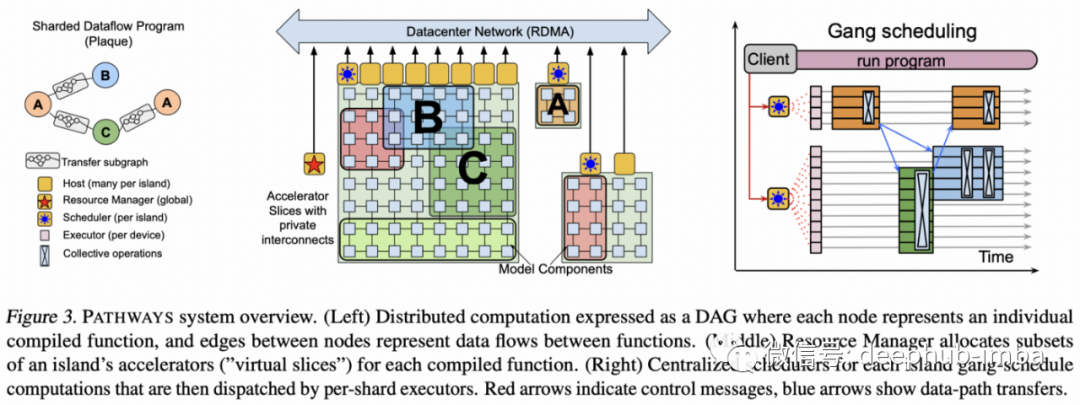
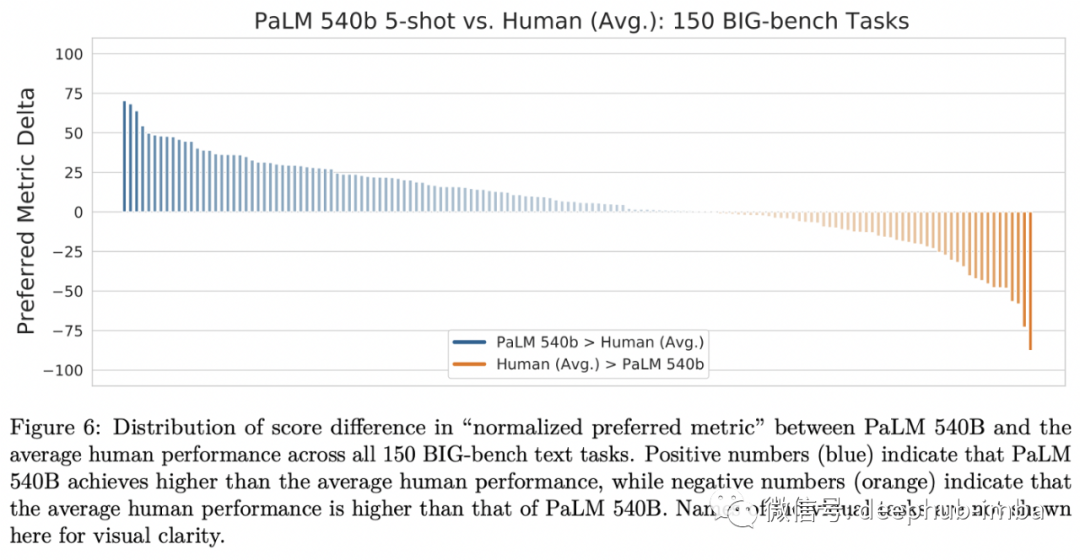
这使得训练和托管模型成为可能,比如刚刚发布的5400亿个参数(密集)的PaLM: Scaling Language Modeling with Pathways⁶,它是在跨越多个pod的6144个TPU v4芯片上进行训练的。这种密集模型是最新的旗舰产品,它在许多零和少样本的NLP任务中实现了最先进的技术,在过程中超过了许多人类的基线。
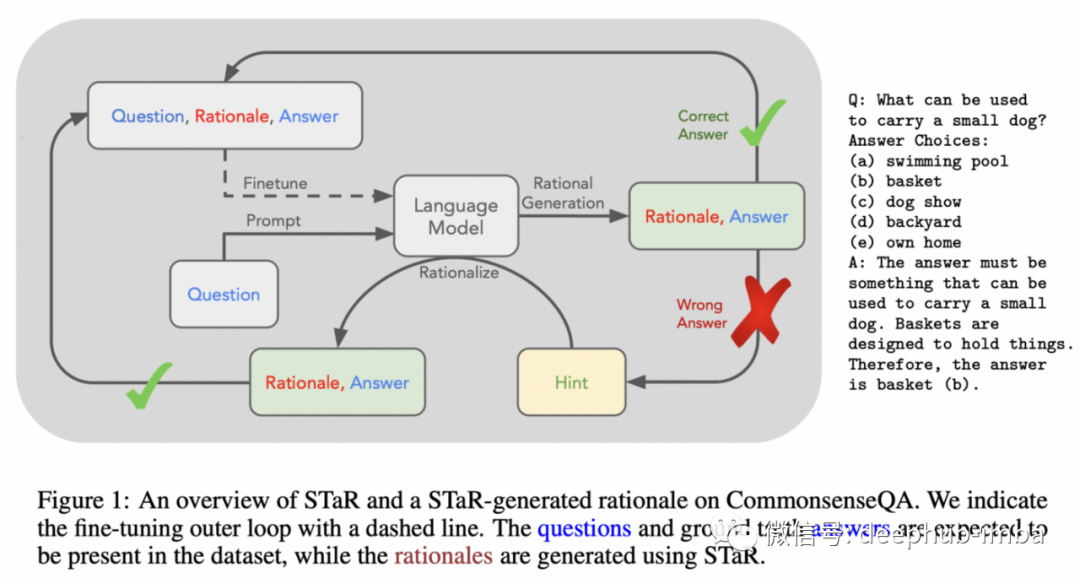
4、STaR: Selt-Taught Reasoner. Bootstrapping Reasoning With Reasoning
By Eric Zelikman, Yuhuai Wu, and Noah D. Goodman.
逻辑推理经常被认为是大型语言模型 (LM) 的一个弱点:虽然它们有时可能会做对,但经常在基本常识推理方面失败。本文提出了一个有希望的方向,也许可以释放语言建模的潜力,并将其用于更高级的类人推理。
基本原理是对信念或采取行动的原因进行明确逻辑解释。虽然之前的工作已经证明:明确的理论可以如何在一些场景中提高lm的性能⁵ ,但这项工作展示了如何在不依赖大规模人工标记注释的情况下引导推理能力。
作者只使用了一个问题解决语料库(没有人类的基本原理),让LM为其答案生成基本原理,只要答案是正确的,这些基本原理就被认为是有效的。根据作者的说法,这是一个协同过程,理论基础生成改进了训练数据,而训练数据的改进也改变了模型的理论基础生成。为了防止此过程饱和,当模型无法解决训练数据中的任何新问题时,模型会提供答案,然后模型会向后生成一个基本原理并将其添加为训练数据。
实验结果并不能被广泛的推广,但它们的确出现了非常好的表现:学习速度更快,推理性能与 30 倍大的 GPT-3 模型相当。STaR系统明显优于它的普通的、没有理解能力的、只针对问题解决方案对进行训练的同类系统。

5、Do As I Can, Not As I Say (SayCan): Grounding Language in Robotic Affordances | Project page
By Michael Ahn et al.
缺乏现实世界的基础是对现有语言模型的普遍批评:如果不与视觉等其他模态的观察和交互相结合,任何模型如何对语言有任何有意义的理解?
人类用户向机器人提供的指令可能很长、很抽象,甚至是模棱两可的。LM 的作用是将指令歧义化为更短的原子步骤。这与之前使用预训练语言模型将高级指令映射到低级动作的工作非常相似¹⁰,但是不是仅仅依赖于模拟,而是通过包括了现实世界的机器人实际的计划,这项工作又向前迈进了一步。

最近使用预训练语言模型来指导图像学习表示的另一项有趣的工作是 Integrating Language Guidance into Vision-based Deep Metric Learning(arxiv 2203.08543)
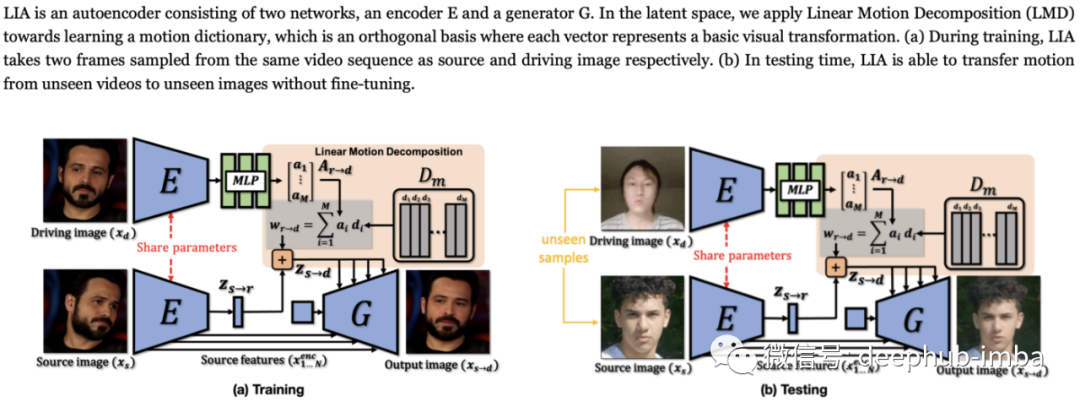
6、Latent Image Animator: Learning to Animate Images via Latent Space Navigation
By Yaohui Wang, Di Yang, Francois Bremond, and Antitza Dantcheva.
通过深度学习的生成逼真动画是非常酷炫的,如果它继续发展可能将成为游戏和VR等应用的一项基本技术。
现有的基于深度学习的图像动画框架通常依赖于图像的结构化表示:人的关键点、光流、3D网格等等。本论文提出了一种潜在图像动画器(LIA),它只依赖于一个自监督图像自动编码器,而没有任何显式结构化表示。定义了一种线性运动分解(Linear Motion Decomposition),旨在将视频中的运动描述为一种潜在的路径,这种路径是通过一系列学习到的运动方向和幅度的线性组合来实现的。
该方法由编码器和生成器两个模型组成。对于训练,视频的2帧被用作数据的自我监督源,让模型将一个对象的不同视图编码成它的身份和可分解的运动部分,生成器将其用于输出一个图像,并从中计算重构损失。为了进行推理,将源图像和姿势图像替换为不同的人,模型生成的输出图像具有源的身份,但具有姿势图像的姿态。
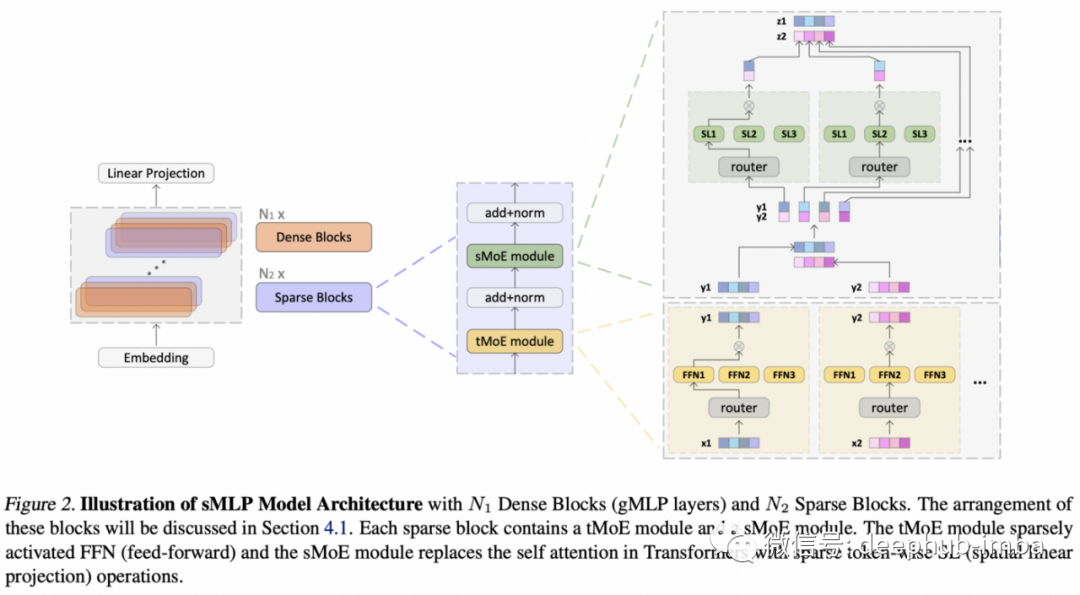
7、Efficient Language Modeling with Sparse all-MLP
By Ping Yu et al.
架构在 ML 中的作用是否会进一步缩小?论文的回答是:是的。
Pay attention to MLPs¹ 已经向我们展示了“无注意力架构”在语言建模中具有竞争力,令牌之间的信息通过MLPs的更基本组合进行传播。这项工作将这一想法扩展为在稀疏的专家混合模型中工作,并且具有更强的缩放能力。
论文分析了 MLP 在表达能力方面的局限性并提出了在特征和输入(令牌)维度上具有混合专家 (MoE) 的稀疏激活 MLP。与以前用于视觉all MLP architectures²类似,跨令牌和令牌内部的信息是通过按令牌应用全连接 (FC) 层,然后转置/混合,然后按特征应用 FC实现的(见下图)。
8、Kubric: A scalable dataset generator
By Klaus Greff et al.
当自然标记数据非常困难或花费非常高时,合成数据是一个快速廉价的解决方案。这篇论文时建立一个能够端到端创建计算机视觉数据库的最新成果。
数据生成软件不如其建模软件成熟,这就是为什么作者认为在数据生成工具方面需要更多努力。Kubric 是一个开源 Python 框架,它与 PyBullet(物理模拟引擎)和 Blender(渲染引擎)接口,以生成具有细粒度控制和密集注释的逼真场景。
典型的数据生成管道(见下图)结合了从资源来源获取资源、用这些资源组成场景以及摄像机定位、在环境中运行物理模拟,并将其渲染为具有所需注释和元数据的不同层。
该库还可以通过分布式计算进行扩展,在 HPC 环境中生成大量数据。作者通过创建 13 个数据集来展示该库,其中包含新的视觉挑战问题,从 3D NeRF 模型到具有基准结果的光流估计。

9、Training Compute-Optimal Large Language Models
By Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, et al.
尽管BERT³ 优化不足,但取得了巨大的成功⁴,对于新的大型语言模型来说离它们真正的潜力还有很大差距,是否有优化规则可以概括总结并且适用于广泛的大规模模型呢?
本论文的的方向是模型大小和预训练中看到的令牌数量:如果给定固定的计算预算,应该在少量令牌上预训练一个更大的语言模型,还是预训练一个包含更多令牌的更小模型?
他们发现:在缩放模型的同时也在缩放数据。现有的理论错误地倾向于在大模型中训练少量的令牌。例如,作者展示了一个比GPT-3小10倍的模型如何在足够大的语料库上训练时实现性能均等。
由此产生的模型系列被命名为 Chinchilla。

10、Make-A-Scene: Scene-Based Text-to-Image Generation with Human Priors
By Oran Gafni et al.
在受控图像生成领域的又一步。
我们已经习惯了文本引导的图像生成,尤其是自从 OpenAI 的 DALLE⁸ 在 2021 年初声名鹊起之后。这项工作属于基于离散标记的基于似然的图像生成的同一家族:学习图像块的离散表示(使用 VQ-VAE⁹ 或类似方法),然后使用文本图像对的下一个标记的自回归预测进行训练和推理,例如语言建模。该系统有 3 个关键的新组件使其与众不同:
- 能够添加场景(图像分割)。
- 使用改进的 VQ-GAN⁹ 模型来学习包含感知损失的高保真离散表示。
- 添加无分类器消除了对生成后过滤的需要。
引用
[1] “Pay Attention to MLPs” by Hanxiao Liu et al. 2021.
[3] “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding” by Jacob Devlin et al. 2018.
[4] “RoBERTa: A Robustly Optimized BERT Pretraining Approach” by Yinhan Liu et al. 2019
[5] “Chain of Thought Prompting Elicits Reasoning in Large Language Models” by Jason Wei et al. 2022
[6] “PaLM: Scaling Language Modeling with Pathways” by Aakanksha Chowdhery et al. 2022.
[7] “Black-Box Tuning for Language-Model-as-a-Service” by Tianxiang Sun et al. 2022
[8] “Zero-Shot Text-to-Image Generation” by Aditya Ramesh et al.
[9] “Taming Transformers for High-Resolution Image Synthesis” by Patrick Esser, Robin Rombach, and Björn Ommer; 2020.
[10] “Language Models as Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents” by Wenlong Huang, Pieter Abbeel, Deepak Pathak, and Igor Mordatch; 2022.
作者:Sergi Castella i Sapé