现在已经是3月中旬了,我们这次推荐一些2月和3月发布的论文。
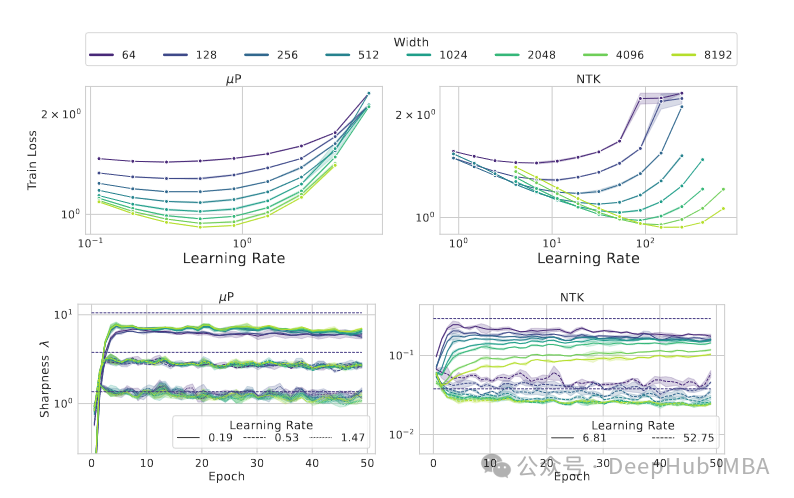
Why do Learning Rates Transfer? Reconciling Optimization and Scaling Limits for Deep Learning.
https://arxiv.org/abs/2402.17457
学习速率为什么会迁移?本研究试图从理论上解释MuP超参数传递的成功之处。根据其创作者的说法,训练损失的Hessian矩阵的最大特征值不受网络深度或广度的影响。
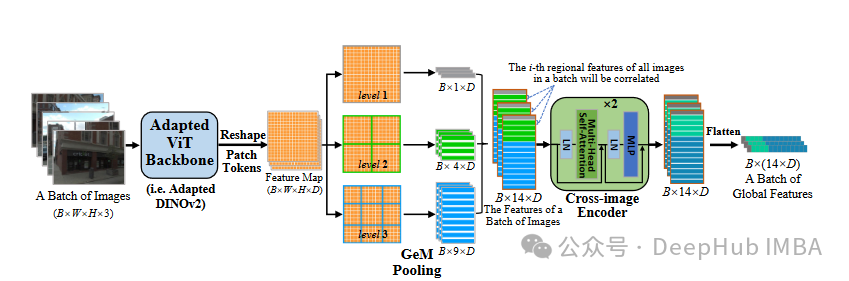
CricaVPR: Cross-image Correlation-aware Representation Learning for Visual Place Recognition.
https://arxiv.org/abs/2402.19231v1
CricaVPR提出了一种视觉位置识别的交叉图像相关感知表征学习的方法,专注于许多照片之间的关系,即使它们是在各种情况下拍摄的,以提高视觉位置识别。
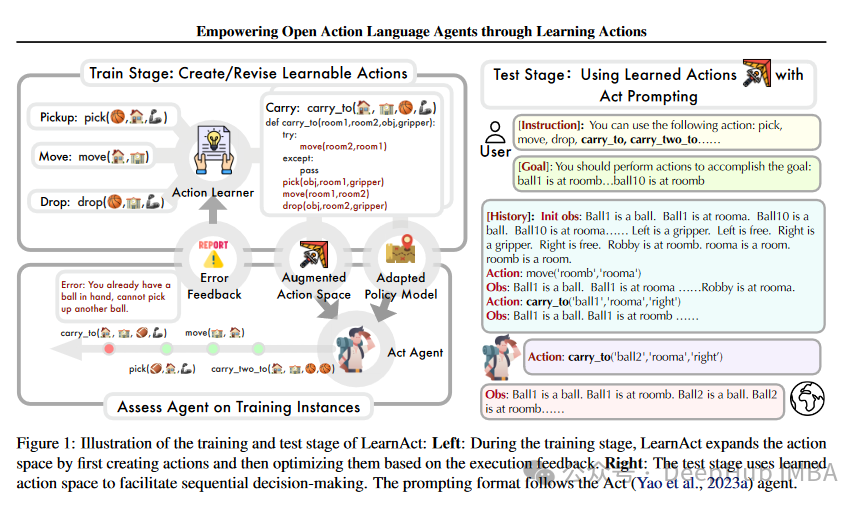
Empowering Large Language Model Agents through Action Learning.
https://arxiv.org/abs/2402.15809
通过动作学习增强大型语言模型代理的能力。使用迭代学习策略研究语言代理的开放动作学习,该策略使用Python函数来创建和改进动作;在每次迭代中,提出的框架(LearnAct)根据执行反馈对可用动作进行修改和更新,扩大动作空间,提高动作有效性;LearnAct框架在机器人规划和AlfWorld环境中进行了测试,与ReAct+ reflection相比,AlfWorld中的代理性能提高了32%。
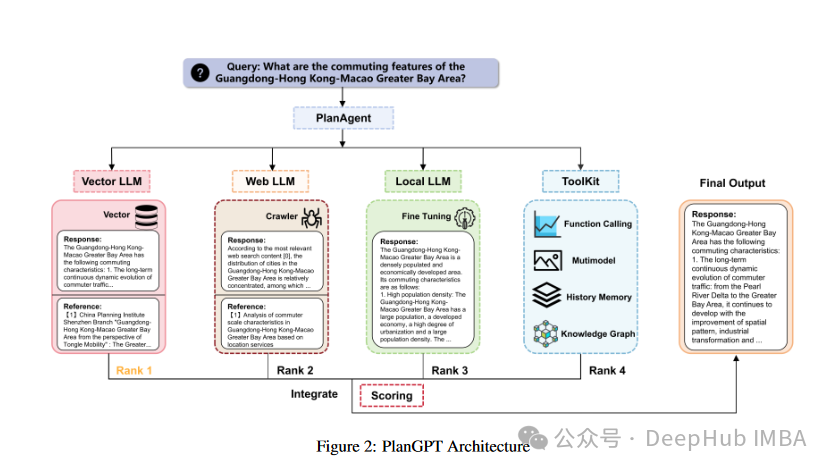
PlanGPT: Enhancing Urban Planning with Tailored Language Model and Efficient Retrieval.
https://arxiv.org/abs/2402.19273
基于定制语言模型和高效检索的城市规划。演示了如何使用llm集成几种方法,如检索增强、微调、工具利用等;虽然建议的框架是在城市和空间规划的背景下使用的,但许多见解和有用的建议也适用于其他领域。
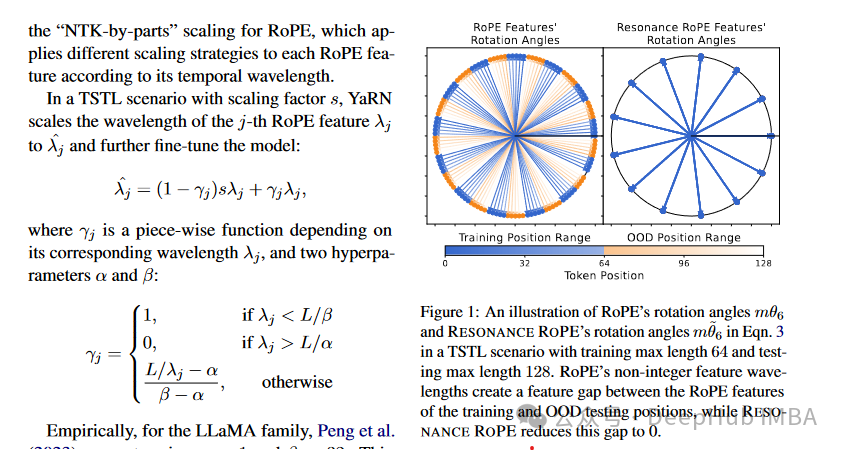
Resonance RoPE: Improving Context Length Generalization of Large Language Models.
https://arxiv.org/abs/2403.00071
改进大型语言模型的上下文长度泛化。为了帮助LLM理解和生成比最初训练时更长的文本序列,研究人员创造了一种名为RoPE的新方法。通过使用更少的处理能力,方法优于当前的旋转位置嵌入(RoPE)技术,并提高了冗长文本的模型性能。
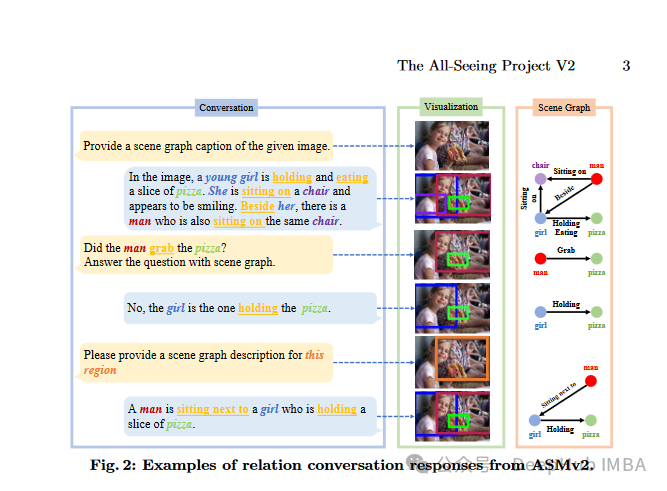
The All-Seeing Project V2: Towards General Relation Comprehension of the Open World.
https://arxiv.org/abs/2402.19474v1
对开放世界的一般关系理解。All-Seeing Project V2引入了ASMv2模型,它混合了文本生成、对象定位和理解图像中对象之间的联系。
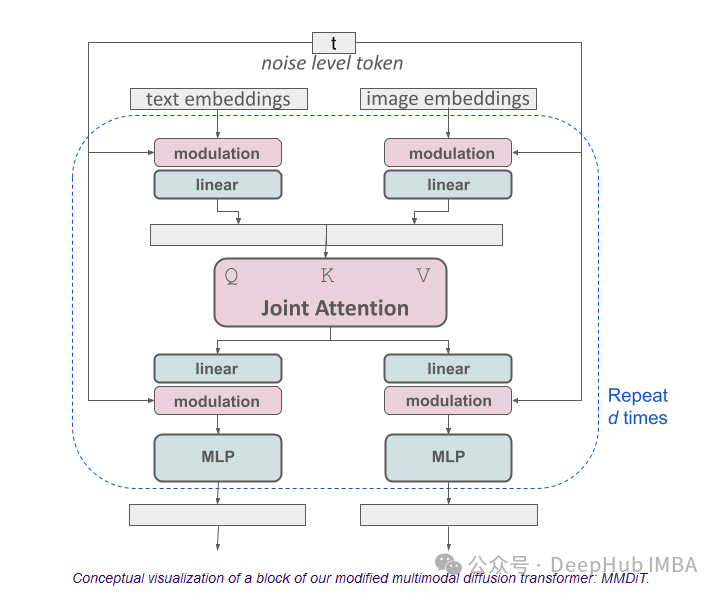
Stable Diffusion 3
https://stability.ai/news/stable-diffusion-3-research-paper
最新的SD3优于DALL·e3、Midjourney v6,新的多模态扩散Transformer(Multimodal Diffusion Transformer, MMDiT)架构为图像和语言表示使用独立的权重集,与以前版本的SD3相比,这提高了文本理解和拼写能力。
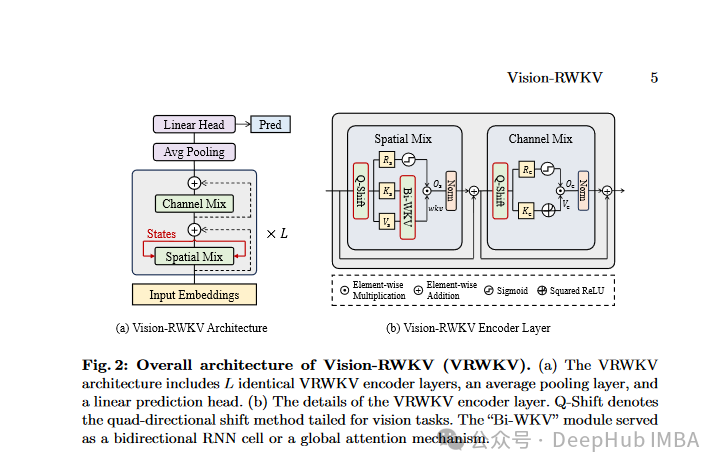
Vision-RWKV: Efficient and Scalable Visual Perception with RWKV-Like Architectures.
https://arxiv.org/abs/2403.02308v1
基于RWKV-Like架构的高效可扩展视觉感知。vision -RWKV通过修改NLP的RWKV架构来进行计算及视觉的任务,为高分辨率图像处理提供了有效的解决方案。
Design2Code
https://arxiv.org/abs/2403.03163
我们离自动化前端工程还有多远?使用设计图并将其转化为代码是很困难的。论文将18B模型作为基线,评估表明gpt - 4v生成的代码有时比人工合成的代码更受欢迎。