
基于文本提示的生成图像模型近年来取得了惊人的进展,这得益于新型的深度学习架构、先进的训练范式(如掩码建模)、大量图像-文本配对训练数据的日益可用,以及新的扩散和基于掩码的模型的发展。
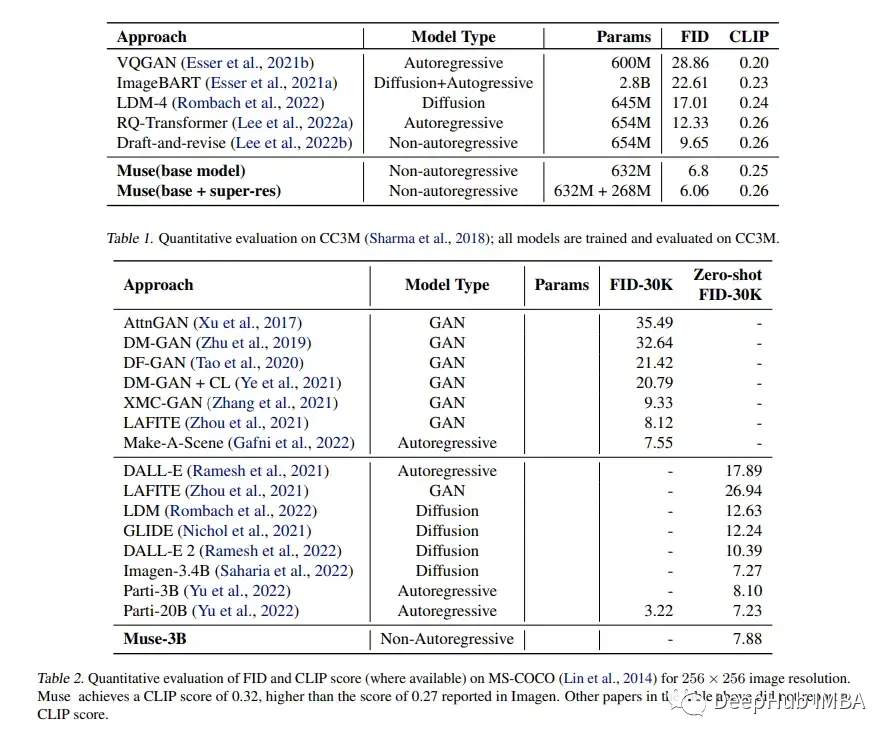
在23年1月新发布的论文 Muse中:Masked Generative Transformers 生成文本到图像利用掩码图像建模方法来达到了最先进的性能,零样本 COCO 评估的 FID 分数为 7.88,CLIP 分数为 0.32——同时明显快于扩散或传统自回归模型。

google团队总结了它们的主要贡献如下:
- 提出了一个最先进的文本到图像生成模型,该模型获得了出色的 FID 和 CLIP 分数(图像生成质量、多样性和与文本提示对齐的定量测量)。
- 由于使用了量化图像标记和并行解码,模型明显快于同类模型。
- 架构支持开箱即用的零样本编辑功能,包括inpainting, outpainting和free mask编辑。
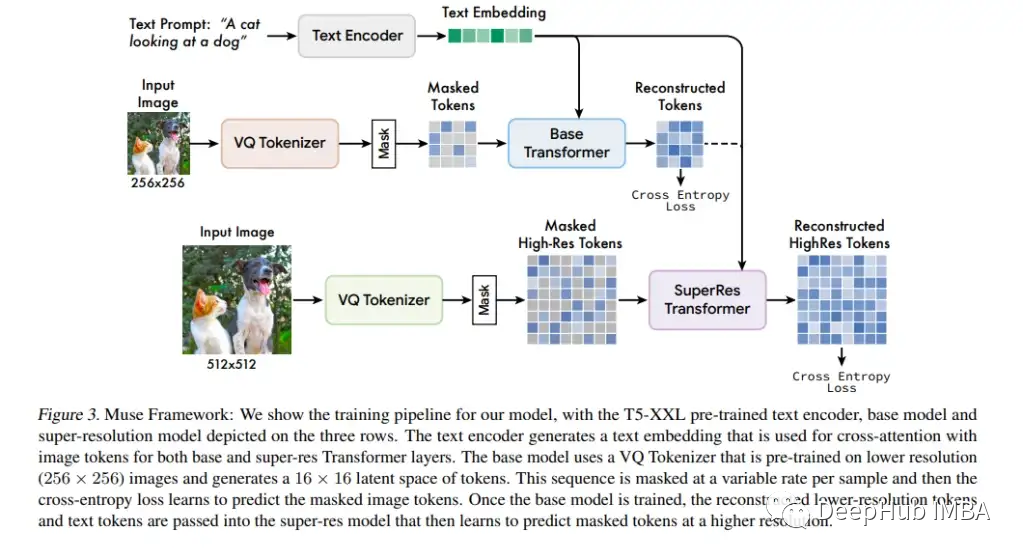
Muse构建在谷歌的T5之上,T5是一个大型语言模型,它接受各种文本到文本任务的训练,可通过掩码transformer 架构生成高质量图像。Muse 从 T5 嵌入中继承了有关对象、动作、视觉属性、空间关系等的丰富信息;并学习将这些丰富的概念与生成的图像相匹配。
Muse一共包含八个核心组件,例如它的语义标记化,它使用VQGAN模型的编码器和解码器对来自不同分辨率的图像进行编码,并输出离散的标记,这些标记捕获图像的更高级别语义,而不受低级别噪声的影响。
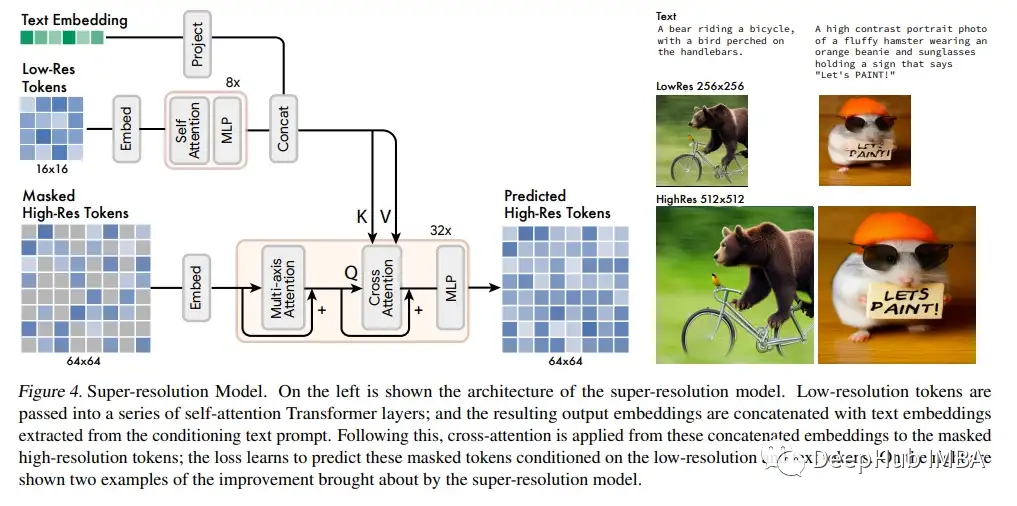
超分辨率模型将较低分辨率的潜在映射转换为更高分辨率的潜在映射,并通过更高分辨率的 VQGAN 解码生成最终的高分辨率图像。研究人员还在保持编码器的容量固定的前提下向 VQGAN 解码器添加额外的残差层和通道,然后微调这些新层,同时保持 VQGAN 编码器的权重等固定。由于视觉标记“语言”保持不变,因此可以在不重新训练任何其他模型组件的情况下可以改善生成图像的细节和视觉质量。
为了改进 Muse 的文本图像对齐,还使用了一种无分类器指导 (classifier-free guidance) 的方法,该方法线性增加引导尺度,在低引导或无引导的情况下对早期标记进行采样,对后面的标记逐渐增加条件提示的影响。还采用并行解码来减少推理时间。

在他们的实证研究中,Muse与各种文本到图像生成任务的流行基准模型进行了比较。Muse 900M参数模型在CC3M数据集上实现了新的SOTA, FID评分为6.06(越低越好),而Muse 3B参数模型在零样本COCO获得了7.88的FID评分,CLIP 分数为 0.32。
Muse展示了令人印象深刻的无需微调的零样本编辑功能,进一步证实了冻结的大型预训练语言模型作为文本到图像生成的强大而高效的文本编码器的潜力。
这是一篇非常值得推荐的论文,并且google还为他制作了专门的网站:
https://arxiv.org/abs/2301.00704
作者:Synced