
CCNet, Transformer递归交叉自注意力,比非局部神经网络更有效。华中科技大学、地平线、ReLER 和伊利诺伊大学香槟分校联合研发
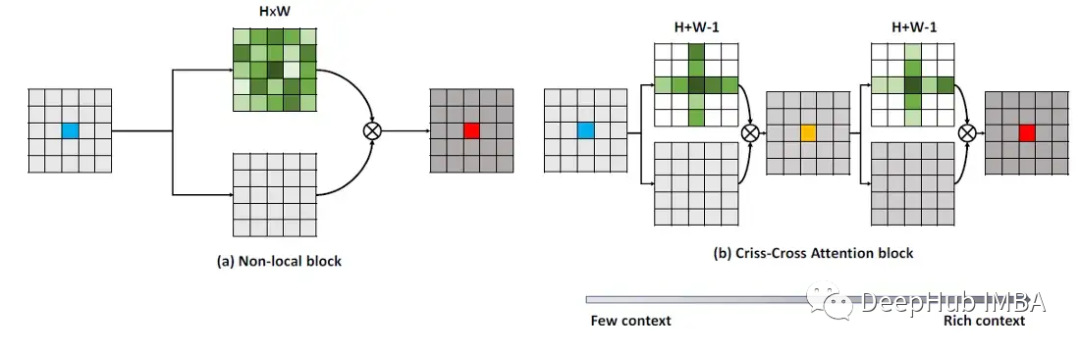
论文提出了交叉网络 (CCNet),对于每个像素,CCNet 中的一个新的交叉注意力模块收集其交叉路径上所有像素的上下文信息。通过进一步的递归操作,每个像素最终都可以从所有像素中捕获完整图像的依赖关系。与 Non-Local Neural Network 相比,CCNet 使用的 GPU 内存减少了 11 倍,FLOP 减少了约 85%。TPAMI的CCNet,进一步增强了更好的损失函数,扩展到3D情况。
CCNet (2019 ICCV)
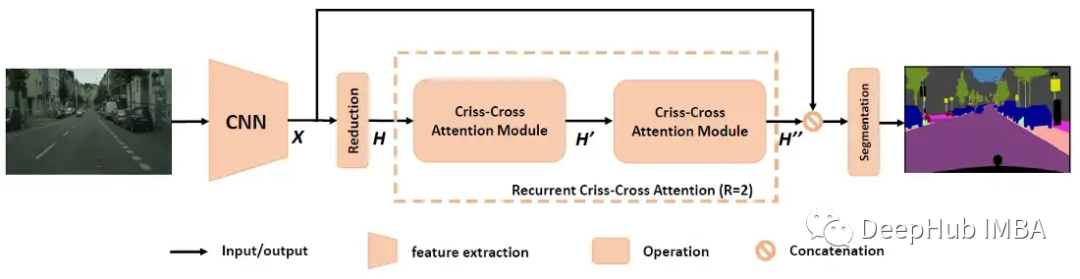
CNN骨干:深度卷积神经网络(DCNN),以全卷积的方式设计,如DeepLabv2,用于生成空间大小为H×W的特征图X。去除最后两个下采样操作,并在后续的卷积层中使用膨胀卷积,从而将输出特征映射的宽度/高度放大X到输入图像的1/8。
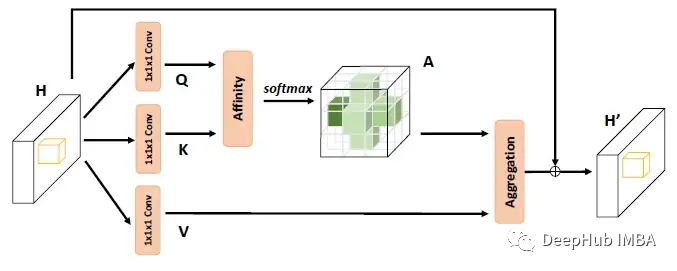
交叉注意力模块
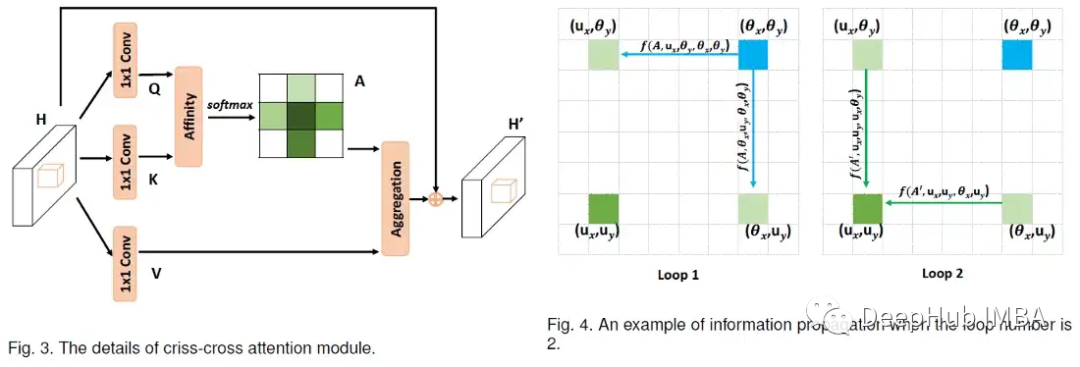
对于输入X,应用卷积层来获得降维的特征图H,然后将特征图H输入到cross -cross attention模块以生成新的特征图H '。
特征图H '仅聚合水平和垂直方向的上下文信息。
为了获得更丰富、更密集的上下文信息,特征图H '会再次输入到交叉注意力模块中,以获得特征图H ’’。特征图H”中的每个位置实际上收集了所有像素的信息。
两个交叉注意力模块在前后共享相同的参数,这样可以避免添加过多的额外参数,它被命名为循环交叉注意力(RCCA)模块。
然后,密集上下文特征H”与局部表示特征x会被连接起来,通过一个或多个卷积层进行批量归一化和激活进行特征融合。最后将融合后的特征送入分割层预测最终的分割结果。
CCNet (2020 TPAMI)
类别一致的特征学习
在TPAMI中,除了分割损失的交叉熵损失lseg之外,还增加了类别一致的损失来驱动RCCA模块直接学习类别一致特征。lvar、ldis、lreg 被用于
- 惩罚每个实例具有相同标签的特征之间的大距离
- 惩罚不同标签的平均特征之间的小距离
- 分别向原点绘制所有类别的平均特征
表示如下
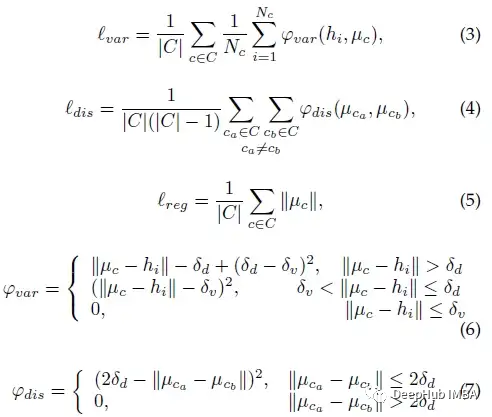
图中设C是类的集合,Nc是属于类C的有效元素个数,hi是空间位置i的特征向量,μc是类C∈C(聚类中心)的均值特征。φ是一个分段距离函数。δv和δd分别为边距。为了减少计算量,首先在RCCA模块的输出上应用一个带有1×1核的卷积层进行降维,然后将这三个损失应用于通道较少的特征图。最终损失l是所有损失的加权和:
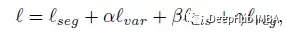
这里的δv= 0.5, δd=1.5, α=β=1, γ=0.001, 16为用于降维的通道数。
3D交叉注意力
3D注意力架构是对2D版本的扩展,它从时间维度收集了更多的上下文信息。
实验结果
Cityscapes数据集
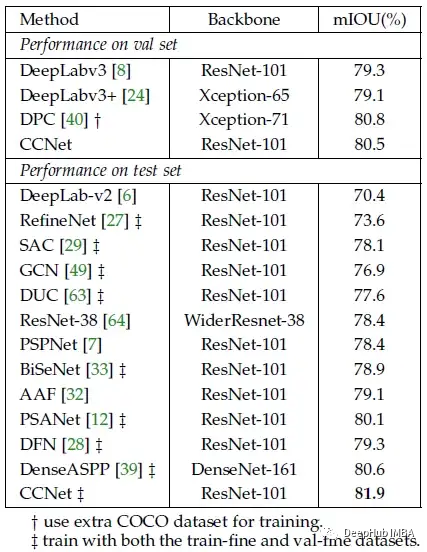
在没有附加特征的情况下,采用单尺度测试的CCNet仍然可以达到相当的性能。
经过训练和验证集的训练,CCNet在测试集上的性能大大优于所有以前的最先进技术。
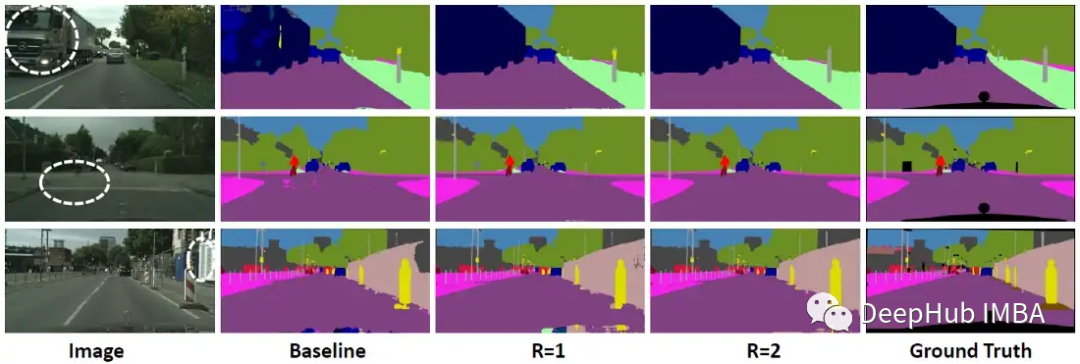
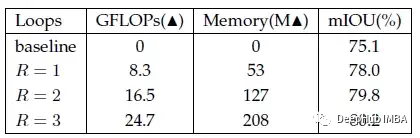
在基线中添加一个交叉注意模块(R=1),性能提高了2.9%。
将循环次数从1次增加到2次可以进一步提高1.8%的性能,证明了密集上下文信息是效性的。将循环从2个增加到3个,略微提高了0.4%的性能。
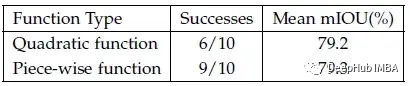
在损失函数中使用分段函数可以获得比单一二次函数稍好的性能。

下图中,“+RCCA”分两步形成密集的上下文信息,后一步可以从第一步生成的特征图中学习到更好的注意力图,因为第一步已经嵌入了一些长期依赖关系。
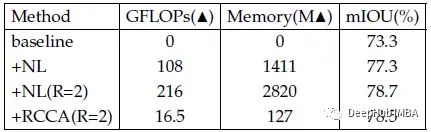
与非局部神经网络中的“+NL”方法相比,论文提出的“+RCCA”方法在计算全图像依赖时,GPU内存占用减少了11倍,FLOPs显著降低了约85%的非局部块。

当R=2时,可以学习到长期依赖关系,而当R=1时则不能。
ADE20K数据集
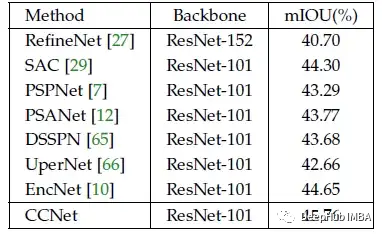
使用CCL的CCNet实现了45.76%的最佳性能,比以前的最先进方法高出1.1%以上,也比会议发布时的CCNet高出0.5%。

添加CCL的效果更好。
LIP数据集
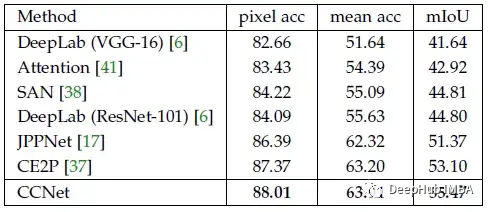
CCNet实现了55.47%的最佳性能,比以前最先进的方法高出2.3%以上。
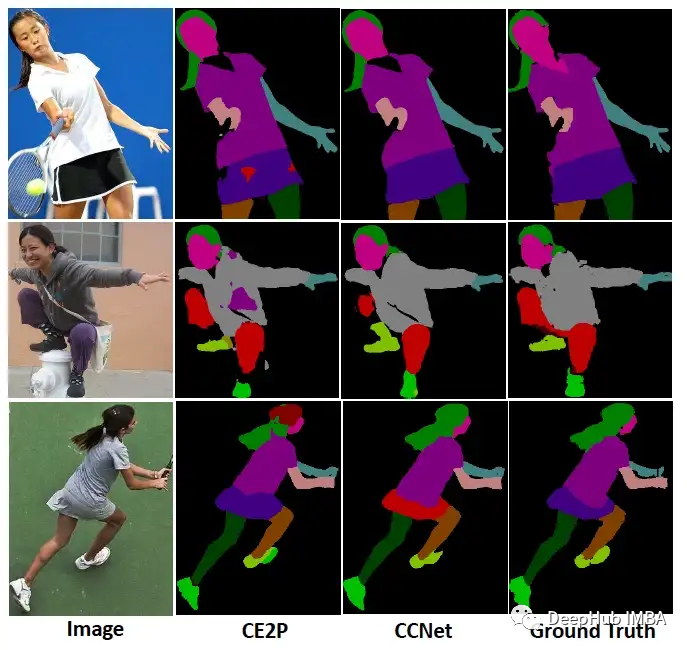
前两行显示了一些成功的分割结果。CCNet可以对复杂的姿态进行准确的分割。第三行显示了一个失败的分割结果,其中“裙子”被错误地分类为“裤子”。
COCO数据集
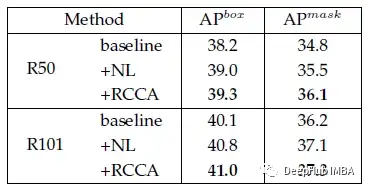
CCNet在所有指标上都大大优于基线。

CamVid数据集
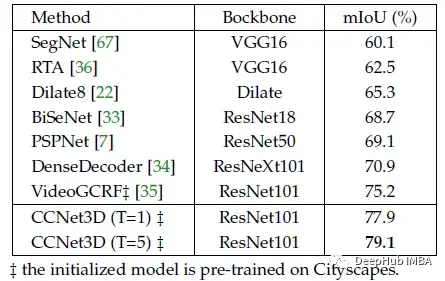
CCNet的3D版本,CCNet3D在CamVid上结果。
CCNet3D实现了79.1%的mIoU,大大超过了所有其他方法。
论文地址
[2019 ICCV] [CCNet]CCNet: Criss-Cross Attention for Semantic Segmentation
[2020 TPAMI] [CCNet]CCNet: Criss-Cross Attention for Semantic Segmentation
作者:Sik-Ho Tsang