
2022年随着聊天GPT和Mid - journey和Dall-E等图像生成器的流行,我们看到了整个人工智能领域的重大进展。在人工智能和计算机科学的时代,这是令人振奋的一年。本文我们总结了在2022年发表的最具开创性的10篇论文,无论如何你都应该看看。

1、Alpha Tensor: Discovering faster matrix multiplication algorithms with reinforcement learning
Fawzi, A., Balog, M., Huang, A. et al. Discovering faster matrix multiplication algorithms with reinforcement learning. Nature 610, 47–53 (2022).
DeepMind 的研究人员开发了一种称为 AlphaTensor 的深度强化学习方法,用于发现高效且准确的矩阵乘法算法。矩阵乘法是一种广泛用于各种系统的基础计算,包括神经网络和科学计算例程。AlphaTensor 能够发现在许多情况下优于当前最先进技术的算法,包括在使用有限域的 4x4 矩阵乘法方面取得的突破性成就。AlphaTensor 的灵活性还通过其发现结构化矩阵乘法算法和针对特定硬件优化矩阵乘法的能力得到证明。AlphaTensor 的潜在应用从矩阵乘法扩展到其他基本计算任务,展示了使用人工智能 (AI) 指导算法发现的潜力。该研究还表明,人工智能可用于解决数学和跨科学领域的重要挑战。
AlphaTesor 的里程碑标志着计算效率的重要性。随着人工智能 (AI) 和数据中心的使用增加,考虑对环境的影响并确保以可持续和负责任的方式开发和使用人工智能非常重要。随着世界越来越多地转向碳中和社会,我们需要减少人工智能系统的能源消耗和碳排放。
2、Stable Diffusion: High-resolution image synthesis with latent diffusion models
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., & Ommer, B. (2022). High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 10684–10695).
MidJourney, Dall-E和Imagen等模型所创造的精美的图片都有一个重要的共同点,它们都依赖于扩散模型。研究人员开发了一种新的图像合成方法,称为 latent diffusion models(ldm),可以在一系列任务中获得最先进的结果。

ldm使用去噪自编码器和扩散模型将形成图像的过程分解为一系列步骤,这允许在不需要重新训练的情况下控制图像生成过程。传统的扩散模型因为需要连续的评估,所以需要大量的计算资源和昂贵的使用,为了解决个问题研究人员在强大的预训练自编码器的潜在空间中应用了扩散模型。这使得他们在复杂性降低和细节保存之间达到了一个近乎最佳的点,极大地提高了视觉保真度。通过在模型架构中引入交叉注意层,ldm可以用于一般的条件输入,如文本或包围框,并可以以卷积方式生成高分辨率图像。ldm在图像修补和类条件图像合成方面取得了最新的成绩,在文本到图像合成、无条件图像生成和超分辨率等任务上具有很强的竞争力,同时与传统的基于像素的扩散模型相比,显著降低了计算需求。
3、LaMDA: Language Models for Dialog Applications
Thoppilan, R., De Freitas, D., Hall, J., Shazeer, N., Kulshreshtha, A., Cheng, H. T., … & Le, Q. (2022). Lamda: Language models for dialog applications. arXiv preprint arXiv:2201.08239.
ChatGPT在互联网上掀起了一场风暴。这是一个聊天机器人,它模仿一对一的对话来回答问题,从能够解决极端问题,或者从哲学角度回答关于生命意义。因为他的内部工作机制的细节还没有公布,所以我不会把ChatGPT包括在这个列表中。但是OpenAI的研究人员已经开发了一个专门用于对话的新神经语言模型,有多达1370亿个参数,被称作LaMDA(对话应用语言模型)。LaMDA使用1.56万亿词的公共对话数据和网络文本进行预训练,使其成为迄今为止最大的语言模型之一。虽然简单地扩展语言模型可以提高其性能,但在提高安全性和事实基础方面效果较差。为了解决这些挑战,研究人员使用带注释的数据对LaMDA进行了微调,并使其能够参考外部知识来源。
开发对话语言模型的主要挑战之一是确保它们的回答符合人类价值观,例如防止有害的建议和不公平的偏见。为了解决这个问题,研究人员使用了一个经过少量注释数据微调的LaMDA分类器来过滤候选响应。这种方法显示出了提高模型安全性的希望。
另一个挑战是使模型能够参考外部知识来源,如信息检索系统或简单的计算器,来生成基于已知事实而不仅仅是听起来似是而非的的响应,研究人员发现他们的方法使LaMDA能够通查询外部知识来源产生更多基于事实的回应。
除了这些技术成就,研究人员还探索了LaMDA在教育和内容推荐领域的使用,分析了它在这些领域的帮助和角色一致性。总的来说,LaMDA的发展代表了自然语言处理领域的重大进步,并有潜力改进广泛的基于对话的应用程序。
4、A ConvNet for the 2020s
Liu, Z., Mao, H., Wu, C. Y., Feichtenhofer, C., Darrell, T., & Xie, S. (2022). A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 11976–11986).
在过去的十年里,随着ViTs的引入,视觉识别领域发生了重大变化。虽然普通vit在一般计算机视觉任务(如对象检测和语义分割)方面取得了一些成功,但真正在这些领域产生影响的是分层 Transformer,例如 Swin Transformers。但是这些混合方法的有效性通常归因于 Transformer 的优越性,而不是卷积固有的归纳偏差。
在最近的一项研究中,研究人员着手测试纯 ConvNet 所能达到的极限。他们逐渐对标准 ResNet 进行“现代化”以靠近Transformer,并发现了导致两者性能差异的几个关键组件。这种探索的结果是称为 ConvNeXts 的纯 ConvNet 模型系列。ConvNeXts 完全由标准的 ConvNet 模块构建而成,能够在准确性和可扩展性方面与 Transformers 相媲美,并且保持了标准 ConvNet 的简单性和效率。
5、OpenAI Whisper: Robust Speech Recognition via Large-Scale Weak Supervision
Radford, A., Kim, J. W., Xu, T., Brockman, G., McLeavey, C., & Sutskever, I. (2022). Robust speech recognition via large-scale weak supervision. arXiv preprint arXiv:2212.04356.
Whisper 是 OpenAI 的开源的用于转录的AI 模型。它是一种基于 Transformer 架构的大规模音频模型,使用从网络收集的超过 600,000 小时的多语言和多任务监督数据进行了训练。模型能够以30秒为单位处理音频记录,并使用编码器部分对音频进行编码,然后由解码器使用该部分来预测正在说的标记或单个单词。解码器使用这一编码信息,以及预测的前一个单词,来猜测下一个最有意义的单词。
Whisper 的主要优势之一是它的稳健性,它使用了各种数据集进行训练,包括剪辑、TED 演讲、播客和访谈。虽然其中一些数据是使用机器学习模型转录的(这可能会引入错误),但也有助于模型更好地处理实际的场景。虽然 Whisper 可能不是针对特定任务的最强大模型,但可以使用其他数据对其进行微调,以提高其在特定任务上的性能。事实证明,微调像 Whisper 这样的预训练模型比在特定任务上从头开始训练模型产生更好的结果。
6、Gato DeepMind: General AI
Reed, S. et al. (2022). A Generalist Agent. DeepMind
DeepMind开发了一种名为Gato的的多模态模型,它利用基于 Transformer 的架构来执行各种任务。Gato能够处理广泛的输入,包括文本、图像和机械臂的扭矩数据,并产生一系列输出,包括可理解的文本、扭矩功率和按钮按下。这意味着Gato可以用于执行广泛的任务,包括语言翻译和图像字幕,甚至可以玩雅达利游戏,它可以执行604种不同的任务。Gato的主要优势之一是它的多功能性。Gato不需要为不同的任务训练和集成多个专门的模型,而是可以用一组权重和一个相对简单的架构处理所有这些任务。这使得它比以前的方法更高效、更经济,因为以前的方法通常需要开发多个专门的模型。
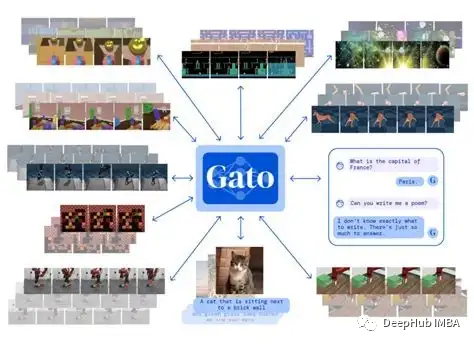
Gato的发展代表着通用人工智能发展迈出了重要一步。它特别强调了多模态方法的潜力,包括集成多种类型的数据,以提高学习和性能。像Gato这样的模型在提取见解和解决复杂问题方面将变得越来越重要。但是Gato还是有其局限性。因为它不是一种纯粹的多任务模型方法,与单任务模型相比,它的性能有限。
7、Bootstrapped Meta-Learning
Flennerhag, S., Schroecker, Y., Zahavy, T., van Hasselt, H., Silver, D., & Singh, S. (2021). Bootstrapped meta-learning. arXiv preprint arXiv:2109.04504.
在这篇论文中,研究人员提出了一种新的算法,允许人工智能系统通过称为元学习的过程学习如何更有效地学习。这个过程包括克服一个称为元优化的困难优化问题。这种被称为自举的新算法通过允许人工智能系统自我学习来解决这个问题。该算法首先为AI系统创建一个目标,然后通过最小化系统与目标之间的距离来优化系统。
研究人员专注于在元学习中使用梯度,并建立确保性能提高的条件。他们还发现所选择的度量可以控制元优化,并且自举机制可以有效扩展元学习范围,而不需要通过所有更新进行反向传播。这种算法能够在雅达利ALE基准上实现新的最先进的无模型代理。他们还证明了该算法可以在多任务元学习中提高性能和效率。
研究人员探索了如何在元学习中开辟新的可能性,并发现无需通过更新规则进行反向传播就可以在epsilon-greedy Q-learning agent中进行元学习的高效探索。这种新算法有可能通过元学习显著提高人工智能系统的效率。
8、Tabular Data: Deep Learning is Not All You Need
Shwartz-Ziv, R., & Armon, A. (2022). Tabular data: Deep learning is not all you need. Information Fusion, 81, 84–90.
这篇论文比较了树集成模型XGBoost与几种深度学习模型在不同表格数据集上的分类和回归任务性能。结果表明,XGBoost的表现始终优于深度学习模型,包括之前声称深度模型性能优越的论文中使用的那些模型。该研究发现XGBoost需要的调优比深度学习模型要少得多。XGBoost和深度学习模型的集成在数据集上的表现比单独XGBoost更好。这些发现表明,XGBoost仍应被视为数据科学项目中表格数据的首选。并强调人工智能并不局限于深度学习,而是有不同的解决方案。
9、Imagen Video: High Definition Video Generation with Diffusion Models
Ho, J., Chan, W., Saharia, C., Whang, J., Gao, R., Gritsenko, A., … & Salimans, T. (2022). Imagen video: High definition video generation with diffusion models. arXiv preprint arXiv:2210.02303.
一种名为 Imagen Video 的新型文本条件视频生成系统使用基础视频生成模型和一系列交错的空间和时间视频超分辨率模型,可以根据给定的文本提示生成高清视频。该系统可扩展为文本到高清视频模型,它利用各种分辨率的全卷积时间和空间超分辨率模型以及扩散模型的 v 参数化。研究人员还将渐进式蒸馏应用于视频模型,可以在不使用分类器的情况下进行快速和高质量的采样。Imagen Video 不仅可以生成高保真度的视频,还具有高度的可控性和世界知识,包括生成各种艺术风格和 3D 对象理解的多样化视频和文本动画的能力。
10、 A Path Towards Autonomous Machine Intelligence Version 0.9.2
LeCun, Y. (2022). A path towards autonomous machine intelligence version 0.9. 2, 2022–06–27. Open Review, 62.
研究人员提出了一种用于创建智能机器的新架构和训练范式。该论文概述了构建自主智能代理的潜在解决方案,这些代理可以以类似于人类和动物的方式学习和推理。所提出的架构包括一个可配置的预测世界模型和由内在动机驱动的动作行为,利用经过自我监督学习训练的分层联合嵌入。目标是使机器能够在多个抽象层次上学习感知和行动计划的表示,使它们能够在多个时间范围内进行推理、预测和计划。
作者:C.J. Pongajow